Ранее мы показывали, как парсить поисковые результаты Google, используя две библиотеки Python: requests и BeautifulSoup. А в этом руководстве мы применим несколько иной подход для веб-скрейпинга – с использованием библиотеки Selenium для Python. Затем результаты мы сохраним в файл CSV с помощью пакета pandas.
Код из этого примера доступен на GitHub.
Почему Selenium
Selenium – это фреймворк, разработанный для автоматизации тестирования веб-приложений. Мы можем написать на Python скрипт, автоматически контролирующий взаимодействия с браузером, например переходы по ссылкам и отправку форм. Но кроме того, Selenium будет очень полезен, если нам нужно собрать данные со страницы, содержание которой генерирует JavaScript. В этом случае данные отображаются после множества Ajax-запросов.
Впрочем, во многих случаях и BeautifulSoup, и scrapy отлично справляются с извлечением информации. Выбор библиотеки будет зависеть от того, как именно загружаются данные на конкретной странице, которую требуется парсить.
Чтобы определится с выбором и лучше понять работу Selenium, можно ознакомиться еще с двумя обзорами: здесь и здесь.
Подготовка
Мы будем использовать две библиотеки Python — Selenium и pandas. Чтобы установить их, просто запустите pip install selenium pandas.
Кроме того, потребуется драйвер браузера, чтобы симулировать браузерную сессию. В этом руководстве мы воспользуемся драйвером Chrome.
Загрузка драйверов
Начнем
В нашем примере извлекать данные будем из этого цитатника, специально созданного для упражнений в веб-скрейпинге. Достанем из него все цитаты с их авторами и сохраним их в CSV файл.
from selenium.webdriver import Chrome import pandas as pd webdriver = "путь_к_установленному_драйверу" driver = Chrome(webdriver)
Этот код импортирует драйвер Chrome и библиотеку pandas. А затем создает объект браузера при помощи driver = Chrome(webdriver). Обратите внимание, переменная webdriver указывает на исполняемый файл драйвера, который мы ранее загрузили для выбранного браузера. Если вы предпочитаете Firefox, импорт будет выглядеть вот так:
from selenium.webdriver import Firefox
Основной скрипт
pages = 10
for page in range(1, pages):
url = "http://quotes.toscrape.com/js/page/" + str(page) + "/"
driver.get(url)
items = len(driver.find_elements_by_class_name("quote"))
total = []
for item in range(items):
quotes = driver.find_elements_by_class_name("quote")
for quote in quotes:
quote_text = quote.find_element_by_class_name('text').text
author = quote.find_element_by_class_name('author').text
new = ((quote_text, author))
total.append(new)
df = pd.DataFrame(total, columns=['quote', 'author'])
df.to_csv('quoted.csv')
driver.close()
Изучив внимательнее URL сайта, обнаружим, что адрес для пагинации формируется следующим образом:
http://quotes.toscrape.com/js/page/{{номер_текущей_страницы}}/
Вооруженные этим знанием, мы создадим переменную pages с количеством страниц, которое мы собираемся обработать. В данном примере мы в цикле извлечем сведения всего из 10 страниц.
Команда driver.get(url) посылает HTTP-запрос к соответствующей странице. Дальше нам важно знать точное число объектов, которые мы получим с каждой страницы.
Приведу простое определение:
«Web scraping – это процесс извлечения информации с веб-страницы, пользуясь повторяющимися паттернами в исходном коде страницы».
Веб-скрейпинг позволяет собрать неупорядоченные данные в интернете и сохранить их в структурированном формате.
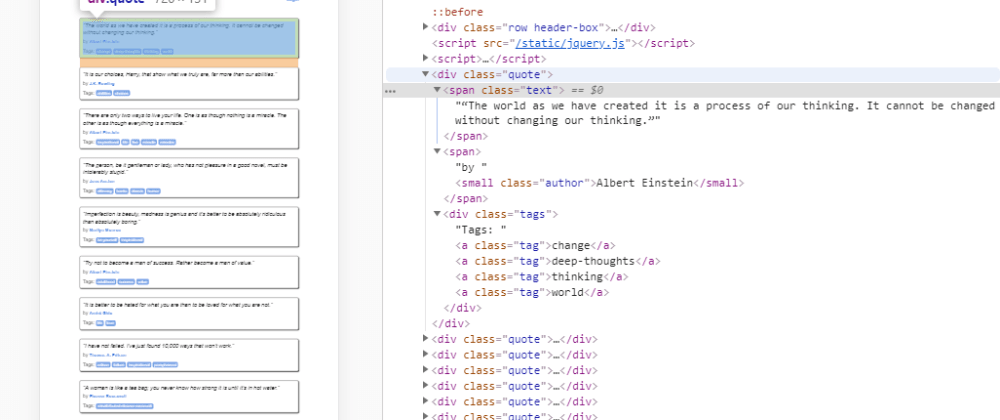
Осмотрев элементы с цитатами, замечаем, что каждый из них заключен в тег div, принадлежащий классу с названием ”quote”. При помощи вызова driver.get_elements_by_class("quote") мы получим все элементы, соответствующие этому шаблону.
Эту команду обернем в функцию len() и таким образом получим точное количество цитат на текущей странице. Сохраним его в переменную items, чтобы ограничить наш итератор.
Последний шаг
quotes = driver.find_elements_by_class_name("quote")
for quote in quotes:
quote_text = quote.find_element_by_class_name('text').text[1:]
author = quote.find_element_by_class_name('author').text
new = ((quote_text, author))
total.append(new)
В извлечении данных нам помогут вышеупомянутые паттерны в разметке страницы. Получим снова список всех цитат через уже использованный метод, но в этот раз не будем передавать его в функцию len(), так как нам нужны отдельные элементы.
Затем построим внутренний цикл, который итерирует по цитатам и извлекает каждую запись. Как видим на картинке выше, сами цитаты расположены в теге span с именем класса “text”. А автор помечен тегом small и классом “author” .
Наконец, поместим переменные quote_text и author в кортеж, который добавим в список под названием total.
df = pd.DataFrame(total,columns=['quote','author'])
df.to_csv('quoted.csv')
driver.close()
Теперь при помощи библиотеки pandas инициализируем dataframe для хранения всех записей (список total). Укажем названия для колонок: quote и author. И в завершение, экспортируем dataframe в CSV-файл, названный в нашем случае quoted.csv.
И не забудьте закрыть драйвер Chrome с помощью driver.close().
Дополнительные источники
1. Поиск элементов
Как вы заметили, мы пользовались в этом примере методом find_elements_by_class. Но это не единственный способ поиска элементов. В этом руководстве автор подробно объясняет, ка использовать другие селекторы.
Обработка WebElements в Selenium Python
2. Видео
Если вы предпочитаете уроки в формате видео, вам могут пригодиться вот эти материалы Lucid Programming.
3. Лучшие практики применения Selenium в Python
Теперь, смеем надеяться, вы тоже умеете делать простые веб-скрейперы на Python с Selenium ?. Успехов!

