В этом руководстве мы рассмотрим, как развернуть модель машинного обучения (ML) на AWS Lambda с помощью Serverless Framework и выполнить ее с помощью Boto3. Мы также создадим CI/CD-конвейер с помощью GitHub Actions для автоматизации процесса развертывания и запуска сквозных тестов.
Друзья, подписывайтесь на наш телеграм канал Pythonist. Там еще больше туториалов, задач и книг по Python.
Содержание
- Настройка проекта
- Обработчик AWS Lambda
- Serverless Framework
- Dockerfile
- Развертывание с помощью GitHub Actions
- Учетные данные AWS
- Конечное тестирование
- Заключение
Настройка проекта
Игра с ML-моделями на локальной машине может быть интересной. Тем не менее, в конце концов необходимо где-то развернуть модель, чтобы она могла использоваться в продукте.
Вариантов развертывания существует множество. AWS Lambda — это отличный выбор для тех случаев, когда у вас скачкообразный трафик или когда он редко используется.
Кроме того, AWS Lambda позволяет легко выполнять операции ML параллельно. Вы просто вызываете свою функцию Lambda с помощью Boto3 из кода, которому требуется функциональность ML.
Итак, давайте построим ML-сервис для выполнения анализа тональности текста.
Начнем с создания нового проекта:
$ mkdir ml_lambda && cd ml_lambda && git init $ python3.11 -m venv venv $ source venv/bin/activate (venv)$
Создайте новый файл .gitignore. Затем добавьте в него содержимое шаблона. Добавьте .gitignore в git и сделайте коммит:
$ git add .gitignore<br>$ git commit -m 'Initial commit'
После этого добавьте PyTorch и Transformers в файл requirements.txt:
torch==2.0.1 transformers==4.31.0
Установите их:
(venv)$ pip install -r requirements.txt
Затем создайте новый модуль sentiment_model.py:
from transformers import pipeline
class SentimentModel:
def __init__(self):
self._sentiment_analysis = pipeline("sentiment-analysis",model="ProsusAI/finbert")
def predict(self, text):
return self._sentiment_analysis(text)[0]["label"]
В данном случае мы использовали предварительно обученную модель обработки естественного языка (NLP) FinBERT, предназначенную для анализа тональности настроения в финансовых текстах.
Хотите протестировать ее на месте? Добавьте в нижнюю часть модуля следующее:
if __name__ == "__main__":
sample_text = "The Dow Jones Industrial Average (^DJI) turned green."
model = SentimentModel()
sentiment = model.predict(text=sample_text)
print(sentiment)
Затем запустите файл. Попробуйте использовать различные примеры текста. Не забудьте удалить блок if после выполнения.
Наконец, создайте новый проект на GitHub и обновите git remote.
Обработчик AWS Lambda
AWS Lambda — это сервис бессерверных вычислений, на котором вы можете выполнять свой код. Вместо традиционных предложений по развертыванию, где вы «арендуете» место на сервере, вы платите только за фактическое время выполнения. Поэтому это отличный выбор, если у вас небольшой трафик, который скачет время от времени.
Запуск Python-кода на AWS Lambda достаточно прост. Необходимо указать функцию-обработчик и направить на нее Lambda. Вот как должна выглядеть ожидаемая сигнатура для функции-обработчика:
def handle(event, context):
...
Создайте новый модуль с именем handler.py:
import logging
from sentiment_model import SentimentModel
LOGGER = logging.getLogger()
LOGGER.setLevel(logging.INFO)
model = SentimentModel()
def handle(event, context):
if event.get("source") == "KEEP_LAMBDA_WARM":
LOGGER.info("No ML work to do. Just staying warm...")
return "Keeping Lambda warm"
return {
"sentiment": model.predict(text=event["text"])
}
Что же здесь происходит?
Во-первых, вне функции handle мы настроили логгер и инициализировали нашу модель. Код, написанный вне функции handle, выполняется только во время холодного старта Lambda.
Для холодного запуска Lambda должна:
- Найти место на экземпляре EC2
- Инициализировать среду выполнения
- Инициализировать модуль
Холодные старты необходимы после повторного развертывания и в тех случаях, когда Lambda не используется в течение некоторого времени.
