Согласно словарю Ожегова, «жадный» — настойчивый в стремлении удовлетворить свое желание, выражающий это стремление; слишком падкий на что-нибудь. В информатике жадный алгоритм — это алгоритм, который находит решение проблемы за минимально возможное время. Он выбирает локально оптимальный путь, не обращая внимания на глобальную оптимальность решения.
Хотите скачать книги по Python в 2 клика? Тогда вам в наш телеграм канал PythonBooks
Содержание
- Жадные и нежадные алгоритмы
- Характеристики жадного алгоритма
- Как использовать жадные алгоритмы
- Жадный алгоритм в примерах
- Применение жадных алгоритмов
- Преимущества использования жадных алгоритмов
- Недостатки/ограничения использования жадных алгоритмов
Жадные и нежадные алгоритмы
Термин «жадный алгоритм» ввел информатик и математик Эдсгер Дейкстра. Он хотел вычислить минимальное остовное дерево. Роберт Прим и Джозеф Крускал придумали методы оптимизации для минимизации стоимости графов.
Алгоритм является жадным, когда выбранный путь рассматривается как наилучший вариант на основе определенного критерия без учета будущих последствий. Обычно он оценивает выполнимость, прежде чем принять окончательное решение. Правильность решения зависит от задачи и используемых критериев.
Давайте рассмотрим пример. Допустим, у вас есть граф с разными весами и вам нужно определить максимальное значение в дереве. Вы начнете с поиска узлов и проверки веса каждого, чтобы узнать, является ли его значение наибольшим.
Существует два подхода к решению этой проблемы: жадный и нежадный.
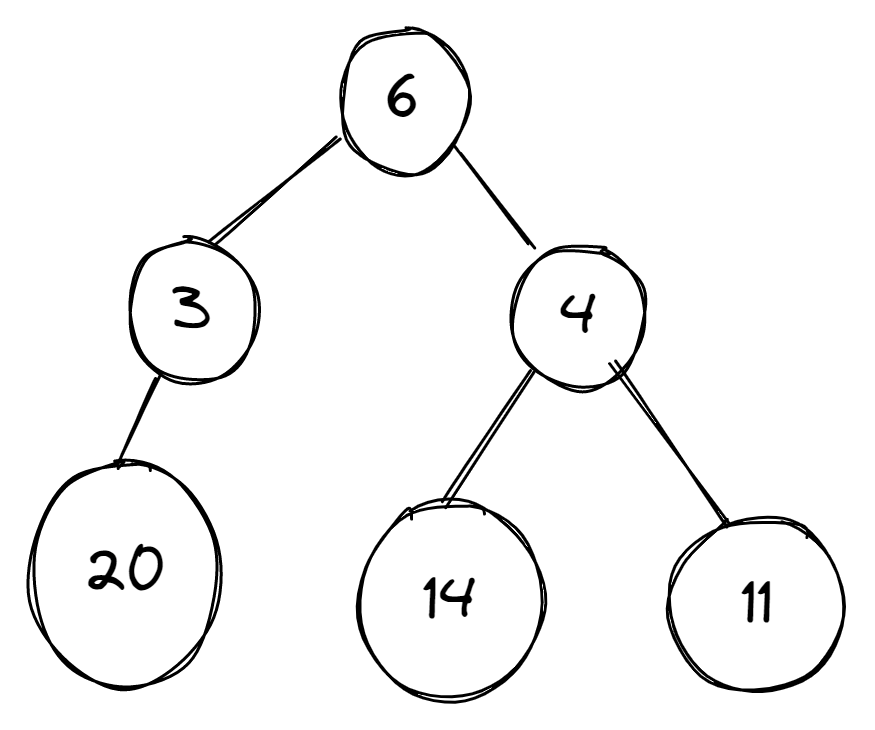
Этот граф состоит из различных весов, и нам нужно найти максимальное значение. Давайте попробуем применить оба подхода для поиска решения.
Жадный подход
На изображениях ниже граф имеет различные числа в своих вершинах. Алгоритм должен выбрать вершину с наибольшим числом.
