Pandas, пожалуй, можно назвать самым важным пакетом Python для анализа данных. С более чем 100 миллионами загрузок в месяц, это фактически стандартный пакет для обработки данных и их исследовательского анализа. Его способность читать и записывать во множество форматов делает его универсальным инструментом для практиков в области науки о данных. Его функции работы с данными делают его очень доступным и практичным инструментом для агрегирования, анализа и очистки данных.
Друзья, подписывайтесь на наш телеграм канал Pythonist. Там еще больше туториалов, задач и книг по Python.
Содержание
- Что такое pandas?
- Для чего используется pandas?
- Основные преимущества пакета pandas
- Как установить pandas?
- Импорт данных в pandas
- Вывод данных в pandas
- Просмотр DataFrames
- Нарезка и извлечение данных в pandas
- Очистка данных с помощью pandas
- Анализ данных в pandas
- Визуализация данных в pandas
- Часто задаваемые вопросы по pandas
- Заключение
Что такое pandas?
Pandas — это пакет для манипулирования табличными данными в Python. То есть данными в виде строк и столбцов, также известными как DataFrames. Интуитивно можно представить себе DataFrame как таблицу Excel.
Функциональность pandas включает в себя преобразование данных. Например, при помощи pandas можно сортировать строки и выделять подмножества, вычислять сводную статистику, например, среднее значение, изменять формы фреймов и объединять их.
Pandas хорошо работает с другими популярными пакетами Python для работы с данными, которые часто называют экосистемой PyData:
- NumPy для численных вычислений
- Matplotlib, Seaborn, Plotly для визуализации данных
- scikit-learn для машинного обучения
Для чего используется pandas?
Pandas может использоваться во всех процессах анализа данных. С помощью этой библиотеки можно:
- Импортировать наборы данных из баз данных, электронных таблиц, CSV-файлов и т.д.
- Очищать наборы данных, например, устраняя пропущенные значения.
- Упорядочивать наборы данных путем преобразования их структуры в формат, пригодный для анализа.
- Агрегировать данные, вычисляя сводную статистику, например, среднее значение столбцов, корреляцию между ними и т.д.
- Визуализировать наборы данных и открывать новые возможности.
Pandas также имеет функционал для анализа временных рядов и текстовых данных.
Ключевые преимущества пакета pandas
Несомненно, pandas — это мощный инструмент манипулирования данными, обладающий рядом преимуществ:
- Создан для Python. Python — самый популярный в мире язык для машинного обучения и науки о данных.
- Меньшая многословность в расчете на единицу операций. Код, написанный на pandas, лаконичен и требует меньшего количества строк для получения желаемого результата.
- Интуитивно понятное представление данных. Pandas предлагает исключительно интуитивное представление данных, что облегчает их понимание и анализ.
- Обширный набор функций. Pandas поддерживает широкий набор операций: анализ данных, работа с пропущенными значениями, вычисление статистики, визуализация одномерных и двумерных данных и многое другое.
- Работа с большими данными. Pandas легко справляется с большими массивами данных. Он обеспечивает скорость и эффективность при работе с наборами данных, содержащих порядка миллионов записей и сотен столбцов, в зависимости от машины.
Установка pandas
Прежде чем приступить к изучению функциональности pandas, давайте сначала установим эту библиотеку. Для этого достаточно воспользоваться командой pip install в терминале.
pip install pandas
Импорт данных в pandas
Чтобы начать работу с pandas, импортируйте пакет pandas Python, как показано ниже. При импорте наиболее распространенным псевдонимом для pandas является pd.
import pandas as pd
Импорт CSV-файлов
Для чтения файла со значениями, разделенными запятыми, т.е. CSV-файлов, используйте функцию read_csv() с указанием пути к CSV-файлу.
df = pd.read_csv("diabetes.csv")
Эта операция чтения загружает файл diabetes.csv для генерации объекта Dataframe — df. В этом учебнике мы расскажем, как работать с такими объектами DataFrame.
От редакции Pythonist: рекомендуем также почитать статью «Как создать Pandas DataFrame».
Импорт текстовых файлов
Чтение текстовых файлов аналогично чтению CSV-файлов. Единственным нюансом является то, что необходимо указать разделитель с помощью аргумента sep, как показано ниже.
Аргумент sep (от англ. separator — разделитель) представляет символ, используемый для разделения строк в DataFrame. Обычно используются запятая (sep=","), пробел (sep="\s"), табуляция (sep="\t") и двоеточие (sep=":").
Здесь \s представляет собой один символ пробела:
df = pd.read_csv("diabetes.txt", sep="\s")
Импорт файлов Excel (один лист)
Чтение файлов Excel (как XLS, так и XLSX) осуществляется с помощью функции read_excel(), использующей в качестве входных данных путь к файлу.
df = pd.read_excel('diabetes.xlsx')
Можно добавить и другие аргументы, например header, чтобы указать, какая строка становится заголовком DataFrame. По умолчанию он имеет значение 0, которое обозначает первую строку в качестве заголовков или имен столбцов. В аргументе names можно также указать имена столбцов в виде списка. Аргумент index_col (по умолчанию None) может быть использован, если файл содержит индекс строк.
