Работа с большими наборами данных в формате JSON может вызывать серьезные затруднения, особенно если эти наборы не помещаются в памяти. В подобных случаях эффективный способ для исследования и анализа таких данных можно найти, комбинируя инструкции командной строки и Python. В данной статье мы, делая прицел на изучения Python, посмотрим, как при помощи таких инструментов как Pandas изучить полицейскую деятельность в графстве Монтгомери, Мэриленд. Мы сначала посмотрим на данные в формате JSON, а затем перейдем к их анализу с помощью Python.
Хранящиеся в базе данных SQL данные имеют строгую структуру, которая похожа на таблицу. Вот пример из базы данных SQLite:
id|code|name|area|area_land|area_water|population|population_growth|birth_rate|death_rate|migration_rate|created_at|updated_at1|af|Afghanistan|652230|652230|0|32564342|2.32|38.57|13.89|1.51|2015-11-01 13:19:49.461734|2015-11-01 13:19:49.4617342|al|Albania|28748|27398|1350|3029278|0.3|12.92|6.58|3.3|2015-11-01 13:19:54.431082|2015-11-01 13:19:54.4310823|ag|Algeria|2381741|2381741|0|39542166|1.84|23.67|4.31|0.92|2015-11-01 13:19:59.961286|2015-11-01 13:19:59.961286
Как можно заметить, данные состоят из рядов и столбцов, причем каждый столбец соответствует определенной сущности или свойству, как например id, или code. В наборе данных из примера каждый ряд представляет собой определенную страну, а каждый столбец — определенный факт об этой стране.
Но количество собираемых нами данных стремительно возрастает и зачастую на момент сохранения этих данных мы не до конца понимаем их структуру. Такие данные называются неструктурированными. Хороший пример — это список действий посетителей сайта. Вот пример такого списка на сервере:
{'event_type': 'started-mission',
'keen': {'created_at': '2015-06-12T23:09:03.966Z',
'id': '557b668fd2eaaa2e7c5e916b',
'timestamp': '2015-06-12T23:09:07.971Z'},
'sequence': 1}
{'event_type': 'started-screen',
'keen': {'created_at': '2015-06-12T23:09:03.979Z',
'id': '557b668f90e4bd26c10b6ed6',
'timestamp': '2015-06-12T23:09:07.987Z'},
'mission': 1, 'sequence': 4, 'type': 'code'}
{'event_type': 'started-screen',
'keen': {'created_at': '2015-06-12T23:09:22.517Z',
'id': '557b66a246f9a7239038b1e0',
'timestamp': '2015-06-12T23:09:24.246Z'},
'mission': 1,
'sequence': 3,
'type': 'code'}
Как можно заметить, в данном списке есть три разных действия. Каждое действие имеет различные поля, и некоторые поля вложены друг в друга. Такой тип данных крайне сложно поместить в обычную SQL-базу данных. Как правило, для хранения неструктурированных данных используется формат JSON (JavaScript Object Notation). JSON — это удобный способ кодирования списков или словарей в строку таким образом, чтобы потом она была легко прочитана компьютером. Несмотря на то, что первое слово в аббревиатуре это Javasript, данный формат можно использовать в любом языке программирования.
Python имеет отличную поддержку формата JSON в собственной библиотеке json. С ее помощью мы можем как конвертировать списки и словари в формат JSON, так и наоборот — конвертировать строки в списки и словари. Вообще, данные JSON с их ключами и значениями выглядят точь-в-точь как словари в Python.
В данной статье мы сначала исследуем JSON-файл в командной строке, затем импортируем его в Python и будем работать с ним при помощи Pandas.
Набор данных
Мы будем изучать датасет, содержащий данные о дорожных нарушениях в графстве Монтгомери, штат Мэриленд. Загрузить датасет вы можете здесь. Эти данные содержат информацию о совершенном нарушении, автомобиле, человеке, совершившем нарушение, а также другую интересную информацию. Вот несколько вопросов, на которые мы хотели бы получить ответы, исследуя этот набор данных:
- Какой тип автомобиля наиболее часто останавливают за превышение скорости?
- Какие дни наиболее загружены у полиции?
- Насколько распространены «скоростные засады»? Или штрафы выписываются более-менее равномерно с точки зрения географии?
- За что как правило останавливают людей?
К сожалению, структура файла JSON нам наперед неизвестна. Таким образом, чтобы ее установить, нам нужно провести определенные исследования. Для это мы будем использовать Jupyter Notebook.