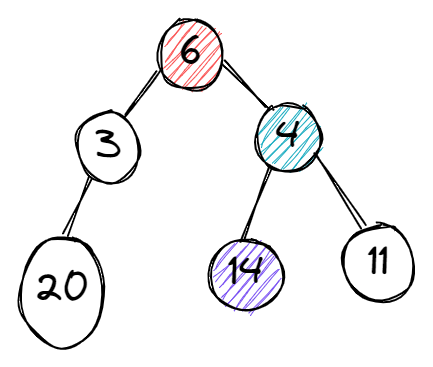
Обход начинается с вершины 6. Алгоритм сталкивается с выбором дальнейшего пути, нужно выбрать между 3 и 4. Он выбирает 4 как большее число. После этого ему снова нужно выбирать, теперь уже между 14 и 11. Он выбирает 14. На этом алгоритм завершается.
В графе есть вершина с большим значением — 20. Но она связана с вершиной 3, которую жадный алгоритм не считает лучшим выбором. Поэтому вершину 20 он не находит. На этом примере мы видим, как важно выбрать подходящие критерии для принятия каждого отдельного решения.
Нежадный подход
Нежадный подход проверяет все варианты, прежде чем прийти к окончательному решению, в отличие от жадного, который останавливается, как только получает результат.
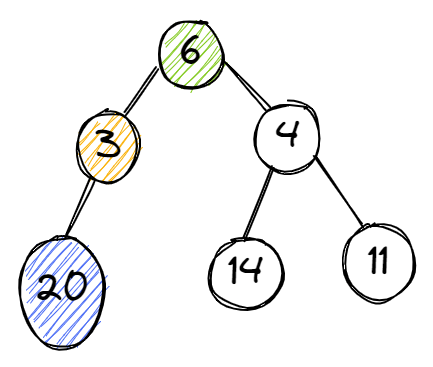
Начиная обход с вершины 6, алгоритм должен выбрать между 3 и4. Он выбирает 4, а затем выбирает между 14 и 11. Выбрав 14, алгоритм откладывает это значение.
Он повторяет процесс, снова начиная с вершины 6. Теперь алгоритм выбирает вершину с цифрой 3 и проверяет ее. К вершине 3 крепится вершина 20, на которой процесс останавливается. Теперь алгоритм сравнивает два результата: 20 и 14. 20 больше, поэтому выбирается вершина (3), которая в итоге приведет к наибольшему значению. На этом процесс завершается.
Этот подход при поиске наилучшего решения учитывает множество возможностей.
Характеристики жадного алгоритма
- Алгоритм решает задачу, находя оптимальное решение. Им может быть максимальное или минимальное значение. Алгоритм делает выбор, основываясь на наилучшем из доступных вариантов.
- Жадный алгоритм — быстрый и эффективный, с временной сложностью O(n log n) или O(n). Поэтому такие алгоритмы применяются при решении крупномасштабных задач.
- Поиск оптимального решения происходит без повторений: алгоритм запускается один раз.
- Жадный алгоритм прост, его легко реализовать.
Как использовать жадные алгоритмы
Прежде чем применить жадный алгоритм к задаче, необходимо задать себе два вопроса:
- Нужен ли вам вариант решения задачи, лучший на данный момент?
- Нужно ли вам оптимальное решение (минимальное или максимальное значение)?
Если ваш ответ на эти вопросы — «Да», то жадный алгоритм является хорошим выбором для решения вашей задачи.