Примечание. В pandas DataFrame или Series индекс — это идентификатор, указывающий на местоположение строки или столбца в pandas DataFrame. В двух словах, индекс маркирует строку или столбец DataFrame и позволяет получить доступ к ним по их индексам (об этом мы поговорим позже). Индекс строки DataFrame может представлять собой диапазон (например, от 0 до 303), временной ряд (даты или временные метки), уникальный идентификатор (например, employee_ID в таблице employees) или другие типы данных. Для столбцов это обычно строка, обозначающая имя столбца.
Импорт файлов Excel (несколько вкладок)
Чтение файлов Excel с несколькими вкладками не имеет особых отличий. Необходимо только указать один дополнительный аргумент — sheet_name. В качестве sheet_name можно передать либо имя вкладки (строку), либо позицию вкладки (целое число).
Обратите внимание, что в Python используется 0-индексация, поэтому доступ к первой вкладке можно получить при sheet_name=0.
# Выбираем вторую вкладку, но пишем 1, так как индексация начинается с нуля
df = pd.read_excel('diabetes_multi.xlsx', sheet_name=1)
Импорт JSON-файла
Аналогично функции read_csv(), для файлов типа JSON можно использовать функцию read_json() с именем файла JSON в качестве аргумента. Приведенный ниже код считывает JSON-файл с диска и создает объект DataFrame df.
df = pd.read_json("diabetes.json")
Если вы хотите узнать больше об импорте данных в pandas, ознакомьтесь с этой шпаргалкой по импорту различных типов файлов в Python.
Вывод данных в pandas
Pandas позволяет не только импортировать данные из различных файлов, но и экспортировать их в различные форматы. Это особенно актуально, когда данные преобразуются с помощью pandas и должны быть сохранены локально на вашей машине.
Вывод DataFrame в CSV-файл
Фрейм данных pandas (в нашем учебнике — df) сохраняется в CSV-файл с помощью метода .to_csv(). В качестве аргументов указываются имя файла с путем к нему и index. При этом index=True подразумевает запись индекса DataFrame.
df.to_csv("diabetes_out.csv", index=False)
Вывод DataFrame в файл JSON
Экспорт объекта датафрейма в JSON происходит при помощи метода .to_json():
df.to_json("diabetes_out.json")
Примечание: JSON-файл хранит табличный объект типа DataFrame в виде пары ключ-значение. Поэтому в JSON-файле можно наблюдать повторяющиеся заголовки столбцов.
Вывод DataFrame в текстовый файл
Для вывода датафрейма в текстовый файл можно вызвать команду .to_csv(), как при записи в CSV. Единственное отличие состоит в том, что формат выходного файла — .txt, и необходимо указать разделитель с помощью аргумента sep.
df.to_csv('diabetes_out.txt', header=df.columns, index=None, sep=' ')
Вывод DataFrame в файл Excel
Чтобы сохранить датафрейм в файл формата ".xls" или ".xlsx", вызовите функцию .to_excel() из объекта DataFrame.
df.to_excel("diabetes_out.xlsx", index=False)
Просмотр DataFrames
После считывания табличных данных в виде DataFrame нам нужно их как-то просмотреть. Можно просмотреть либо небольшую выборку из набора данных, либо сводку данных в виде итоговой статистики.
Как просмотреть данные с помощью .head() и .tail()
С помощью методов .head() и .tail() можно просмотреть несколько первых или несколько последних строк DataFrame соответственно. Количество строк можно задать через аргумент n (по умолчанию — 5).
df.head()
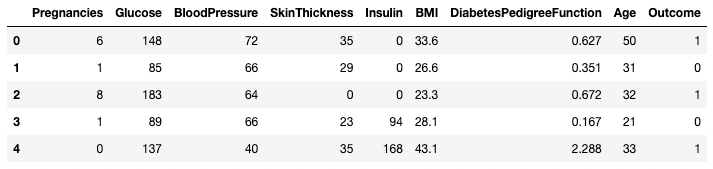
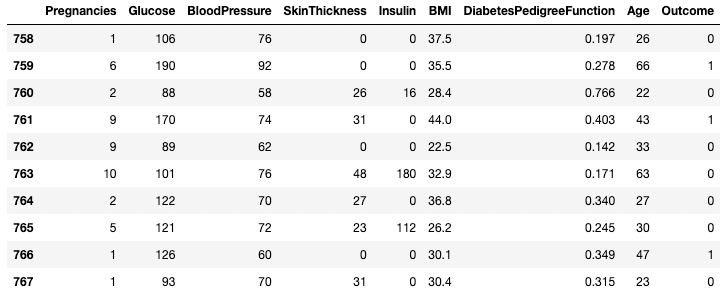
df.tail(n = 10)
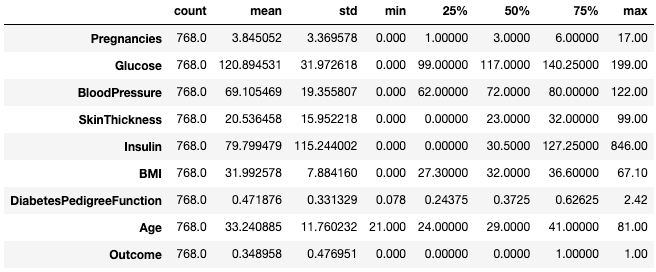
Понимание данных с помощью метода .describe()
Метод .describe() выводит сводную статистику всех числовых столбцов, такую как количество, среднее значение, стандартное отклонение, диапазон и квартили.