AWS не раскрывает точное количество времени, в течение которого Lambda будет оставаться прогретой. Тем не менее, если поискать в Интернете, можно найти время от пяти до пятнадцати минут.
Поскольку холодный запуск Lambda занимает несколько секунд, часто возникает желание держать Lambda в прогретом состоянии. Для этого мы будем использовать отдельную функцию Lambda, которая будет периодически пинговать нашу Lambda для поддержания ее в нужном состоянии.
Поскольку вы, опять же, платите за время выполнения, мы не хотим выполнять полную ML-модель, когда мы просто пытаемся поддерживать ее в прогретом состоянии, поэтому мы добавили следующий блок if:
if event.get("source") == "KEEP_LAMBDA_WARM":
LOGGER.info("No ML work to do. Just staying warm...")
return "Keeping Lambda warm"
Чтобы узнать больше о холодных запусках, ознакомьтесь со средами выполнения Lambda из документации.
Serverless Framework
Для развертывания нашей функции Lambda мы будем использовать Serverless Framework. Он помогает легко разрабатывать и развертывать бессерверные приложения.
Для нашего случая Serverless Framework прост в использовании. Нам нужно создать конфигурационный файл serverless.yml. Он укажет фреймворку, какие ресурсы бессерверного облака нужно создать и как вызывать наше приложение, работающее на них.
Фреймворк поддерживает множество облачных провайдеров, таких как AWS, Google Cloud, Azure и др.
Настоятельно рекомендуем ознакомиться с проектом Your First Serverless Framework Project, прежде чем продолжать работу над этим проектом, чтобы иметь представление о работе Serverless Framework.
Добавьте новый файл конфигурации serverless.yml:
service: ml-model
frameworkVersion: '3'
useDotenv: true
provider:
name: aws
region: ${opt:region, 'eu-west-1'}
stage: ${opt:stage, 'development'}
logRetentionInDays: 30
ecr:
images:
appimage:
path: ./
functions:
ml_model:
image:
name: appimage
timeout: 90
memorySize: 4096
environment:
TORCH_HOME: /tmp/.ml_cache
TRANSFORMERS_CACHE: /tmp/.ml_cache/huggingface
custom:
warmup:
MLModelWarmer:
enabled: true
events:
- schedule: rate(4 minutes)
concurrency: ${env:WARMER_CONCURRENCY, 2}
verbose: false
timeout: 100
payload:
source: KEEP_LAMBDA_WARM
plugins:
- serverless-plugin-warmup
В этом файле происходит довольно много событий.
Во-первых, мы определили имя нашего сервиса:
service: ml-model
Во-вторых, мы определили некоторые глобальные настройки:
frameworkVersion: '3'
frameworkVersion используется для привязки конкретной версии Serverless Framework.
В-третьих, мы настроили провайдер:
provider:
name: aws
region: ${opt:region, 'eu-west-1'}
stage: ${opt:stage, 'development'}
logRetentionInDays: 30
ecr:
images:
appimage:
path: ./
Мы установили значения по умолчанию для региона и стадии — Ireland (eu-west-1) и development соответственно. opt:region и opt:stage могут быть прочитаны из командной строки. Например:
$ serverless deploy --region us-east-1 --stage production
Далее мы установили дни хранения логов таким образом, что все логи в CloudWatch от нашего приложения будут удаляться через тридцать дней. В конце мы определили, что для развертывания нашей ML-модели мы будем использовать образ Docker. Он будет создан по пути ./ и храниться внутри ECR.
В-четвертых, мы определили нашу Lambda-функцию:
functions:
ml_model:
image:
name: appimage
timeout: 90
memorySize: 4096
environment:
TORCH_HOME: /tmp/.ml_cache
TRANSFORMERS_CACHE: /tmp/.ml_cache/huggingface
Поскольку мы используем провайдера AWS, все заданные функции будут являться функциями AWS Lambda.
Мы указали, какой Docker-образ будет использоваться. Затем мы задали ограничения по таймауту и памяти. В завершение определения функции мы задали папки, доступные для записи, для библиотек PyTorch и HuggingFace. Эти библиотеки будут загружать некоторые файлы. Поэтому место назначения должно быть доступно для записи. Мы использовали для этого папку «/tmp», которая является единственной папкой, доступной для записи на AWS Lambda.