Процедура
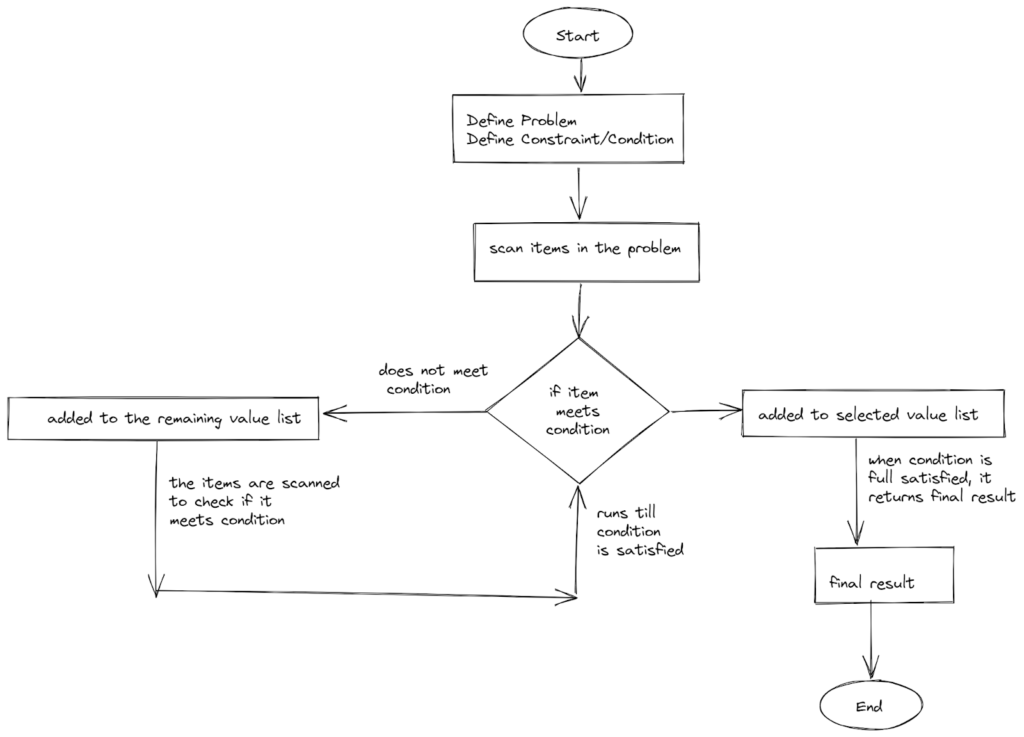
Предположим, у вас есть задача с набором чисел, среди которых нужно найти минимальное значение.
Начните с определения ограничения. В данном случае оно заключается в нахождении минимального значения.
Затем каждое число проверяется на каждое ограничение. Здесь ограничение выступает в роли условия, которое должно быть выполнено. Если условие истинно, число выбирается и возвращается в качестве окончательного решения.
Вот блок-схема этого процесса:
Жадный алгоритм в примерах
Проблема выбора занятий
У вас есть набор занятий или задач, которые необходимо выполнить. Каждое занятие (задача) имеет время начала и окончания. Алгоритм находит максимальное количество задач, которые можно выполнить за указанное время без их наложения друг на друга.
Подход к решению проблемы
У нас есть список занятий. У каждого из них есть время начала и окончания.
Сначала мы сортируем занятия по времени их окончания (в порядке возрастания). Затем выбираем первое занятие. Для хранения выбранного вида деятельности создаем новый список.
Чтобы выбрать следующее занятие, мы сравниваем время окончания последнего занятия со временем начала следующего. Если время начала следующего занятия больше времени окончания последнего, его можно выбрать. Если нет, мы пропускаем это занятие и проверяем следующее.
Этот процесс повторяется до тех пор, пока не будут проверены все задачи. Окончательное решение представляет собой список, содержащий занятия (задачи), которые могут быть выполнены за указанное время.
Давайте попробуем проделать все это на практике.
Практический пример
В таблице ниже показан список занятий, а также время их начала и окончания.
| Начальное время | Конечное время | Занятие/задача |
|---|---|---|
| 2 | 5 | Домашнее задание |
| 6 | 10 | Презентация |
| 4 | 8 | Курсовая работа |
| 10 | 12 | Тренировка по волейболу |
| 13 | 14 | Лекция по биологии |
| 7 | 15 | Встреча с друзьями |
Первым шагом является сортировка занятий по времени их окончания.
| Начальное время | Конечное время | Занятие/задача |
|---|---|---|
| 2 | 5 | Домашнее задание |
| 4 | 8 | Курсовая работа |
| 6 | 10 | Презентация |
| 10 | 12 | Тренировка по волейболу |
| 13 | 14 | Лекция по биологии |
| 7 | 15 | Встреча с друзьями |
Отсортировав занятия, мы выбираем первое и сохраняем его в списке избранных. В нашем примере первым видом деятельности является «Домашнее задание».
Время начала следующего занятия должно быть больше или равно времени окончания предыдущего.