df.describe()
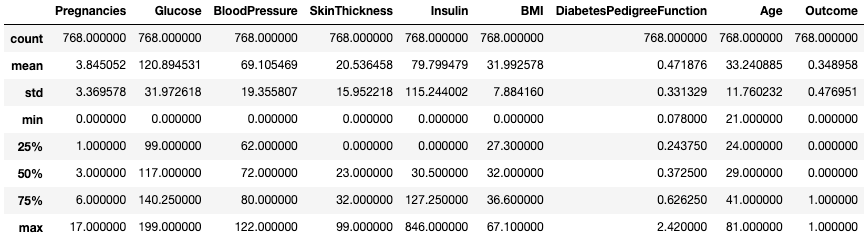
Этот метод позволяет быстро оценить масштаб, отклонение и диапазон числовых данных.
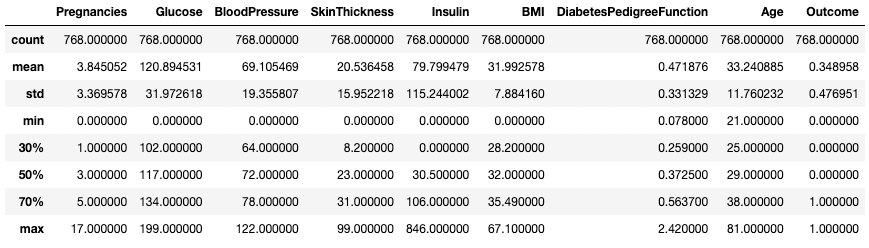
Вы также можете изменить квартили с помощью аргумента percentiles. Здесь, например, мы рассматриваем 30%, 50% и 70% процентили числовых столбцов в DataFrame df.
df.describe(percentiles=[0.3, 0.5, 0.7])
С помощью аргумента include можно также выделить определенные типы данных в итоговом выводе. Здесь, например, мы суммируем только столбцы с типом данных integer.
df.describe(include=[int])
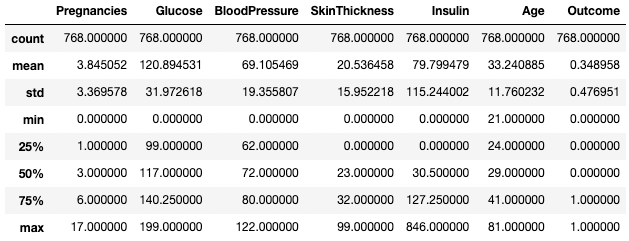
Аналогичным образом можно исключить определенные типы данных, используя аргумент exclude.
df.describe(exclude=[int])
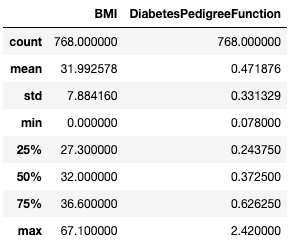
Часто практикам удобно просматривать такую статистику, транспонируя ее с помощью атрибута .T.
df.describe().T
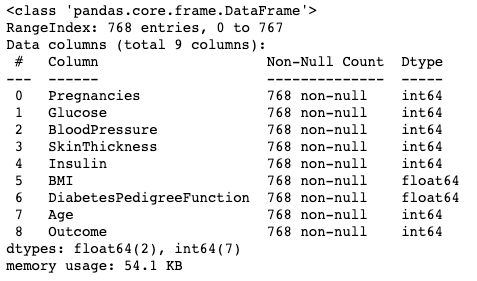
Понимание данных с помощью метода .info()
Метод .info() — это быстрый способ посмотреть типы данных, пропущенные значения и размер данных в DataFrame. Здесь мы устанавливаем аргумент show_counts равным True, что дает возможность увидеть общее количество не пропущенных значений в каждом столбце.
Мы также устанавливаем значение memory_usage=True. memory_usage показывает общее использование памяти элементами DataFrame. Если для параметра verbose установлено значение True, то выводится полная сводка из .info().
df.info(show_counts=True, memory_usage=True, verbose=True)
Понимание данных с помощью .shape
Количество строк и столбцов фрейма можно определить с помощью атрибута .shape. Он возвращает кортеж (строка, столбец) и может быть проиндексирован для получения только строк, а в качестве выходных данных учитываются только столбцы.
df.shape # Получить число строк и столбцов df.shape[0] # Получить только число строк df.shape[1] # Получить только число столбцов
Вывод:
(768,9) 768 9
Получить все столбцы и имена столбцов
Вызов атрибута .columns объекта DataFrame возвращает имена столбцов в виде объекта Index. Напомним, что индекс pandas — это адрес/метка строки или столбца.
df.columns
Вывод:

Он может быть преобразован в список с помощью функции list().
list(df.columns)
Результат:

Проверка отсутствующих значений в pandas с помощью функции .isnull()
В нашем примере DataFrame нет ни одного пропущенного значения. Давайте введем несколько, чтобы было интереснее.
