
Предыдущая статья — Python AI в StarCraft II. Часть X: строим модель нейронной сети.
Добро пожаловать в одиннадцатую часть серии статей про использование искусственного интеллекта в игре Starcraft II. В данной статье мы будем работать на передачей данных в нашу нейронную сеть. Поскольку данных у нас сравнительно много, для их передачи придется приложить дополнительные усилия.
Для начала заметим, что в Keras есть механизм разбития обучения на эпохи. (Эпохой в машинном обучении называется итерация, в процессе которой через нейронную сеть проходит весь датасет. Так как данные в датасете зачастую слишком велики, их делят на батчи, — прим. переводчика.)
Итак, начнем с того, что зададим количество эпох равным 10. Мы всегда можем продолжить обучение уже предобученной модели, поэтому если 10 нам покажется мало, мы всегда сможем добавить абсолютно любое количество эпох.
hm_epochs = 10 for i in range(hm_epochs):
Отсюда видно, что мы собираемся итерировать некий блок кода ровно 10 раз. В нем мы будем перебирать все наши учебные данные, загружая их из разных файлов, и обучать таким образом нашу нейронную сеть. Каждый из этих файлов представляет ровно одну игру, в которой наш случайный AI победил сильный AI компьютера (случайный — потому что из 4 возможностей атаки выбор осуществлялся случайным образом).
Далее мы начнем обучение, однако сперва нам нужно гарантировать отсутствие проблем с памятью:
for i in range(hm_epochs):
current = 0
increment = 200
not_maximum = True
Мы будем дробить наши данные на части следующим образом: возьмем список всех наших файлов (os.listdir) и будем нарезать его кусками по 200 штук.
all_files = os.listdir(train_data_dir)
maximum = len(all_files)
random.shuffle(all_files)
Для окончания итераций задана максимальная длина нашего списка. Определенно есть лучший способ задать такую логику, однако на данный момент мы написали вот так.(Конечно, есть лучший способ! Для разбития данных на батчи, например, часто используют библиотеку scikit-learn, — примечание переводчика).
Теперь нам нужно обеспечить сбалансированную подачу данных в нейронную сеть:
while not_maximum:
print("WORKING ON {}:{}".format(current, current+increment))
no_attacks = []
attack_closest_to_nexus = []
attack_enemy_structures = []
attack_enemy_start = []
for file in all_files[current:current+increment]:
full_path = os.path.join(train_data_dir, file)
data = np.load(full_path)
data = list(data)
for d in data:
choice = np.argmax(d[0])
if choice == 0:
no_attacks.append([d[0], d[1]])
elif choice == 1:
attack_closest_to_nexus.append([d[0], d[1]])
elif choice == 2:
attack_enemy_structures.append([d[0], d[1]])
elif choice == 3:
attack_enemy_start.append([d[0], d[1]])
Для балансировки наших данных нам нужно, чтобы у каждого варианта было одинаковое количество примеров игр.
lengths = check_data()
Создадим для этого функцию check_data():
def check_data():
choices = {"no_attacks": no_attacks,
"attack_closest_to_nexus": attack_closest_to_nexus,
"attack_enemy_structures": attack_enemy_structures,
"attack_enemy_start": attack_enemy_start}
total_data = 0
lengths = []
for choice in choices:
print("Length of {} is: {}".format(choice, len(choices[choice])))
total_data += len(choices[choice])
lengths.append(len(choices[choice]))
print("Total data length now is:",total_data)
return lengths
Опять же, здесь приведен не самый лучший способ сделать это (ссылки на списки вместо их передачи). Получив значения длины всех списков с различными вариантами атаки (они сами сохраняются в список lengths), мы определяем наименьшую из них, и после перетасовки подгоняем все списки под нее.