Мы сопоставляем время окончания «Домашнего задания», которое было последним выбранным видом деятельности, и время начала «Курсовой работы». (4) меньше, чем (5), поэтому мы пропускаем «Курсовую работу» и переходим к следующему возможному занятию.
Время начала следующего занятия — «Презентации» — 6. Это больше, чем время окончания «Домашнего задания». Поэтому мы добавляем «Презентацию» в список избранных занятий.
Для следующего вида деятельности мы делаем ту же проверку. Время окончания «Презентации» — 10, время начала «Тренировки по волейболу» — 10. Мы видим, что время начала равно времени окончания, что удовлетворяет одному из условий. Поэтому мы выбираем это занятие и добавляем его в список избранных.
Идем дальше. Время окончания «Тренировки по волейболу» — 12, а время начала «Лекции по биологии» — 13. Время начала больше, чем время окончания, поэтому мы выбираем это занятие и вносим его в список.
И последнее возможное занятие — «Встреча с друзьями». Время его начала — 7, а время окончания нашей последней деятельности в списке — «Лекции по биологии» — 14. 7 меньше 14, поэтому мы не можем внести «Встречу с друзьями» в список избранных.
Поскольку задач больше не осталось, процесс завершается.
Наш конечный результат — это список избранных видов деятельности, которыми мы можем заняться без накладок по времени: «Домашнее задание», «Презентация», «Тренировка по волейболу», «Лекция по биологии».
Реализация решения в коде
В переменной data хранится время начала и окончания каждого вида деятельности, а также сам список занятий, из которых мы выбираем.
Переменная selected_activity — это пустой список, в котором будут храниться выбранные виды деятельности, которыми можно заняться по порядку и без накладок.
start_position показывает позицию первого занятия — индекс 0. Это будет наша начальная точка.
data = {
"start_time": [2 , 6 , 4 , 10 , 13 , 7],
"finish_time": [5 , 10 , 8 , 12 , 14 , 15],
"activity": ["Homework" , "Presentation" , "Term paper" , "Volleyball practice" , "Biology lecture" , "Hangout"]
}
selected_activity =[]
start_position = 0
Вот таблица датафрейма, показывающая исходные данные:
| start_time | finish_time | activity | |
| 0 | 2 | 5 | Homework |
| 1 | 6 | 10 | Presentation |
| 2 | 4 | 8 | Term paper |
| 3 | 10 | 12 | Volleyball practice |
| 4 | 13 | 14 | Biology lecture |
| 5 | 7 | 15 | Hangout |
Мы сортируем время окончания занятий в порядке возрастания и соответственно переставляем время начала и сами занятия. К переменным мы обращаемся, используя ключи в словаре.
tem = 0
for i in range(0 , len(data['finish_time'])):
for j in range(0 , len(data['finish_time'])):
if data['finish_time'][i] < data['finish_time'][j]:
tem = data['activity'][i] , data['finish_time'][i] , data['start_time'][i]
data['activity'][i] , data['finish_time'][i] , data['start_time'][i] = data['activity'][j] , data['finish_time'][j] , data['start_time'][j]
data['activity'][j] , data['finish_time'][j] , data['start_time'][j] = tem
В этом коде мы инициализировали tem в ноль. Для сортировки занятий по времени мы не используем встроенный метод. Вместо этого мы применяем два цикла. Переменные i и j представляют индексы. Мы проверяем, является ли значение data['finish_time'][i] меньшим, чем data['finish_time'][j].
Если это условие истинно, tem сохраняет значения элементов на позиции i и переставляет соответствующий элемент.
После этого мы выводим итоговый результат:
print("Start time: " , data['start_time'])
print("Finish time: " , data['finish_time'])
print("Activity: " , data['activity'])
# Results before sorting
# Start time: [2, 6, 4, 10, 13, 7]
# Finish time: [5, 10, 8, 12, 14, 15]
# Activity: ['Homework', 'Presentation', 'Term paper', 'Volleyball practice', 'Biology lecture', 'Hangout']
# Results after sorting
# Start time: [2, 4, 6, 10, 13, 7]
# Finish time: [5, 8, 10, 12, 14, 15]
# Activity: ['Homework', 'Term paper', 'Presentation', 'Volleyball practice', 'Biology lecture', 'Hangout']
А вот таблица датафрейма, показывающая отсортированные данные:
| start_time | finish_time | activity | |
| 0 | 2 | 5 | Homework |
| 1 | 4 | 8 | Term paper |
| 2 | 6 | 10 | Presentation |
| 3 | 10 | 12 | Volleyball practice |
| 4 | 13 | 14 | Biology lecture |
| 5 | 7 | 15 | Hangout |
После сортировки мы выбираем первое занятие — «Домашнее задание». Его начальный индекс равен 0, поэтому для обращения к этому занятию и добавления его в пустой список мы используем start_position.