Исследование данных JSON
Хотя наш файл всего 600 Мб, мы будем относиться к нему, как будто он намного больше и не помещается целиком в оперативную память. Сначала мы посмотрим на несколько первых строк файла md_traffic.json. Так как JSON-файл — это обычный текстовый файл, мы можем использовать для этого обычную команду командной строки.
%%bash head md_traffic.json
{
"meta" : {
"view" : {
"id" : "4mse-ku6q",
"name" : "Traffic Violations",
"averageRating" : 0,
"category" : "Public Safety",
"createdAt" : 1403103517,
"description" : "This dataset contains traffic violation information from all electronic traffic violations issued in the County. Any information that can be used to uniquely identify the vehicle, the vehicle owner or the officer issuing the violation will not be published.\r\n\r\nUpdate Frequency: Daily",
"displayType" : "table",
Мы видим, что эти данные хорошо отформатированы и являются словарем. meta является ключом первого уровня. Этот ключ выделен двумя пробелами. При помощи команды grep мы можем получить таким образом все ключи первого уровня.
%%bash
grep -E '^ {2}"' md_traffic.json
"meta" : {
"data" : [ [ 1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050", 1455876689, "498050", null, "2016-02-18T00:00:00", "09:05:00", "MCP", "2nd district, Bethesda", "DRIVER USING HANDS TO USE HANDHELD TELEPHONE WHILEMOTOR VEHICLE IS IN MOTION", "355/TUCKERMAN LN", "-77.105925", "39.03223", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "MD", "02 - Automobile", "2010", "JEEP", "CRISWELL", "BLUE", "Citation", "21-1124.2(d2)", "Transportation Article", "No", "WHITE", "F", "GERMANTOWN", "MD", "MD", "A - Marked Patrol", [ "{\"address\":\"\",\"city\":\"\",\"state\":\"\",\"zip\":\"\"}", "-77.105925", "39.03223", null, false ] ]Отсюда видно, что в данных из файла md_traffic.json ключами верхнего уровня являются meta и data. Кажется, что список списков относится к ключу data и, вероятно, он и содержит все записи о транспортных происшествиях. Каждый внутренний список и является такой записью, и первая запись была выведена командой grep. Это очень похоже на структурированные данные, с которыми мы имем дело в CSV-файлах и таблицах SQL. Вот как эти данные могли бы выглядеть (в усеченном виде):
[ [1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050"], [1889194, "92AD0076-5308-45D0-BDE3-6A3A55AD9A04", 1889194, 1455876689, "498050"], ...]
Это очень похоже на ряды и столбцы, с которыми мы уже умеем работать. У нас только отсутствуют заголовки, которые бы сообщали, что в каждом из столбцов находится. Мы можем найти эту информацию по ключу meta.
Слово meta обычно обозначает информацию о самих данных. Давайте погрузимся в meta несколько глубже и посмотрим, какая информация там присутствует. После исполнения команды head мы знаем, что есть минимум три уровня ключей. meta содержит ключ view, который в свою очередь содержит ключи id, name, averageRating и другие. Мы можем распечатать полную структуру нашего файла JSON при помощи команды grep, выводя строки с количеством пробелов от 2 до 6.