Метод .copy() создает копию исходного DataFrame. Это делается для того, чтобы любые изменения в копии не отражались на исходном DataFrame. С помощью метода .loc (будет рассмотрен позже) можно установить в столбце Pregnancies со второй по пятую строки значения NaN, которые обозначают отсутствующие значения.
df2 = df.copy() df2.loc[2:5,'Pregnancies'] = None df2.head(7)
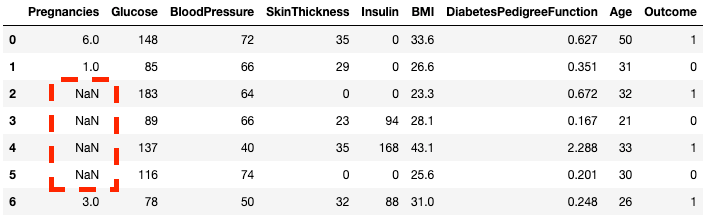
Проверить, отсутствует ли элемент в DataFrame, можно с помощью метода .isnull().
df2.isnull().head(7)
Поскольку часто полезнее знать количество отсутствующих данных, можно комбинировать .isnull() с .sum() для подсчета количества нулей в каждом столбце.
df2.isnull().sum()
Результат:
Pregnancies 4 Glucose 0 BloodPressure 0 SkinThickness 0 Insulin 0 BMI 0 DiabetesPedigreeFunction 0 Age 0 Outcome 0 dtype: int64
Для получения общего количества нулей в DataFrame можно также выполнить двойное суммирование.
df2.isnull().sum().sum() # Вывод: # 4
Нарезка и извлечение данных в pandas
Пакет pandas предлагает несколько способов выделения подмножества, фильтрации и выделения данных во фреймах DataFrames. Здесь мы рассмотрим наиболее распространенные способы.
Выделение одного столбца с помощью []
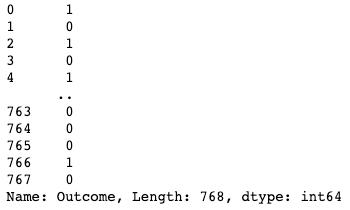
Вы можете выделить один столбец, используя квадратные скобки [ ] с именем столбца в них. На выходе получается объект pandas Series.
Серия pandas — это одномерный массив, содержащий данные любого типа, включая целые числа, числа с плавающей точкой, строки, булевы значения, объекты Python и т.д. DataFrame состоит из множества серий, которые выступают в качестве столбцов.
df['Outcome']
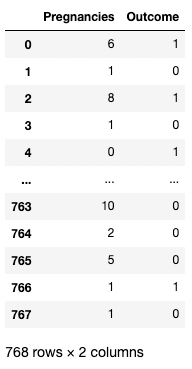
Изолирование двух или более столбцов с помощью [[]]
Для получения более одного столбца можно также указать список имен столбцов внутри квадратных скобок. Здесь квадратные скобки используются двумя разными способами. Внешние квадратные скобки используются для обозначения подмножества фрейма DataFrame, а внутренние — для создания списка.
df[['Pregnancies', 'Outcome']]
Изолирование одного ряда с помощью []
Выделить один ряд можно путем передачи булевого ряда с одним значением True. В приведенном ниже примере возвращается второй ряд с index=1. Здесь .index возвращает метки строк DataFrame, а сравнение превращает их в булевский одномерный массив.
df[df.index==1]

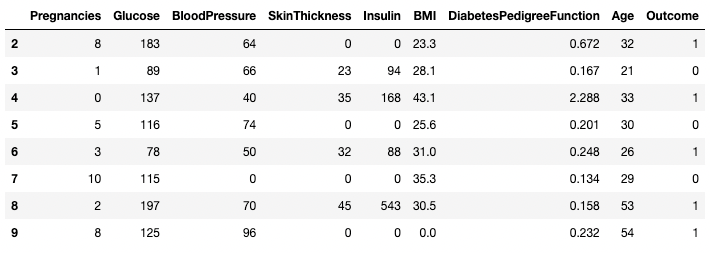
Выделение двух или более строк с помощью []
Аналогичным образом можно вернуть два или более ряда, используя метод .isin() вместо оператора ==.
df[df.index.isin(range(2,10))]
Использование .loc[] и .iloc[] для извлечения строк
С помощью .loc[] и .iloc[] («местоположение» и «целочисленное местоположение») можно получить определенные строки по меткам или условиям.
В .loc[] для указания на строку, столбец или ячейку используется метка, а в .iloc[] — числовая позиция. Чтобы понять разницу между ними, изменим созданный ранее индекс df2.
df2.index = range(1,769)
В приведенном ниже примере вместо DataFrame возвращается pandas Series. 1 представляет собой индекс ряда (метка), а 1 в .iloc[] — позицию ряда (первый ряд).
df2.loc[1]
Вывод:
Pregnancies 6.000 Glucose 148.000 BloodPressure 72.000 SkinThickness 35.000 Insulin 0.000 BMI 33.600 DiabetesPedigreeFunction 0.627 Age 50.000 Outcome 1.000 Name: 1, dtype: float64
И .iloc[]:
df2.iloc[1]
Вывод:
Pregnancies 1.000 Glucose 85.000 BloodPressure 66.000 SkinThickness 29.000 Insulin 0.000 BMI 26.600 DiabetesPedigreeFunction 0.351 Age 31.000 Outcome 0.000 Name: 2, dtype: float64
Вы также можете получить несколько строк, указав диапазон в квадратных скобках.