selected_activity.append(data['activity'][start_position])
Условием выбора занятия является то, что время начала следующего должно быть больше, чем время окончания предыдущего. Если условие истинно, выбранное занятие добавляется в список selected_activity.
for pos in range(len(data['finish_time'])):
if data['start_time'][pos] >= data['finish_time'][start_position]:
selected_activity.append(data['activity'][pos])
start_position = pos
print(f"The student can work on the following activities: {selected_activity}")
# Results
# The student can work on the following activities: ['Homework', 'Presentation', 'Volleyball practice', 'Biology lecture']
Вот как это выглядит в целом:
data = {
"start_time": [2 , 6 , 4 , 10 , 13 , 7],
"finish_time": [5 , 10 , 8 , 12 , 14 , 15],
"activity": ["Homework" , "Presentation" , "Term paper" , "Volleyball practice" , "Biology lecture" , "Hangout"]
}
selected_activity =[]
start_position = 0
# sorting the items in ascending order with respect to finish time
tem = 0
for i in range(0 , len(data['finish_time'])):
for j in range(0 , len(data['finish_time'])):
if data['finish_time'][i] < data['finish_time'][j]:
tem = data['activity'][i] , data['finish_time'][i] , data['start_time'][i]
data['activity'][i] , data['finish_time'][i] , data['start_time'][i] = data['activity'][j] , data['finish_time'][j] , data['start_time'][j]
data['activity'][j] , data['finish_time'][j] , data['start_time'][j] = tem
# by default, the first activity is inserted in the list of activities to be selected.
selected_activity.append(data['activity'][start_position])
for pos in range(len(data['finish_time'])):
if data['start_time'][pos] >= data['finish_time'][start_position]:
selected_activity.append(data['activity'][pos])
start_position = pos
print(f"The student can work on the following activities: {selected_activity}")
# Results
# The student can work on the following activities: ['Homework', 'Presentation', 'Volleyball practice', 'Biology lecture']
Задача о рюкзаке
Рюкзак имеет некую предельную грузоподъемность и может вместить только ограниченное количество предметов. Все эти предметы имеют определенный вес и стоимость.
Задача состоит в том, чтобы заполнить ранец предметами, имеющими наибольшую суммарную стоимость, и при этом не превысить максимальный вес.
Подход к решению задачи
Необходимо рассмотреть два элемента: рюкзак и предметы. Рюкзак имеет максимальный вес и в него можно положить предметы с высокой стоимостью.
Сценарий. В ювелирном магазине есть изделия из золота, серебра и дерева. Золотые изделия самые дорогие, за ними по стоимости идут серебряные, а за ними деревянные. Если в магазин заберется вор, он постарается взять побольше золота, потому что так он получит наибольшую прибыль.
У вора есть рюкзак, в который он может положить украденные вещи. Но есть предел того, что вор может унести (вместимость рюкзака ограничена). Идея заключается в том, чтобы выбрать предметы, которые принесут наибольшую прибыль и поместятся в рюкзак, не превышая максимального веса.
- Первый шаг — найти соотношение стоимости и веса золота, серебра и дерева.
- Затем мы сортируем полученные коэффициенты в порядке убывания. Таким образом, мы можем сначала выбрать изделия с наибольшим отношением цены к весу, зная, что это даст наибольшую прибыль.
- Выбрав наибольший коэффициент, мы ищем соответствующий ему вес и добавляем изделия в ранец.
Есть условия, которые необходимо проверить.
Условие 1. Если вес добавленных изделий меньше, чем максимальная вместимость рюкзака, то добавляются еще изделия, пока суммарный вес всех предметов в рюкзаке не сравняется с максимально возможным.