С помощью ML-библиотек, таких как PyTorch и HuggingFace, можно использовать предварительно обученные модели (что мы и делаем). Эти модели загружаются из Интернета и хранятся на диске — для их кэширования. Таким образом, не нужно загружать их каждый раз, когда выполняется код.
Библиотеки всегда проверяют, могут ли они сначала загрузить модель из локального кэша. Если ее там нет, то она загружается. При этом используются настройки по умолчанию для расположения кэша.
В Lambda местоположение по умолчанию недоступно для записи. Только папка «/tmp» является доступной для записи. Поэтому нам необходимо установить расположение кэша внутри «/tmp». Чтобы четко указать, что это место назначения является местом назначения кэша для ML-моделей, мы назвали его «.ml_cache».
Задав переменные окружения TORCH_HOME и TRANSFORMERS_CACHE, мы указали для наших библиотек место для кэширования. Не стесняйтесь переименовать место назначения по своему усмотрению.
Мы используем 90 секунд для таймаута, поскольку модель должна быть загружена, а это может занять некоторое время.
В-пятых, мы задали конфигурацию для подогревателя нашей Lambda, который является просто еще одной Lambda, чтобы поддерживать нашу основную Lambda в прогретом состоянии:
custom:
warmup:
MLModelWarmer:
enabled: true
name: ${self:service}-${self:provider.stage}-warmer
roleName: ${self:service}-${self:provider.stage}-warmer-role
events:
- schedule: rate(4 minutes)
concurrency: ${env:WARMER_CONCURRENCY, 2}
verbose: false
timeout: 100
payload:
source: KEEP_LAMBDA_WARM
plugins:
- serverless-plugin-warmup
Здесь мы использовали плагин serverless-plugin-warmup. Обратите внимание на payload:
{ "source": "KEEP_LAMBDA_WARM" }
Добавьте также следующий файл package.json для установки serverless-plugin-warmup:
{
"name": "ml-model",
"version": "1.0.0",
"description": "",
"main": "index.js",
"dependencies": {},
"devDependencies": {
"serverless-plugin-warmup": "8.2.1"
},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
Dockerfile
Единственное, что осталось до развертывания, — это наш Dockerfile:
###########
# BUILDER #
###########
FROM public.ecr.aws/lambda/python:3.10 as builder
RUN pip3 install --upgrade pip
COPY requirements.txt .
RUN pip3 install -r requirements.txt --target "${LAMBDA_TASK_ROOT}"
#########
# FINAL #
#########
FROM public.ecr.aws/lambda/python:3.10
RUN pip3 install --upgrade pip
COPY --from=builder ${LAMBDA_TASK_ROOT} ${LAMBDA_TASK_ROOT}
COPY . ${LAMBDA_TASK_ROOT}
CMD [ "handler.handle" ]
Мы использовали базовый образ для Lambda, предоставляемый AWS. Образ собирается в два этапа, чтобы конечный размер образа был минимальным. В конце мы указали, какая функция будет вызываться при обращении к Lambda.
Теперь каталог вашего проекта должен выглядеть следующим образом:
├── Dockerfile ├── handler.py ├── package.json ├── requirements.txt ├── sentiment_model.py └── serverless.yml
Развертывание с помощью GitHub Actions
Поскольку мы являемся настоящими профессионалами, то для развертывания нашей функции Lambda мы будем использовать GitHub Actions. Для этого нам сначала нужно добавить конфигурацию CI/CD.
Создайте следующий файл и папки:
└── .github └── workflows └── lambda.yml
Затем добавьте конфигурацию CI/CD в файл .github/workflows/lambda.yml:
name: ML Lambda Deploy
on:
push:
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_DEFAULT_REGION: eu-west-1
jobs:
deploy-development:
strategy:
fail-fast: false
matrix:
python-version: ['3.10']
node-version: [18]
os: [ubuntu-latest]
runs-on: ${{ matrix.os }}
steps:
- name: Checkout Code
uses: actions/checkout@v3
- name: Set up Python 3.10
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
- name: Install Serverless Framework
run: npm install -g serverless
- name: Install NPM dependencies
run: npm install
- name: Deploy
run: sls deploy --stage development --verbose
Внутри вновь добавленного задания deploy-development мы:
- Подготовили базовое окружение, установив Python и Node.