df2.loc[100:110]
![Изолирование строк в pandas с помощью .loc[]](https://pythonist.ru/wp-content/uploads/2023/07/image17_9605f071b5.png)
df2.iloc[100:110]
![Изолирование строк в pandas с помощью .iloc[]](https://pythonist.ru/wp-content/uploads/2023/07/image28_07af2245c8.png)
Вы также можете получать подмножество с помощью .loc[] и .iloc[], используя список вместо диапазона.
df2.iloc[[100, 200, 300]]
![Изолирование строк с помощью списка в pandas с помощью .iloc[]](https://pythonist.ru/wp-content/uploads/2023/07/image25_36fb2e17e1.png)
Можно также выбирать конкретные столбцы вместе со строками. В этом .iloc[] отличается от .loc[] — ему требуется расположение столбцов, а не их метки.
df2.loc[100:110, ['Pregnancies', 'Glucose', 'BloodPressure']]
![Изолирование столбцов в pandas с помощью .loc[]](https://pythonist.ru/wp-content/uploads/2023/07/image7_40bb6ca301.png)
df2.iloc[100:110, :3]
![Изолирование столбцов с помощью .iloc[]](https://pythonist.ru/wp-content/uploads/2023/07/image42_bf1e7b2f49-1.png)
Для ускорения работы можно передавать начальный индекс строки в виде диапазона.
df2.loc[760:, ['Pregnancies', 'Glucose', 'BloodPressure']]
![Изолирование столбцов и строк в pandas с помощью .loc[]](https://pythonist.ru/wp-content/uploads/2023/07/image33_863cb34962.png)
df2.iloc[760:, :3]
![Изолирование столбцов и строк в pandas с помощью .iloc[]](https://pythonist.ru/wp-content/uploads/2023/07/image4_9ea07f1046.png)
Обновить/изменить определенные значения можно с помощью оператора присваивания =.
df2.loc[df['Age']==81, ['Age']] = 80
Условная нарезка (данные, удовлетворяющие определенным условиям)
Pandas позволяет фильтровать данные по условиям над значениями строк/столбцов. Например, приведенный ниже код выбирает строку, в которой значение артериального давления равно 122.
Здесь мы выделяем строки с помощью скобок [], как это было показано в предыдущих разделах. Однако вместо индексов строк или имен столбцов мы вводим условие, при котором столбец BloodPressure равен 122. Обозначим это условие через df.BloodPressure == 122.
df[df.BloodPressure == 122]

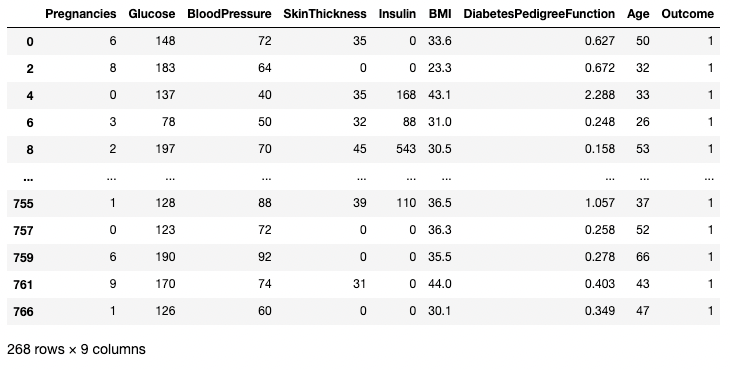
В приведенном ниже примере извлекаются все строки, в которых Outcome равен 1. Здесь df.Outcome выбирает этот столбец, df.Outcome == 1 возвращает серию булевых значений, определяющих, какие Outcomes равны 1, затем [] берет подмножество df, в котором эта булева серия равна True.
df[df.Outcome == 1]
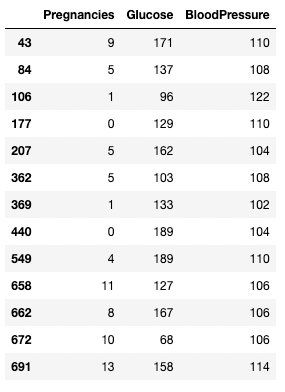
Для проведения сравнений можно использовать оператор >. В приведенном ниже коде для всех записей, в которых давление крови больше 100, получены значения Pregnancies, Glucose и BloodPressure.
df.loc[df['BloodPressure'] > 100, ['Pregnancies', 'Glucose', 'BloodPressure']]
Очистка данных с помощью pandas
Очистка данных — одна из наиболее распространенных задач в работе с данными. Pandas позволяет предварительно обрабатывать данные для любых целей, включая, в частности, обучение ML моделей.
Для иллюстрации нескольких примеров использования очистки данных воспользуемся приведенным ранее DataFrame df2 с четырьмя пропущенными значениями. Напомним, как можно посмотреть количество пропущенных значений в DataFrame:
df2.isnull().sum()
Pregnancies 4 Glucose 0 BloodPressure 0 SkinThickness 0 Insulin 0 BMI 0 DiabetesPedigreeFunction 0 Age 0 Outcome 0 dtype: int64
Работа с недостающими данными
Техника № 1: отбрасывание недостающих значений
Одним из способов решения проблемы недостающих данных является их отбрасывание. Это особенно полезно в тех случаях, когда данных много и потеря небольшой части не повлияет на последующий анализ. Для этого можно использовать метод .dropna(), как показано ниже. Здесь мы сохраняем результаты работы метода .dropna() в DataFrame df3.
df3 = df2.copy() df3 = df3.dropna() df3.shape
Вывод:
(764, 9) # this is 4 rows less than df2
Аргумент axis позволяет указать, отбрасываются ли строки или столбцы с отсутствующими значениями. axis по умолчанию удаляет строки, содержащие NaN. Если использовать axis=1, то будут удалены столбцы с одним или несколькими значениями NaN.