Условие 2. Если суммарный вес предметов в рюкзаке больше, чем его максимальная вместимость, мы ищем, какую долю последних добавленных изделий можно вместить. Для этого делаем следующее:
Находим суммарный вес остальных предметов в рюкзаке. Он должен быть меньше максимальной вместимости.
Находим разницу между максимальной вместимостью рюкзака и суммарным весом оставшихся предметов и делим ее на вес последнего добавляемого предмета.
Fraction = (maximum capacity of the knapsack - sum of remaining weights) / weight of last item to be added
Чтобы узнать вес доли последнего предмета, которую можно добавить в рюкзак, мы умножаем его вес в целом на полученный коэффициент.
Weight_added = weight of last item to be added * fraction
После этого суммарный вес всех предметов будет равен максимальной вместимости рюкзака.
Практический пример
Допустим, максимальная вместимость ранца равна 17, а в наличии есть три предмета. Первый предмет — золотой, второй — серебряный, третий — деревянный.
Вес золотого — 10, серебряного — 6, деревянного — 2. Стоимость золотого — 40, серебряного — 30, деревянного — 6.
Соотношения стоимости к весу будут следующие:
- золото = 40/10 = 4
- серебро = 30/6 = 5
- дерево = 6/2 = 3
Располагаем коэффициенты по убыванию: 5, 4, 3.
Наибольшее соотношение — 5. Мы сопоставляем его с соответствующим весом — 6. Это вес серебра.
Мы кладем серебряные предметы в рюкзак и сравниваем их вес с максимальной вместимостью — 17. 6 меньше 17, поэтому можно добавить еще что-нибудь.
Возвращаемся к коэффициентам. Второй по величине — 4, он соответствует весу 10. Это золото.
Положим в рюкзак золотые изделия, сложим вес серебра и золота и сравним его с вместимостью рюкзака. 6 + 10 = 16. Видим, что суммарный вес предметов меньше максимальной вместимости. Значит, можно взять еще что-то.
Возвращаемся к списку коэффициентов и берем третий по величине — 3. Ему соответствует вес 2. Это дерево.
Когда мы добавим деревянные изделия в ранец, общий вес составит 6 +10 + 2 = 18. Это больше, чем максимальная вместимость рюкзака (17).
Мы убираем дерево из рюкзака, и у нас остаются золото и серебро. Их суммарный вес равен 16, а максимальная вместимость — 17. Чтобы заполнить рюкзак полностью, нам нужны изделия с общим весом 1.
Чтобы найти долю деревянных изделий, которые поместятся в рюкзак, применим условие 2, рассмотренное выше.
Теперь рюкзак заполнен.
Реализация решения в коде
В переменной data хранятся веса и стоимость всех предметов. Переменная maximum_capacity хранит максимальную вместимость рюкзака. selected_wt инциализируется в 0. В этой переменной будут храниться выбранные веса, которые будут помещены в рюкзак. Наконец, max_profit будет хранить стоимость выбранных весов, инициализируется в 0.
data = {
"weight": [10 , 6 , 2],
"profit":[40 , 30 ,6]
}
max_weight = 17
selected_wt = 0
max_profit = 0
Затем мы вычисляем отношение стоимости к весу:
ratio = [int(data['profit'][i] / data['weight'][i]) for i in range(len(data['profit']))]
Теперь, получив коэффициенты, мы располагаем элементы в порядке убывания. Затем соответственно сортируем элементы в weight и profit.
for i in range(len(ratio)):
for j in range(i + 1 , len(ratio)):
if ratio[i] < ratio[j]:
ratio[i] , ratio[j] = ratio[j] , ratio[i]
data['weight'][i] , data['weight'][j] = data['weight'][j] , data['weight'][i]
data['profit'][i] , data['profit'][j] = data['profit'][j] , data['profit'][i]
После того как вес и стоимость отсортированы, мы начинаем выбирать элементы и проверять условие. При помощи цикла for мы находим индекс каждого элемента в списке. Поскольку все элементы в ratio упорядочены по убыванию, первый элемент — это максимальное значение, а последний — минимальное.
for i in range(len(ratio)):
Первый элемент, который мы выбираем, имеет самый высокий коэффициент и находится под индексом 0. Выбрав первый вес, мы проверяем, меньше ли он максимального веса. Если да, то мы добавляем предметы до тех пор, пока общий вес не станет равным вместимости рюкзака. Второй выбранный нами предмет имеет второй по величине коэффициент и находится под индексом 1.