%%bash
grep -E '^ {2,6}"' md_traffic.json
"meta" : {
"view" : {
"id" : "4mse-ku6q",
"name" : "Traffic Violations",
"averageRating" : 0,
"category" : "Public Safety",
"createdAt" : 1403103517,
"description" : "This dataset contains traffic violation information from all electronic traffic violations issued in the County. Any information that can be used to uniquely identify the vehicle, the vehicle owner or the officer issuing the violation will not be published.\r\n\r\nUpdate Frequency: Daily",
"displayType" : "table",
"downloadCount" : 105912,
"hideFromCatalog" : false,
"hideFromDataJson" : false,
"indexUpdatedAt" : 1565791377,
"newBackend" : true,
"numberOfComments" : 0,
"oid" : 32145791,
"provenance" : "official",
"publicationAppendEnabled" : false,
"publicationDate" : 1565795260,
"publicationGroup" : 1620779,
"publicationStage" : "published",
"rowsUpdatedAt" : 1594890614,
"rowsUpdatedBy" : "ajn4-zy65",
"tableId" : 16433971,
"totalTimesRated" : 0,
"viewCount" : 47566,
"viewLastModified" : 1565797518,
"viewType" : "tabular",
"approvals" : [ {
"columns" : [ {
"grants" : [ {
"metadata" : {
"owner" : {
"query" : {
"rights" : [ "read" ],
"tableAuthor" : {
"tags" : [ "traffic", "stop", "violations", "electronic issued." ],
"flags" : [ "default", "restorable", "restorePossibleForType", "unsaved" ]
"data" : [ [ "row-aqx6~tzah-4a2i", "00000000-0000-0000-908C-A6A938AE6B2E", 0, 1565791383, null, 1565792190, null, "{ }", "02ccadf1-7ebd-48d8-a793-913e3198f52a", "2019-07-30T00:00:00", "22:15:00", "MCP", "2nd District, Bethesda", "EXCEEDING THE POSTED SPEED LIMIT OF 35 MPH", "RIVER RD/ROYAL DOMINION DR", "38.9901016666667", "-77.151645", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", null, null, null, null, null, null, null, "VA", "02 - Automobile", "2014", "HONDA", "CIVIC", "BLACK", "Warning", "21-801.1", "Transportation Article", "False", "ASIAN", "F", "FAIRFAX", "VA", "VA", "Q - Marked Laser", "1", [ "{\"address\": \"\", \"city\": \"\", \"state\": \"\", \"zip\": \"\"}", "38.9901016666667", "-77.151645", null, false ], "1", "12", "103", "1" ]
Теперь мы видим полную структуру файла md_traffic.json и понимаем, какая часть в нем к чему относится. В частности, нас особенно интересует ключ columns , так как в нем скорей всего содержится информация о столбцах в списке списков, который находится по ключу data.
Получаем информацию о столбцах
Теперь, зная по какому ключу находится информация о столбцах, нам необходимо ее считать. Так как мы предполагаем, что наш файл не умещается в оперативной памяти, то мы не можем просто взять и считать его, используя библиотеку json. Вместо этого мы будем считывать его последовательно, экономя память.
Делать это мы будем при помощи пакета ijson, который будет итеративно парсить файл json вместо того, чтобы сразу считывать его в память. Это медленней, чем прямое чтение в память, но дает нам возможность работать с большими файлами, которые в память не помещаются. Работая с ijson, мы указываем имя файла, из которого мы хотим получить данные, а затем указываем полное имя ключа, по которому мы хотим получить информацию.
import ijson
filename = "md_traffic.json"
with open(filename, 'r') as f:
objects = ijson.items(f, 'meta.view.columns.item')
columns = list(objects)
В данном коде мы открываем файл md_traffic.json, а затем используем метод item из библиотеки ijson, чтобы извлечь из фала нужный нам список. Путь к нему мы указываем, используя следующую нотацию: meta.view.columns. Напоминаем, что meta — ключ верхнего уровня, он содержит ключ view, который в свою очередь содержит ключ columns. Затем мы указываем meta.view.columns.item, что означает, что мы хотим извлечь каждый элемент списка по ключу meta.view.columns. Метод items возвращает генератор, поэтому мы используем функцию list для преобразования его в список. Давайте выведем на экран первый элемент этого списка:
print(columns[0])
{'renderTypeName': 'meta_data', 'name': 'sid', 'fieldName': ':sid', 'position': 0, 'id': -1, 'format': {}, 'dataTypeName': 'meta_data'}
Отсюда видно, что каждый элемент в списке columns — это словарь, который содержит информацию о всех столбцах данных. Для получения названия столбца больше всего подходит ключ fieldName из этого словаря. Таким образом, чтобы получить названия всех столбцов, нам нужно извлечь значения по ключу fieldName из всех словарей списка columns:
column_names = [col["fieldName"] for col in columns]column_names
[':sid', ':id', ':position', ':created_at', ':created_meta', ':updated_at', ':updated_meta', ':meta', 'date_of_stop', 'time_of_stop', 'agency', 'subagency', 'description', 'location', 'latitude', 'longitude', 'accident', 'belts', 'personal_injury', 'property_damage', 'fatal', 'commercial_license', 'hazmat', 'commercial_vehicle', 'alcohol', 'work_zone', 'state', 'vehicle_type', 'year', 'make', 'model', 'color', 'violation_type', 'charge', 'article', 'contributed_to_accident', 'race', 'gender', 'driver_city', 'driver_state', 'dl_state', 'arrest_type', 'geolocation']
Великолепно! Теперь, зная названия всех столбцов, мы можем приступить непосредственно к извлечению самих данных.