lowest_data = min(lengths)
random.shuffle(no_attacks)
random.shuffle(attack_closest_to_nexus)
random.shuffle(attack_enemy_structures)
random.shuffle(attack_enemy_start)
no_attacks = no_attacks[:lowest_data]
attack_closest_to_nexus = attack_closest_to_nexus[:lowest_data]
attack_enemy_structures = attack_enemy_structures[:lowest_data]
attack_enemy_start = attack_enemy_start[:lowest_data]
check_data()
Чтобы не запутаться, приведем весь код, который мы сейчас написали:
import keras # Keras 2.1.2 and TF-GPU 1.8.0
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.callbacks import TensorBoard
import numpy as np
import os
import random
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=(176, 200, 3),
activation='relu'))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), padding='same',
activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), padding='same',
activation='relu'))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4, activation='softmax'))
learning_rate = 0.0001
opt = keras.optimizers.adam(lr=learning_rate, decay=1e-6)
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
tensorboard = TensorBoard(log_dir="logs/STAGE1")
train_data_dir = "train_data"
def check_data():
choices = {"no_attacks": no_attacks,
"attack_closest_to_nexus": attack_closest_to_nexus,
"attack_enemy_structures": attack_enemy_structures,
"attack_enemy_start": attack_enemy_start}
total_data = 0
lengths = []
for choice in choices:
print("Length of {} is: {}".format(choice, len(choices[choice])))
total_data += len(choices[choice])
lengths.append(len(choices[choice]))
print("Total data length now is:",total_data)
return lengths
# if you want to load in a previously trained model
# that you want to further train:
# keras.models.load_model(filepath)
hm_epochs = 10
for i in range(hm_epochs):
current = 0
increment = 200
not_maximum = True
all_files = os.listdir(train_data_dir)
maximum = len(all_files)
random.shuffle(all_files)
while not_maximum:
print("WORKING ON {}:{}".format(current, current+increment))
no_attacks = []
attack_closest_to_nexus = []
attack_enemy_structures = []
attack_enemy_start = []
for file in all_files[current:current+increment]:
full_path = os.path.join(train_data_dir, file)
data = np.load(full_path)
data = list(data)
for d in data:
choice = np.argmax(d[0])
if choice == 0:
no_attacks.append([d[0], d[1]])
elif choice == 1:
attack_closest_to_nexus.append([d[0], d[1]])
elif choice == 2:
attack_enemy_structures.append([d[0], d[1]])
elif choice == 3:
attack_enemy_start.append([d[0], d[1]])
lengths = check_data()
lowest_data = min(lengths)
random.shuffle(no_attacks)
random.shuffle(attack_closest_to_nexus)
random.shuffle(attack_enemy_structures)
random.shuffle(attack_enemy_start)
no_attacks = no_attacks[:lowest_data]
attack_closest_to_nexus = attack_closest_to_nexus[:lowest_data]
attack_enemy_structures = attack_enemy_structures[:lowest_data]
attack_enemy_start = attack_enemy_start[:lowest_data]
check_data()
[machinelearning_ad_block]
Продолжаем дальше. Теперь мы хотим объединить все варианты в один большой список:
train_data = no_attacks + attack_closest_to_nexus + attack_enemy_structures + attack_enemy_start
Теперь еще раз перемешаем наш список, чтобы сеть не отдавала предпочтение последним элементам:
random.shuffle(train_data)
print(len(train_data))
Теперь у нас есть подготовленные данные, давайте их вводить:
test_size = 100
batch_size = 128
Для тестовой выборки мы зарезервируем (после перемешивания, конечно) 100 элементов списка, а размер батча установим равным 128. Давайте окончательно сформируем и отформатируем наши данные:
x_train = np.array([i[1] for i in train_data[:-test_size]]).reshape(-1, 176, 200, 3)
y_train = np.array([i[0] for i in train_data[:-test_size]])
x_test = np.array([i[1] for i in train_data[-test_size:]]).reshape(-1, 176, 200, 3)
y_test = np.array([i[0] for i in train_data[-test_size:]])
Обучим нашу модель на этих данных:
model.fit(x_train, y_train,
batch_size=batch_size,
validation_data=(x_test, y_test),
shuffle=True,
verbose=1, callbacks=[tensorboard])
Сохраним модель и продолжим итерацию:
model.save("BasicCNN-{}-epochs-{}-LR-STAGE1".format(hm_epochs, learning_rate))
current += increment
if current > maximum:
not_maximum = False
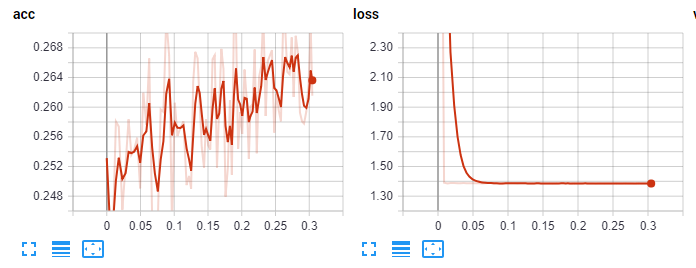
Запустив это, мы начали с примерно 6000 вариантов, что соответствует приблизительно 200 играм, — и никакого обучения вообще не произошло. Тогда мы увеличили количество вариантов до 110K, и дело немного сдвинулось.