Каждый выбранный вес мы добавляем в переменную selected_wt, а соответствующую стоимость — в переменную max_profit.
if selected_wt + data['weight'][i] <= max_weight:
selected_wt += data['weight'][i]
max_profit += data['profit'][i]
Когда сумма выбранных весов в рюкзаке превысит максимальный вес, мы находим долю веса последнего добавленного элемента. Для этого нужно найти разницу между max_weight и суммой выбранных весов и разделить ее на вес последнего добавленного предмета.
Стоимость соответствующей доли последнего предмета добавляется к переменной max_profit. Затем мы возвращаем max_profit в качестве окончательного результата.
else:
frac_wt = (max_weight - selected_wt) / data['weight'][i]
frac_value = data['profit'][i] * frac_wt
max_profit += frac_value
selected_wt += (max_weight - selected_wt)
print(max_profit)
Сводим все воедино:
data = {
"weight": [10 , 6 , 2],
"profit":[40 , 30 ,6]
}
max_weight = 17
selected_wt = 0
max_profit = 0
# finds ratio
ratio = [int(data['profit'][i] / data['weight'][i]) for i in range(len(data['profit']))]
# sort ratio in descending order, rearranges weight and profit in order of the sorted ratio
for i in range(len(ratio)):
for j in range(i + 1 , len(ratio)):
if ratio[i] < ratio[j]:
ratio[i] , ratio[j] = ratio[j] , ratio[i]
data['weight'][i] , data['weight'][j] = data['weight'][j] , data['weight'][i]
data['profit'][i] , data['profit'][j] = data['profit'][j] , data['profit'][i]
# checks if selected weight with the highest ratio is less than the maximum weight, if so it adds it to knapsack and stores the profit, select the next item.
# else the sum of the selected weights is more than max weight, finds fraction
for i in range(len(ratio)):
if selected_wt + data['weight'][i] <= max_weight:
selected_wt += data['weight'][i]
max_profit += data['profit'][i]
else:
frac_wt = (max_weight - selected_wt) / data['weight'][i]
frac_value = data['profit'][i] * frac_wt
max_profit += frac_value
selected_wt += (max_weight - selected_wt)
print(f"The maximum profit that can be made from each item is: {round(max_profit , 2)} euros")
# Result
# The maximum profit that can be made from each item is: 73.0 euros
Применение жадных алгоритмов
Существуют различные области применения жадных алгоритмов. Вот некоторые из них:
- Минимальное остовное дерево — остовное дерево графа, имеющее минимальный возможный вес, где под весом дерева понимается сумма весов входящих в него рёбер.
- Кратчайший путь Дейкстры — это алгоритм поиска, который находит кратчайший путь между вершиной и другими вершинами во взвешенном графе.
- Задача коммивояжера — поиск кратчайшего маршрута, охватывающего различные места только единожды с возвратом в начальную точку.
- Код Хаффмана присваивает более короткий код часто встречающимся символам и более длинный код менее часто встречающимся символам. Используется для эффективного кодирования данных.
Преимущества использования жадных алгоритмов
Жадные алгоритмы довольно понятны и просты в реализации. Они также очень эффективны и имеют временную сложность O(N * logN).
Жадные алгоритмы, возвращающие максимальное или минимальное значение, полезны при решении задач оптимизации.
Недостатки/ограничения использования жадных алгоритмов
Несмотря на то, что жадные алгоритмы просты и полезны при решении задач оптимизации, они не всегда предлагают наилучшие решения.
Кроме того, жадные алгоритмы запускаются только один раз, а потому не проверяют правильность полученного результата.
Заключение
В этой статье мы рассмотрели некоторые примеры жадных алгоритмов и подходы к решению задач с их помощью. Разобравшись, как работает жадный алгоритм, вы сможете лучше понять динамическое программирование.
Перевод статьи «What is a Greedy Algorithm? Examples of Greedy Algorithms».