Получение данных
Напоминаем, что сами данные находятся в списке списков по ключу data. Для работы с этими данными нам необходимо считать их в память. К счастью, мы можем использовать только что полученные имена столбцов, чтобы загрузить только те столбцы, которые представляют для нас интерес. Это сэкономит нам кучу памяти. Если бы набор данных был еще больше, его можно было бы считывать батчами. То есть, считывать сначала 1000000 рядов, обрабатывать их, затем еще 1000000 рядов, и так далее. В нашем случае мы сначала определяем интересные для нас столбцы и затем снова используем библиотеку ijson для итеративной обработки файла json.
good_columns = [
"date_of_stop",
"time_of_stop",
"agency",
"subagency",
"description",
"location",
"latitude",
"longitude",
"vehicle_type",
"year",
"make",
"model",
"color",
"violation_type",
"race",
"gender",
"driver_state",
"driver_city",
"dl_state",
"arrest_type"]
data = []
with open(filename, 'r') as f:
objects = ijson.items(f, 'data.item')
for row in objects:
selected_row = []
for item in good_columns:
selected_row.append(row[column_names.index(item)])
data.append(selected_row)
Теперь, считав данные, давайте выведем первый элемент переменной data на экран:
data[0]
['2016-02-18T00:00:00', '09:05:00', 'MCP', '2nd district, Bethesda', 'DRIVER USING HANDS TO USE HANDHELD TELEPHONE WHILEMOTOR VEHICLE IS IN MOTION', '355/TUCKERMAN LN', '-77.105925', '39.03223', '02 - Automobile', '2010', 'JEEP', 'CRISWELL', 'BLUE', 'Citation', 'WHITE', 'F', 'MD', 'GERMANTOWN', 'MD', 'A - Marked Patrol']
Передаем данные в Pandas
Теперь, когда у нас есть данные в виде списка списков и названия столбцов данных в виде отдельного списка, мы можем создать в Pandas для анализа этих данных DataFrame. Если вы не знакомы с библиотекой Pandas, то сообщаем, что эта библиотека использует для анализа очень удобный и эффективный табличный стиль представления данных под названием DataFrame. В Pandas можно конвертировать список списков в DataFrame, задав при этом отдельно названия столбцов.
import pandas as pd stops = pd.DataFrame(data, columns=good_columns)
Теперь, получив наши данные в виде датафрейма, мы можем их анализировать и получать интересные результаты. Вот, например, таблица, из которой видно, сколько раз останавливали машины определенного цвета.
stops["color"].value_counts()
BLACK 161319 SILVER 150650 WHITE 122887 GRAY 86322 RED 66282 BLUE 61867 GREEN 35802 GOLD 27808 TAN 18869 BLUE, DARK 17397 MAROON 15134 BLUE, LIGHT 11600 BEIGE 10522 GREEN, DK 10354 N/A 9594 GREEN, LGT 5214 BROWN 4041 YELLOW 3215 ORANGE 2967 BRONZE 1977 PURPLE 1725 MULTICOLOR 723 CREAM 608 COPPER 269 PINK 137 CHROME 21 CAMOUFLAGE 17 dtype: int64
Видим, что цвет камуфляж очень «популярен» у автомобилистов. А вот таблица, из которой видно, какое подразделение полиции чаще всего оформляет протокол.
stops["arrest_type"].value_counts()
A - Marked Patrol 671165 Q - Marked Laser 87929 B - Unmarked Patrol 25478 S - License Plate Recognition 11452 O - Foot Patrol 9604 L - Motorcycle 8559 E - Marked Stationary Radar 4854 R - Unmarked Laser 4331 G - Marked Moving Radar (Stationary) 2164 M - Marked (Off-Duty) 1301 I - Marked Moving Radar (Moving) 842 F - Unmarked Stationary Radar 420 C - Marked VASCAR 323 D - Unmarked VASCAR 210 P - Mounted Patrol 171 N - Unmarked (Off-Duty) 116 H - Unmarked Moving Radar (Stationary) 72 K - Aircraft Assist 41 J - Unmarked Moving Radar (Moving) 35 dtype: int64
Интересно, что несмотря на рост количества инфракрасных камер и лазерных радаров, патрульные автомобили все равно лидируют.