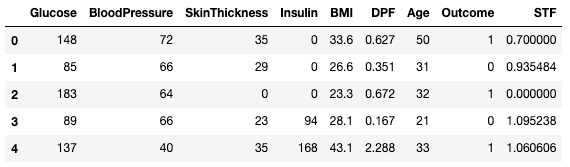
Также обратите внимание на то, что мы используем аргумент inplace=True, который позволяет не сохранять вывод .dropna() в новый DataFrame.
df3 = df2.copy() df3.dropna(inplace=True, axis=1) df3.head()
Вы также можете отбросить как строки, так и столбцы с отсутствующими значениями, установив для аргумента how значение 'all'.
df3 = df2.copy() df3.dropna(inplace=True, how='all')
Техника № 2: замена отсутствующих значений
Вместо отбрасывания можно заменить пропущенные значения суммарной статистикой или конкретным значением (в зависимости от конкретного случая).
Допустим, в столбце температуры, обозначающем температуру по дням недели, пропущена одна строка. В таком случае замена пропущенного значения на среднее значение температуры за неделю может оказаться более эффективной, чем полное исключение значений.
Заменить недостающие данные средним значением строки или столбца можно с помощью приведенного ниже кода.
df3 = df2.copy() # Get the mean of Pregnancies mean_value = df3['Pregnancies'].mean() # Fill missing values using .fillna() df3 = df3.fillna(mean_value)
Работа с дублирующимися данными
Давайте добавим несколько дубликатов к исходным данным, чтобы узнать, как устранить дубликаты в DataFrame. Здесь мы используем метод .concat() для конкатенации строк фрейма df2 во фрейм df2, добавляя совершенные дубликаты каждой строки в df2.
df3 = pd.concat([df2, df2]) df3.shape # Вывод: # (1536, 9)
Удалить все дублирующиеся строки (по умолчанию) из DataFrame можно с помощью метода .drop_duplicates().
df3 = df3.drop_duplicates() df3.shape # Вывод: # (768, 9)
Переименование столбцов
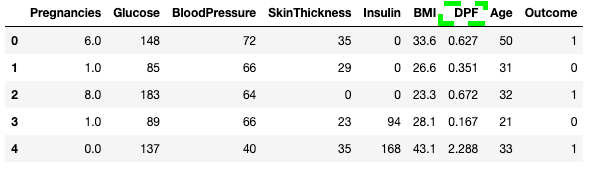
Распространенной задачей очистки данных является переименование столбцов. С помощью метода .rename() можно использовать columns в качестве аргумента для переименования конкретных столбцов.
В приведенном ниже коде показан словарь для сопоставления старых и новых имен столбцов.
df3.rename(columns = {'DiabetesPedigreeFunction':'DPF'}, inplace = True)
df3.head()
Можно также непосредственно присвоить DataFrame имена столбцов в виде списка.
df3.columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DPF', 'Age', 'Outcome', 'STF'] df3.head()
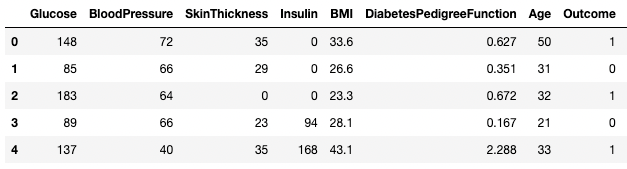
Анализ данных в pandas
Основное преимущество pandas заключается в возможности быстрого анализа данных. В этом разделе мы остановимся на наборе методов анализа, которые можно использовать в pandas.
Операторы суммирования (среднее, мода, медиана)
Как вы видели ранее, среднее значение каждого столбца можно получить с помощью метода .mean().
df.mean()

Аналогично можно вычислить моду — с помощью метода .mode().
df.mode()

С помощью метода .median() вычисляется медиана каждого столбца:
df.median()

Создание новых столбцов на основе существующих
Pandas обеспечивает быстрые и эффективные вычисления путем объединения двух или более столбцов как скалярных переменных.
Приведенный ниже код делит каждое значение в столбце Glucose на соответствующее значение в столбце Insulin для вычисления нового столбца с именем Glucose_Insulin_Ratio.
df2['Glucose_Insulin_Ratio'] = df2['Glucose']/df2['Insulin'] df2.head()

Подсчет с помощью функции .value_counts()
Часто приходится работать с категориальными значениями, и возникает необходимость подсчитать количество наблюдений в столбце для каждой категории.
