Перевод статьи «Normalization of Data in Python».
Сегодня мы хотим поговорить о том, что такое нормализация данных в Python. Пожалуй, начать стоит с определения. Нормализация данных – это метод, который ускоряет получение желаемого результата за счет того, что машине приходится обрабатывать меньший диапазон данных.
Нормализация – непростая задача, потому что все ваши результаты зависят от выбора правильного метода нормализации. Выбрав неправильный метод, вы можете получить совсем не то, что ожидали.
Нормализация также зависит от типа данных, т.е. от того, имеете ли вы дело с изображением, текстом, числами и т. д. Каждый тип данных имеет свои методы нормализации. В этой статье мы сосредоточимся на числовых данных.
Метод 1. Использование sklearn
Метод sklearn – очень популярный метод нормализации данных.
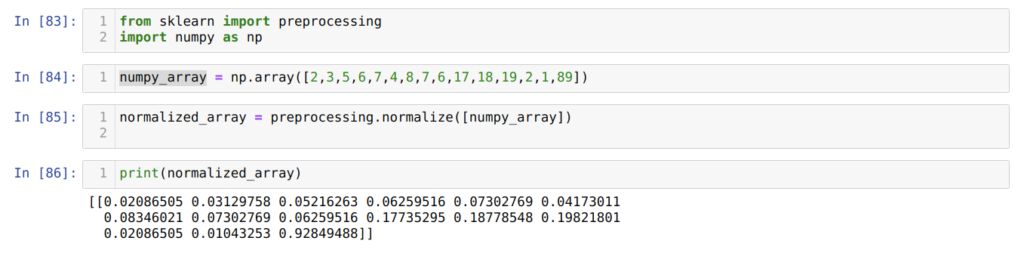
В ячейке номер [83] мы импортируем все необходимые для работы библиотеки: NumPy и sklearn. Вы также можете заметить, что мы импортируем preprocessing из самого sklearn. Именно поэтому данный метод называется методом нормализации sklearn.
Далее, в ячейке номер [84] мы создаем массив NumPy с уникальными целочисленными значениями.
В ячейке номер [85] вызываем метод normalize() из preprocessing и передаем numpy_array, который мы только что создали на предыдущем шаге, в качестве параметра.
Как видно из результатов, в ячейке номер [86] все наши целочисленные данные теперь нормализованы между нулем и единицей.
Метод 2. Нормализация определенного столбца в наборе данных с помощью sklearn
Мы также можем нормализовать конкретный столбец нашего набора данных. Давайте разберем такой случай.
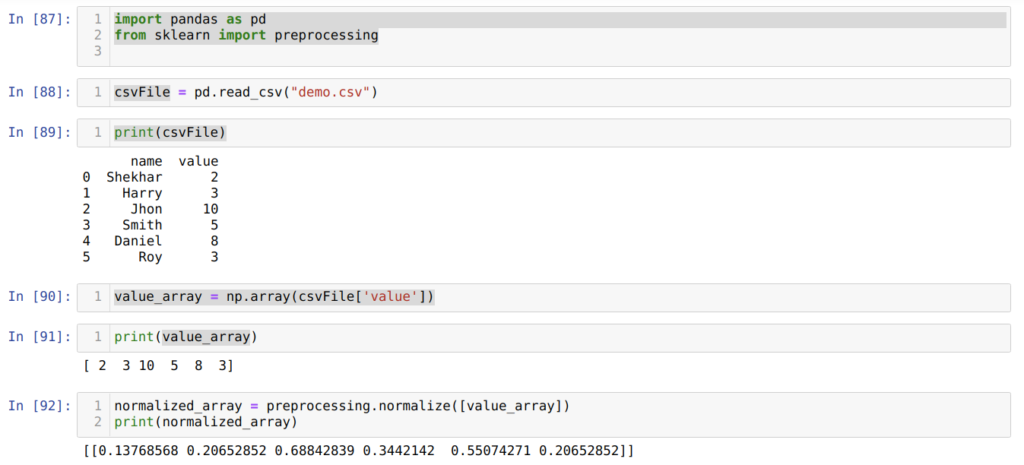
В ячейке номер [87] мы импортируем библиотеки pandas и sklearn.
В ячейке номер [88] создаем CSV-файл с поддельными данными и загружаем его с помощью модуля pandas (функция read_csv()).
Далее, в ячейке номер [89] мы выводим на экран только что загруженный CSV-файл.
В следующей ячейке мы считываем конкретный столбец CSV-файла, используя np.array(), и сохраняем результат в переменную value_array.
В ячейке номер [92] мы вызываем метод normalize() из preprocessing, в который передаем value_array в качестве параметра.