Первоначальные данные Tensorboard:
Увеличенные:
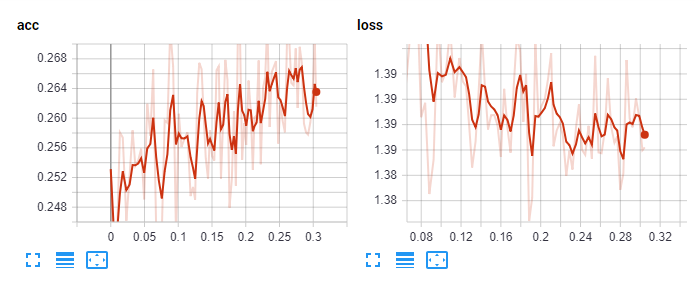
На этом моменте мы стали пробовать разное количество слоев, разный коэффициент скорости обучения, разные оптимайзеры (в приведённом коде — опттимайзер Adam), разные функции активации. Но толку никакого не было, лучше не становилось. Что ж, тогда прогоним все 10 эпох и будем надеяться на продолжение обучения.
После прохождения 10 эпох (200 файлов за раз, размер батча 128, lr = 1e-4) результат следующий:

Отлично! На этом моменте мы подключили тариф Volta 100 на сайте PaperSpace и дела пошли быстрее.
В окончательном виде обученную модель можно загрузить отсюда.
Ее статистика имеет следующий вид:
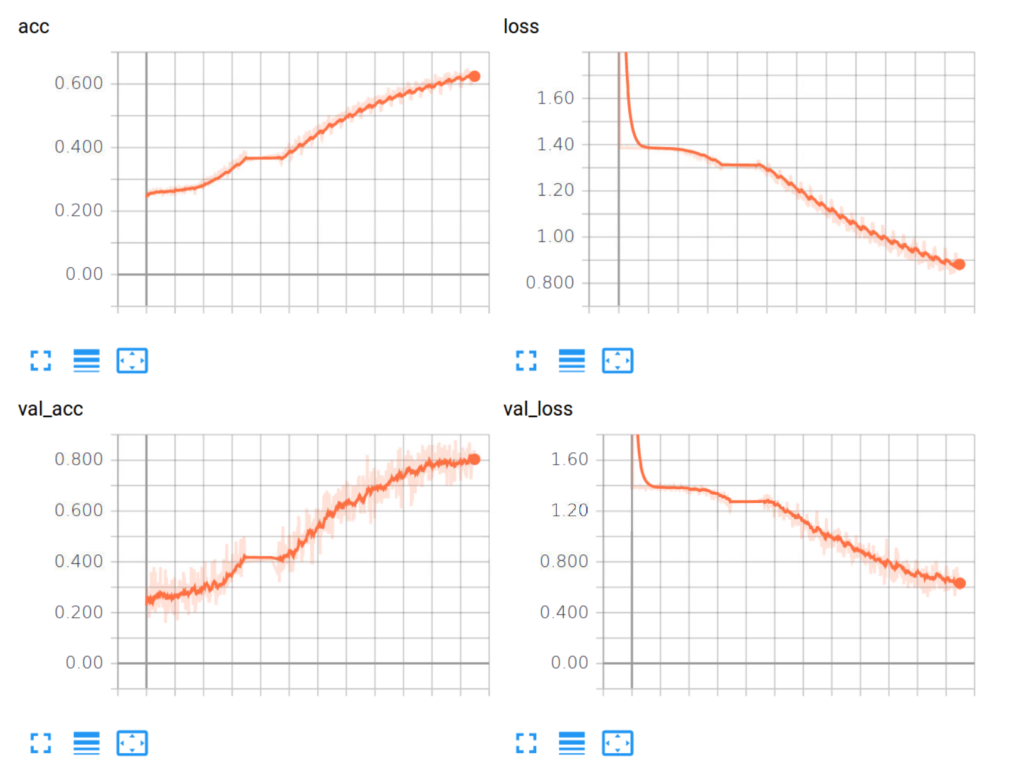
Выглядит неплохо. Посмотрим в следующей статье, как это работает.