Для подсчета значений категорий можно использовать метод .value_counts(). Здесь, например, мы подсчитываем количество наблюдений, в которых Outcome является диабетическим (1), и количество наблюдений, в которых Outcome не является диабетическим (0).
df['Outcome'].value_counts()

Добавление аргумента normalize возвращает пропорции вместо абсолютных значений.
df['Outcome'].value_counts(normalize=True)

Отключить автоматическую сортировку результатов можно с помощью аргумента sort (по умолчанию True). По умолчанию сортировка производится на основе подсчетов в порядке убывания.
df['Outcome'].value_counts(sort=False)

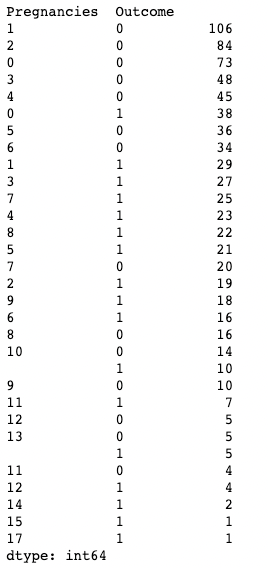
df.value_counts(subset=['Pregnancies', 'Outcome'])
Агрегация данных с помощью .groupby()
Pandas позволяет агрегировать значения, группируя их по определенным значениям столбцов. Это можно сделать, сочетая метод .groupby() с выбранным вами методом суммирования.
Приведенный ниже код отображает среднее значение каждого из числовых столбцов, сгруппированных по критерию Outcome.
df.groupby('Outcome').mean()

Функция .groupby() позволяет группировать данные более чем по одному столбцу, передавая список имен столбцов, как показано ниже.
df.groupby(['Pregnancies', 'Outcome']).mean()
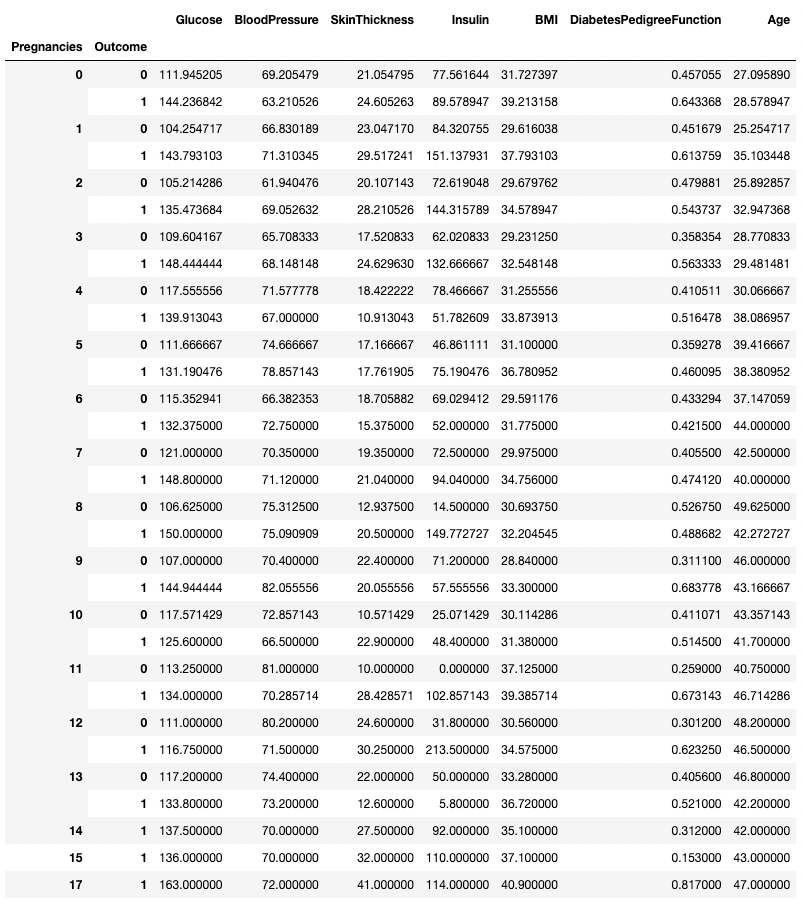
Вместе с .groupby() можно использовать любой метод подведения итогов, включая .min(), .max(), .mean(), .median(), .sum(), .mode() и др.
Pivot tables
Pandas также позволяет вычислять сводную статистику в виде таблиц pivot. Благодаря этому можно легко делать выводы на основе комбинации переменных.
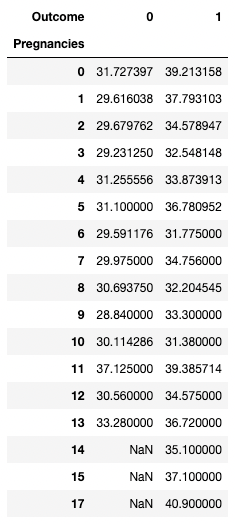
Приведенный ниже код выбирает строки как уникальные значения Pregnancies, значения столбцов — как уникальные значения Outcome, а ячейки — как среднее значение BMI в соответствующей группе.
Например, для Pregnancies = 5 и Outcome = 0 среднее значение BMI оказывается равным 31,1.
pd.pivot_table(df, values="BMI", index='Pregnancies',
columns=['Outcome'], aggfunc=np.mean)
Визуализация данных в pandas
Pandas предоставляет удобные обертки для функций построения графиков Matplotlib, которые позволяют легко визуализировать ваши DataFrames. Ниже мы рассмотрим, как с помощью pandas выполнять распространенные визуализации данных.