Метод 3. Нормализация всего набора данных по столбцам или по строкам
В предыдущем методе мы обсудили, как можно нормализовать конкретный столбец файла CSV. Но иногда нам нужно нормализовать весь набор данных. В таком случае мы можем использовать метод, показанный ниже. В нем мы нормализуем весь набор данных, но по столбцам (axis = 0). Если в параметрах функции normalize() указать axis = 1, она будет нормализовать данные по строкам. По умолчанию значение axis равно 1.
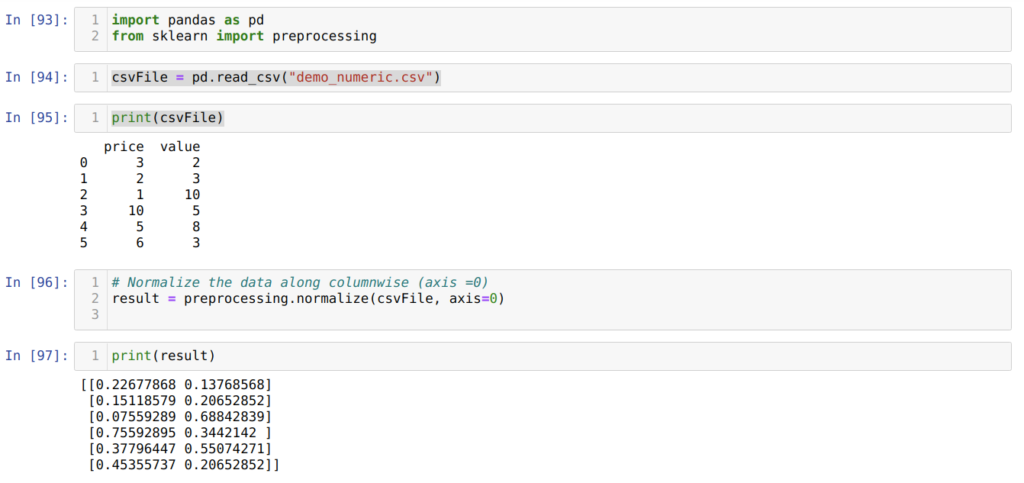
Итак, первые три шага абсолютно идентичны тому, что мы делали в предыдущем разделе.
В ячейке номер [96] мы передаем весь CSV-файл (demo_numeric.csv) вместе с еще одним дополнительным параметром axis = 0, который сообщает библиотеке, что мы хотим нормализовать весь набор данных по столбцам.
И далее, в ячейке [97] мы выводим результат нормализованных данных со значениями от нуля до единицы.
Метод 4. Использование MinMaxScaler()
Sklearn предоставляет и другой метод нормализации — MinMaxScalar. Благодаря простоте использования этот метод тоже пользуется большой популярностью.
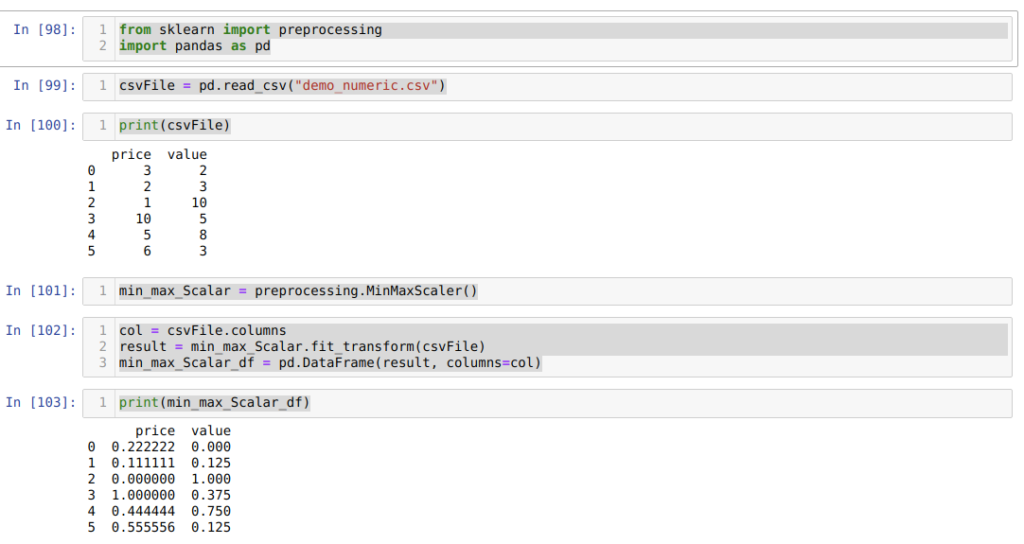
Для начала импортируем все необходимые пакеты. Затем создаем CSV-файл с фиктивными данными (demo_numeric.csv) и загружаем его с помощью пакета pandas (функция read_csv()). После выводим этот файл на экран. В общем, всё, как и в предыдущих методах.