- Установили Serverless Framework в качестве глобальной зависимости — так мы сможем выполнять
sls-команды. - Установили зависимости из package.json — на данный момент это только плагин serverless-plugin-warmup.
- Развернули наше приложение, выполнив команду
sls deploy --stage development --verbose.
Можно попробовать развернуть непосредственно с компьютера на AWS, выполнив npm install и serverless deploy --stage development внутри «services/tasks_api». Для этого необходимо установить Serverless Framework, а также npm и Node.js. Также необходимо установить учетные данные AWS.
Учетные данные AWS
Прежде чем выполнять коммит и push, необходимо добавить учетные данные AWS на GitHub. Если у вас еще нет учетной записи AWS, создайте ее из консоли AWS.
Сначала откройте консоль IAM. Затем нажмите кнопку «Add user». Введите github в качестве имени пользователя. Нажмите кнопку «Next».
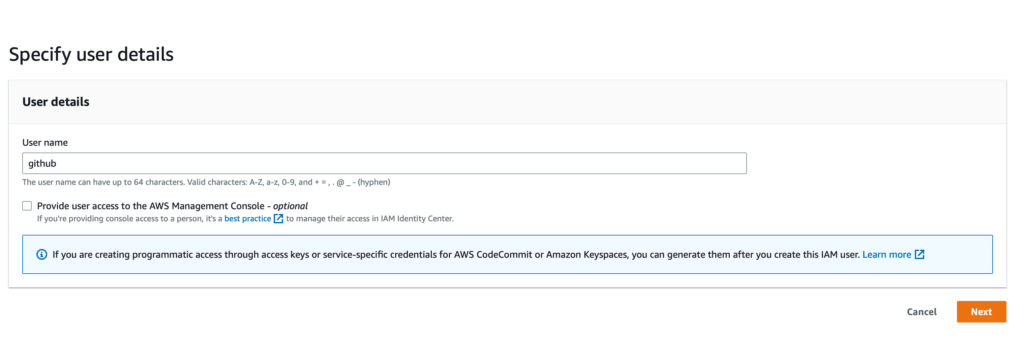
На следующем шаге выберите «Attach policies directly» и выберите «AdministratorAccess».
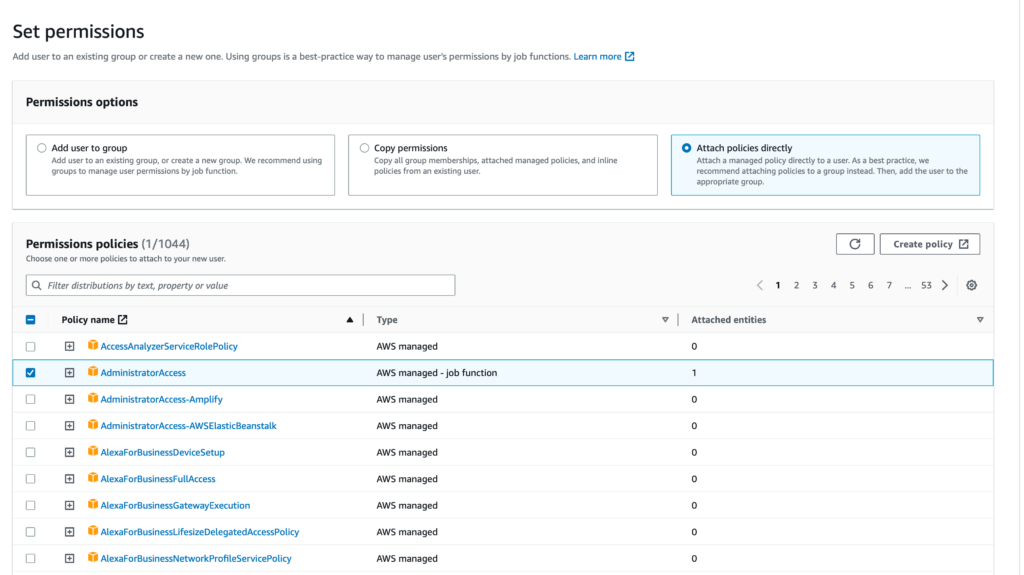
Нажмите кнопку «Next» и затем «Create user». После того как пользователь будет создан (он появится в списке пользователей), щелкните на нем, чтобы открыть его данные. Затем перейдите на вкладку «Учетные данные безопасности» и нажмите кнопку «Create access key».