Линейные графики
Pandas позволяет строить графики взаимосвязей между переменными с помощью линейных диаграмм. Ниже показан линейный график зависимости индекса массы тела и глюкозы от индекса ряда.
df[['BMI', 'Glucose']].plot.line()
C помощью аргумента color можно указать цвета:
df[['BMI', 'Glucose']].plot.line(figsize=(20, 10),
color={"BMI": "red", "Glucose": "blue"})
df.plot.line(subplots=True)
Столбчатые диаграммы
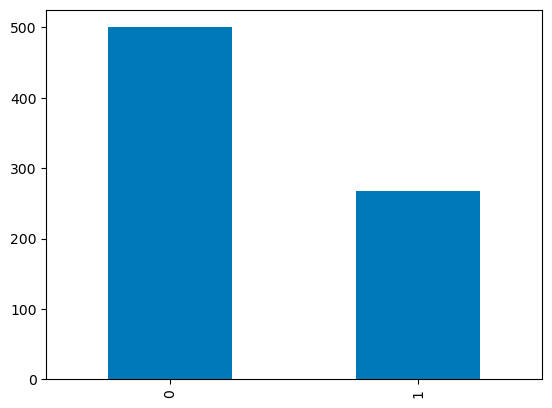
Для дискретных столбцов можно использовать гистограмму над количеством категорий для визуализации их распределения. Ниже представлена визуализация переменной Outcome с бинарными значениями.
df['Outcome'].value_counts().plot.bar()
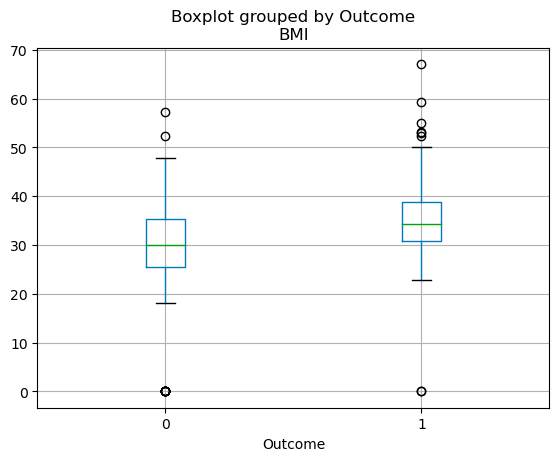
Усиковые диаграммы
Квартильное распределение непрерывных переменных может быть визуализировано с помощью усиковой диаграммы. Приведенный ниже код позволяет создать боксплот с помощью pandas.
df.boxplot(column=['BMI'], by='Outcome')
Pandas FAQs
Что такое pandas в Python?
Pandas — это мощная библиотека для работы с данными на языке Python. Она предоставляет структуры данных и функции, необходимые для работы со структурированными данными, в том числе функции для манипулирования датафреймами и их анализа. Это незаменимый инструмент в мире анализа данных и науки о данных, поскольку он позволяет эффективно очищать, преобразовывать и анализировать данные.
Зачем мне изучать pandas?
Если вы работаете с данными используя Python, то изучение pandas является практически обязательным. Он упрощает процесс обработки и анализа данных, позволяя сосредоточиться на извлечении информации. Независимо от того, работаете ли вы с небольшими наборами данных или с большими массивами, pandas облегчит вам жизнь благодаря своей скорости, гибкости и удобным структурам данных.
Как установить pandas?
Для установки pandas вам потребуется Python и pip (программа установки пакетов Python). Чтобы установить pandas, нужно ввести команду pip install pandas. Если вы используете блокнот Jupyter в среде, подобной Anaconda, pandas будет предустановлен.
Каковы основные структуры данных в pandas?
Две основные структуры данных в pandas — это Series и DataFrame. Серия — это, по сути, столбец, а DataFrame — это многомерная таблица, состоящая из набора серий. Эти структуры являются гибкими, то есть в них могут храниться данные различных типов (например, целое число, число с плавающей точкой, строка).
Подойдет ли pandas для работы с большими массивами данных?
Да, pandas является отличным выбором для работы с большими наборами данных. Он разработан для эффективного анализа данных, включая их большие массивы.
Однако следует помнить, что размер данных, с которыми вы можете работать, в некоторой степени зависит от объема памяти вашей системы. Если вы имеете дело с очень большими наборами данных, которые не помещаются в память, то вам, возможно, придется использовать другие инструменты или методы (например, разбиение на части или использование dask).
Как импортировать данные в pandas?
Pandas может читать данные из различных форматов файлов, таких как CSV, Excel, SQL-базы данных, JSON и многое другое. Для импорта данных из соответствующих типов файлов используются команды pd.read_csv(), pd.read_excel(), pd.read_sql() и pd.read_json(). Все эти команды возвращают объект DataFrame, с которым вы можете работать с помощью библиотеки pandas.
Заключение
Это руководство лишь поверхностно описывает возможности pandas. Будь то анализ данных, их визуализация, фильтрация или агрегирование, pandas предоставляет невероятно богатый набор функций, позволяющий ускорить любой процесс работы с данными. Более того, комбинируя pandas с другими пакетами для работы с данными, вы сможете создавать интерактивные информационные панели, строить прогностические модели на основе машинного обучения, автоматизировать рабочие процессы с данными и многое другое.
Перевод статьи «Python pandas tutorial: The ultimate guide for beginners».