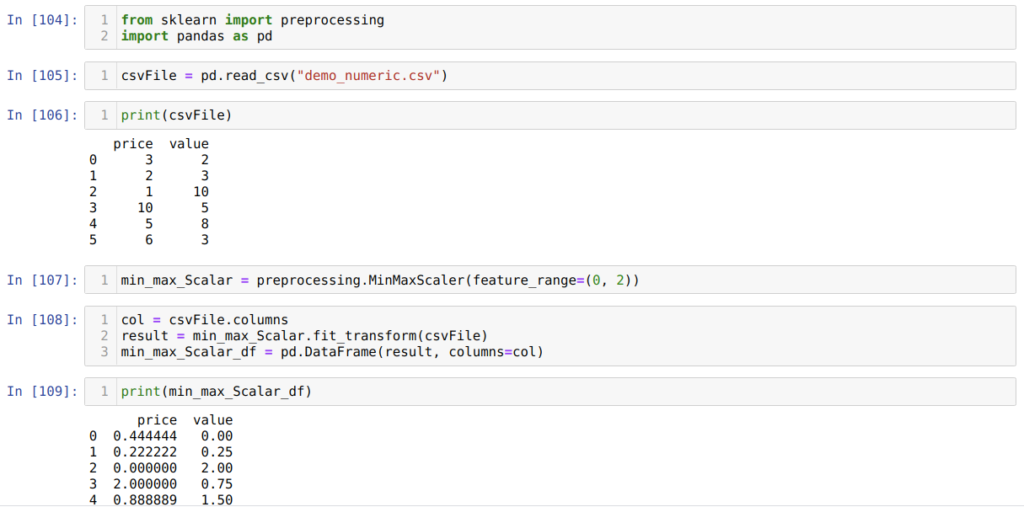
А вот дальше, в ячейке номер [101], мы вызываем MinMaxScalar() из preprocessing и создаем объект min_max_Scalar. Мы не передали никаких параметров, потому что нам нужно нормализовать данные между 0 и 1. Но при желании вы можете добавить свои значения (мы это рассмотрим в следующем разделе).
В ячейке номер [102] мы сначала читаем все имена столбцов для дальнейшего использования для отображения результатов. Затем мы вызываем fit_tranform() из созданного объекта min_max_Scalar и передаем туда CSV-файл.
После этого, в ячейке номер [103], мы получаем нормализованные результаты, находящиеся между 0 и 1.
Метод 5. Использование MinMaxScaler с разными параметрами
Sklearn также предоставляет возможность изменить нормализованные значения. По умолчанию функция нормализует значения в диапазоне от нуля до единицы. Однако есть параметр (называется feature_range), с помощью которого можно устанавливать границы нормализованных значений в соответствии с нашими требованиями.
Первые три шага идентичны тому, что мы делали в прошлых примерах.
Дальше, в ячейке номер [107], мы вызываем MinMaxScalar из preprocessing и создаем объект min_max_Scalar. Но в этот раз внутри MinMaxScaler мы передаем дополнительный параметр — feature_range. Значение параметра мы устанавливаем от 0 до 2. Таким образом, теперь MinMaxScaler нормализует значения данных от нуля до двух.
В ячейке [108] мы сначала читаем все имена столбцов, а затем вызываем fit_tranform() из созданного ранее объекта min_max_Scalar и передаем туда CSV-файл в качестве параметра.
И последним действием, в ячейке номер [109], мы получаем нормализованные результаты, которые находятся между 0 и 2.