Преобразование столбцов
Мы подошли вплотную к тому, чтобы провести анализ данных на основе времени и координат, но для этого нам необходимо преобразовать данные столбцовlongitude, latitude, и date (долгота, широта и дата) из строковых значений в численные (типа float). Для преобразования долготы и широты мы будем использовать следующий код:
import numpy as np
def parse_float(x):
try:
x = float(x)
except Exception:
x = 0
return x
stops["longitude"] = stops["longitude"].apply(parse_float)
stops["latitude"] = stops["latitude"].apply(parse_float)
Несколько странно, что время дня и дата были сохранены в отдельные столбцы под названиями time_of_stop, and date_of_stop. Конвертируя эти данные, мы объединим их в один столбец.
import datetime
def parse_full_date(row):
date = datetime.datetime.strptime(row["date_of_stop"], "%Y-%m-%dT%H:%M:%S")
time = row["time_of_stop"].split(":")
date = date.replace(hour=int(time[0]), minute = int(time[1]), second = int(time[2]))
return date
stops["date"] = stops.apply(parse_full_date, axis=1)
Теперь мы можем построить диаграмму, из которой будет видно, в какой день недели полицейские останавливают автомобили наиболее часто.
import matplotlib.pyplot as plt %matplotlib inline plt.hist(stops["date"].dt.weekday, bins=6)
(array([ 112816., 142048., 133363., 127629., 131735., 181476.]), array([ 0., 1., 2., 3., 4., 5., 6.]), <a list of 6 Patch objects>)
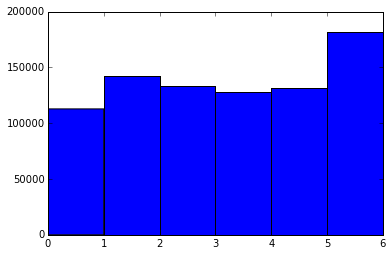
На данной диаграмме 0 — это понедельник, а 6 — воскресенье. Видно, что в понедельник наименьшее количество остановок, а в воскресенье — наибольшее. Однако, здесь есть проблема качества данных. По каким-то причинам неправильно записанные данные попали именно в воскресенье. Более детально разобраться в этом вопросе вы можете самостоятельно, проанализировав данные в столбце date_of_stop. Но этот вопрос выходит за рамки нашей статьи.
Мы также можем изобразить диаграмму, показывающую зависимость количества остановок от времени суток.
plt.hist(stops["date"].dt.hour, bins=24)
(array([ 44125., 35866., 27274., 18048., 11271., 7796., 11959., 29853., 46306., 42799., 43775., 37101., 34424., 34493., 36006., 29634., 39024., 40988., 32511., 28715., 31983., 43957., 60734., 60425.]), array([ 0. , 0.95833333, 1.91666667, 2.875 , 3.83333333, 4.79166667, 5.75 , 6.70833333, 7.66666667, 8.625 , 9.58333333, 10.54166667, 11.5 , 12.45833333, 13.41666667, 14.375 , 15.33333333, 16.29166667, 17.25 , 18.20833333, 19.16666667, 20.125 , 21.08333333, 22.04166667, 23. ]), <a list of 24 Patch objects>)
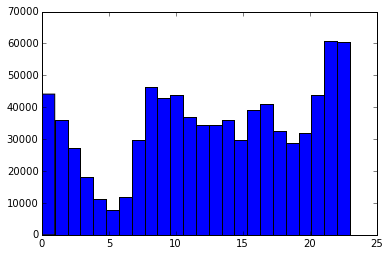
Отсюда видно, что чаще всего останавливают около полуночи, а реже всего — в районе 5 утра. Это имеет смысл, так как вечером люди возвращаются из баров и водитель может быть подшофе. Но и здесь может быть влияние качества данных, поэтому для более точного анализа необходимо проанализировать столбец time_of_stop.
Заключение
В данной статье, предназначенной для изучения программирования на языке Python, мы изучили, как из сырых данных в формате JSON получить полностью функциональную карту, используя при этом библиотеки ijson, Pandas, matplotlib.
Если вы и дальше хотите исследовать этот набор данных, то вот вам несколько интересных вопросов для изучения:
- Зависит ли вид нарушения от местоположения?
- Как доход коррелирует с количеством нарушений?
- Как плотность населения коррелирует с количеством нарушений?
- Какие типы нарушений характерны для полуночи?