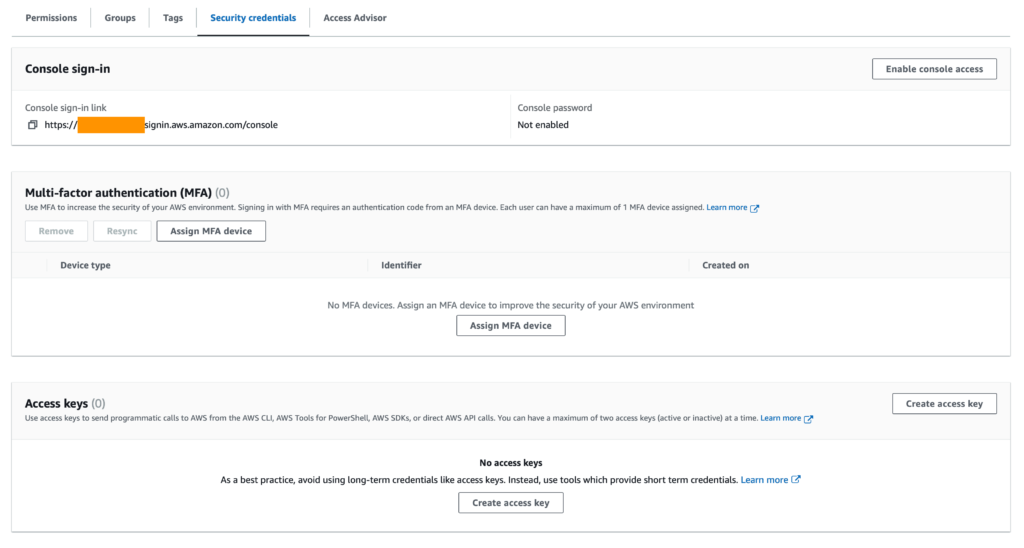
После этого выберите «Application running outside of AWS» и нажмите кнопку «Next». На следующем экране нажмите кнопку «Create access key «.
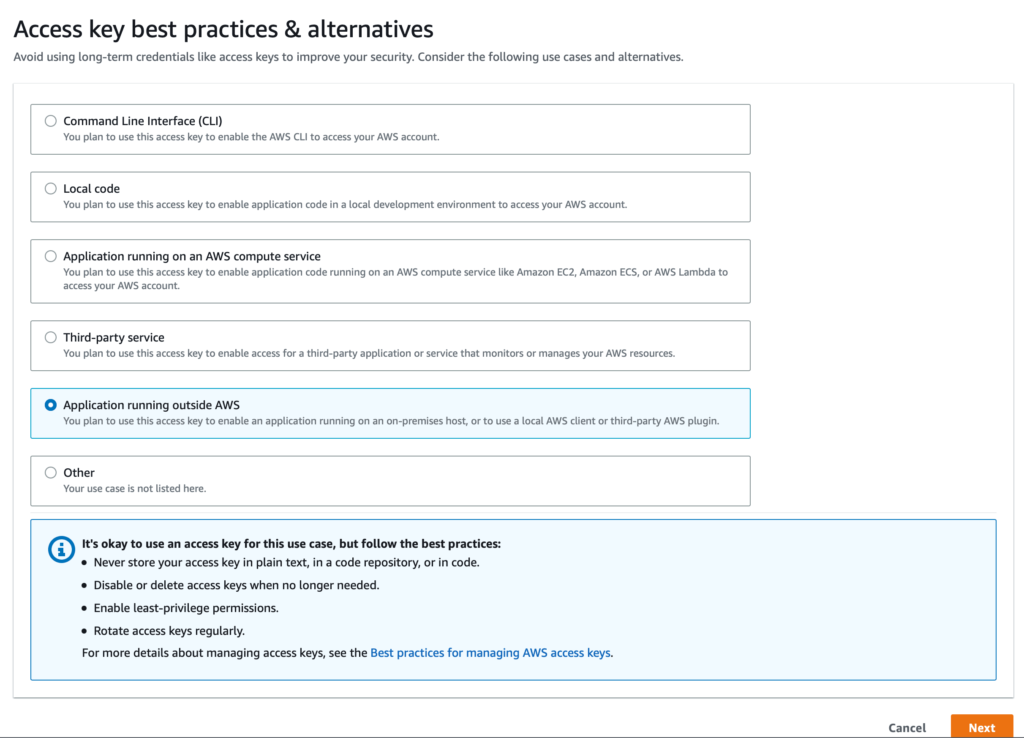
После того как вы получили учетные данные для IAM-пользователя github, необходимо добавить их в GitHub. Для этого перейдите в свой репозиторий и нажмите на «Настройки» -> «Секретные ключи и переменные -> Действия». Далее нажмите на кнопку «New repository secret».