Метод 6. Использование максимального абсолютного масштабирования
Также можно нормализовать данные с помощью библиотеки pandas. Этот способ тоже весьма популярен. Максимальное абсолютное масштабирование нормализует значения в диапазоне от нуля до единицы. В нашем примере мы применяем .max() и .abs():
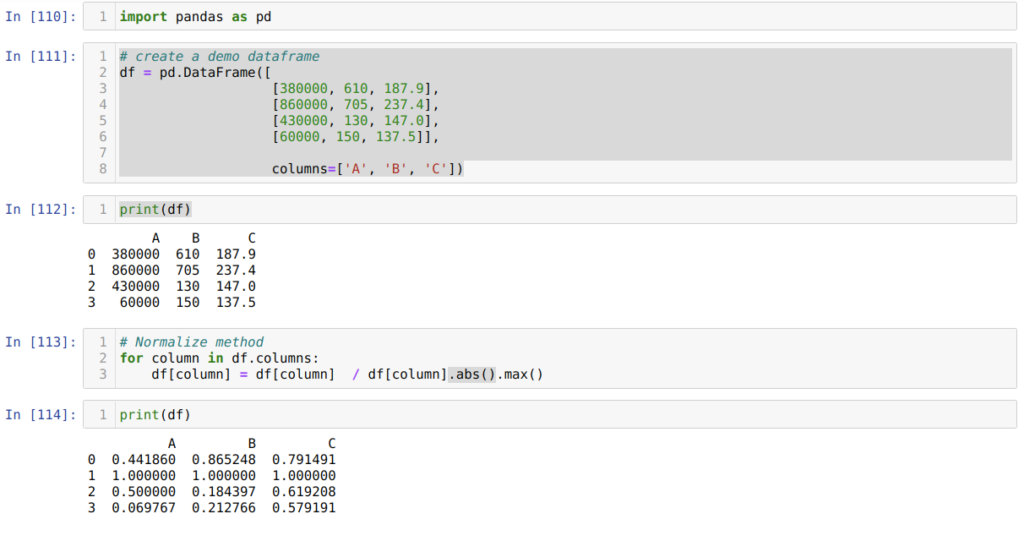
Сначала мы импортируем нужную нам библиотеку pandas.
Затем (в ячейке номер [111]) мы создаем фрейм фиктивных данных и выводим его на экран.
В ячейке [113] мы вызываем каждый столбец, а затем разделяем значения столбца с помощью .max() и .abs().
В ячейке номер [114] мы выводим получившийся результат, который подтверждает, что наши данные действительно нормализованы между 0 и 1.
Метод 7. Использование метода z-оценки
Следующий метод, который мы хотим обсудить, — это метод z-оценки. Он преобразует информацию в распределение. Метод z-оценки вычисляет среднее значение каждого столбца, затем вычитает его из каждого столбца и, наконец, делит на стандартное отклонение. Таким образом мы получаем данные, нормализованные между -1 и 1.
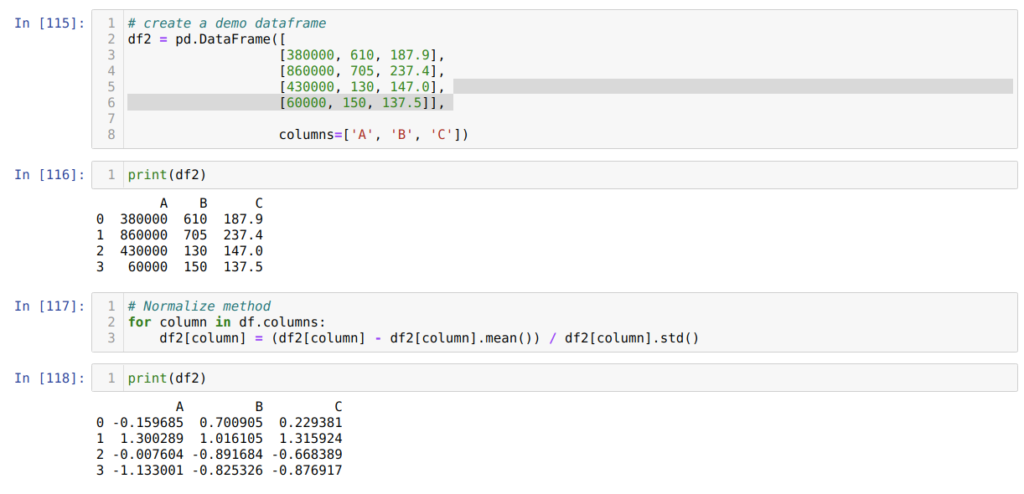
В ячейке номер [115] мы создаем фрейм фиктивных данных и выводим его.
Далее, в ячейке [117], мы вычисляем среднее значение столбцов и вычитаем его из каждого столбца. Затем делим значение столбца на стандартное отклонение.
В итоге, в ячейке номер [118] мы получаем и выводим на экран данные, нормализованные в диапазоне от -1 до 1.
Заключение
Сегодня мы обсудили, что такое нормализация данных в Python, и разобрали разные виды методов нормализации. Среди них sklearn, который очень известен благодаря широкому использованию в машинном обучении.
Однако не стоит забывать, что всё зависит от требований пользователя. Иногда для нормализации данных достаточно функции pandas.
Нельзя сказать, что существуют только данные методы нормализации. Нет, различных методов нормализации довольно много, причем они зависят от типа данных. В этой статье мы сфокусировались на числовых данных.