А весь наш код сейчас выглядит вот так:
import keras # Keras 2.1.2 and TF-GPU 1.9.0
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.callbacks import TensorBoard
import numpy as np
import os
import random
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=(176, 200, 3),
activation='relu'))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), padding='same',
activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), padding='same',
activation='relu'))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4, activation='softmax'))
learning_rate = 0.0001
opt = keras.optimizers.adam(lr=learning_rate, decay=1e-6)
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
tensorboard = TensorBoard(log_dir="logs/STAGE1")
train_data_dir = "train_data"
def check_data():
choices = {"no_attacks": no_attacks,
"attack_closest_to_nexus": attack_closest_to_nexus,
"attack_enemy_structures": attack_enemy_structures,
"attack_enemy_start": attack_enemy_start}
total_data = 0
lengths = []
for choice in choices:
print("Length of {} is: {}".format(choice, len(choices[choice])))
total_data += len(choices[choice])
lengths.append(len(choices[choice]))
print("Total data length now is:", total_data)
return lengths
hm_epochs = 10
for i in range(hm_epochs):
current = 0
increment = 200
not_maximum = True
all_files = os.listdir(train_data_dir)
maximum = len(all_files)
random.shuffle(all_files)
while not_maximum:
print("WORKING ON {}:{}".format(current, current+increment))
no_attacks = []
attack_closest_to_nexus = []
attack_enemy_structures = []
attack_enemy_start = []
for file in all_files[current:current+increment]:
full_path = os.path.join(train_data_dir, file)
data = np.load(full_path)
data = list(data)
for d in data:
choice = np.argmax(d[0])
if choice == 0:
no_attacks.append([d[0], d[1]])
elif choice == 1:
attack_closest_to_nexus.append([d[0], d[1]])
elif choice == 2:
attack_enemy_structures.append([d[0], d[1]])
elif choice == 3:
attack_enemy_start.append([d[0], d[1]])
lengths = check_data()
lowest_data = min(lengths)
random.shuffle(no_attacks)
random.shuffle(attack_closest_to_nexus)
random.shuffle(attack_enemy_structures)
random.shuffle(attack_enemy_start)
no_attacks = no_attacks[:lowest_data]
attack_closest_to_nexus = attack_closest_to_nexus[:lowest_data]
attack_enemy_structures = attack_enemy_structures[:lowest_data]
attack_enemy_start = attack_enemy_start[:lowest_data]
check_data()
train_data = no_attacks + attack_closest_to_nexus + attack_enemy_structures + attack_enemy_start
random.shuffle(train_data)
print(len(train_data))
test_size = 100
batch_size = 128
x_train = np.array([i[1] for i in train_data[:-test_size]]).reshape(-1, 176, 200, 3)
y_train = np.array([i[0] for i in train_data[:-test_size]])
x_test = np.array([i[1] for i in train_data[-test_size:]]).reshape(-1, 176, 200, 3)
y_test = np.array([i[0] for i in train_data[-test_size:]])
model.fit(x_train, y_train,
batch_size=batch_size,
validation_data=(x_test, y_test),
shuffle=True,
verbose=1, callbacks=[tensorboard])
model.save("BasicCNN-{}-epochs-{}-LR-STAGE1".format(hm_epochs, learning_rate))
current += increment
if current > maximum:
not_maximum = False
Следующая статья — Python AI в StarCraft II. Часть XII: используем нейросетевую модель.