Создайте секрет для AWS_ACCESS_KEY_ID. Затем создайте еще один секрет для AWS_SECRET_ACCESS_KEY. Убедитесь, что их значения соответствуют значениям учетных данных, которые вы только что создали.
Сделайте кормит и пуш вашего кода.
Проверьте вывод конвейера, чтобы убедиться в успешном выполнении. Имейте в виду, что для успешного развертывания может потребоваться несколько минут.
Конечное тестирование
Наконец, давайте добавим сквозной тест для нашей Lambda. Таким образом мы убедимся, что она работает так, как ожидалось. Кроме того, это даст пример ее использования.
Сначала добавим Boto3 и pytest в файл requirements.txt:
boto3==1.28.25 pytest==7.4.0 torch==2.0.1 transformers==4.31.0
Затем создадим новый модуль tests.py:
import json
import boto3
def test_sentiment_is_predicted():
client = boto3.client('lambda')
response = client.invoke(
FunctionName='ml-model-development-ml_model',
InvocationType='RequestResponse',
Payload=json.dumps({
"text": "I am so happy! I love this tutorial! You really did a great job!"
})
)
assert json.loads(response['Payload'].read().decode('utf-8'))["sentiment"] == "positive"
Здесь мы использовали Boto3 для вызова нашей лямбда-функции. В качестве полезной нагрузки мы передали очень позитивный текст для предсказания настроения. Затем мы проверим, что настроение позитивное.
Не стесняйтесь запускать тесты локально с помощью команды python -m pytest tests.py. Только не забудьте установить новые зависимости. Вам потребуется настроить учетные данные AWS.
Добавьте задание сквозного тестирования в .github/workflows/lambda.yml
name: ML Lambda Deploy
on:
push:
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_DEFAULT_REGION: eu-west-1
APP_ENVIRONMENT: development # new
jobs:
deploy-development:
strategy:
fail-fast: false
matrix:
python-version: ['3.10']
node-version: [18]
os: [ubuntu-latest]
runs-on: ${{ matrix.os }}
steps:
- name: Checkout Code
uses: actions/checkout@v3
- name: Set up Python 3.10
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
- name: Install Serverless Framework
run: npm install -g serverless
- name: Install NPM dependencies
run: npm install
- name: Deploy
run: sls deploy --stage development --verbose
e2e: # new
needs: [deploy-development]
strategy:
fail-fast: false
matrix:
python-version: [ '3.10' ]
os: [ ubuntu-latest ]
runs-on: ${{ matrix.os }}
steps:
- name: Checkout Code
uses: actions/checkout@v3
- name: Set up Python 3.10
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- name: Install Dependencies
run: pip install -r requirements.txt
- name: Run pytest
run: pytest tests.py
Вот и все! Сделайте и коммит и пуш своего кода. Вы должны увидеть, что конвейер запущен. Он должен быть успешным.
Поздравляем! Теперь у вас есть полностью автоматизированный CI/CD-конвейер, который развертывает вашу Lambda-функцию, обслуживающую ML-модель.
Вы можете уничтожить ресурсы AWS, заменив sls deploy --stage development --verbose на sls remove --stage development --verbose внутри задания deploy-development.
Заключение
Из этого руководства вы узнали, как развернуть ML-модель на AWS Lambda и как использовать ее с помощью библиотеки Boto3. Вы также узнали, как создать CI/CD-конвейер, который автоматически развертывает вашу Lambda-функцию и выполняет для нее сквозные тесты. Для развертывания функции Lambda вы использовали Serverless Framework, а для создания CI/CD-конвейера — GitHub Actions.
Перевод статьи «Deploying a Machine Learning Model to AWS Lambda».

