Регулярные выражения (RegEx или RegExp) исключительно полезны для извлечения информации из текста посредством поиска совпадения (или нескольких совпадений) со специальными поисковыми шаблонами. Эти шаблоны представляют собой последовательности символов ASCII или Unicode.
Область применения RegEx варьируется от проверки строк до их анализа и замены. Поэтому регулярные выражения очень полезны при переводе данных в другие форматы и в веб-скрейпинге.
Одна из их наиболее интересных особенностей регулярных выражений заключается в том, что, изучив их синтаксис, вы можете реально использовать этот инструмент практически во всех языках программирования (JavaScript, Java, VB, C#, C / C ++, Python, Perl, Ruby, Delphi, R, Tcl и многие другие). Будут лишь небольшие отличия в поддержке наиболее продвинутых функций и в версиях синтаксиса.
Давайте разберем основные элементы регулярных выражений.
Базовые темы
Якоря — ^ и $
^The — соответствует любой строке, которая начинается с The.
end$ — соответствует строке, которая заканчивается на end.
^The end$ — точное строковое соответствие (при помощи такого шаблона можно найти строку «The end»).
Квантификаторы — * + ? и {}
Пример. Есть несколько групп символов:
abc ab acb aob a2b a42_c abccc
abc* — соответствует строке, в которой есть сочетание букв ab, за которым (возможно) есть один или несколько символов c.
abc+ — соответствует строке, в которой есть ab, за которым есть один или несколько символов c.
abc? — соответствует строке, в которой есть ab, за которым (возможно) есть один символ c.
abc{2} -соответствует строке, в которой есть ab, за которым есть два символа c.
abc{2,} — соответствует строке, в которой есть ab, за которым есть два или более символов c.
abc{2,5} — соответствует строке, в которой есть ab, за которым есть от двух до пяти символов c.
a(bc)* — соответствует строке, в которой есть символ a, за которым (возможно) есть одна или несколько последовательностей bc.
a(bc){2,5} — соответствует строке, в которой есть символ a, за которым есть от 2 до 5 копий последовательности bc.
Скобочные выражения — []
Пример. Есть несколько групп символов:
abc ab acb aob a2b a42_c abccc
[abc] — соответствует строке, в которой есть либо a, либо b, либо c. Аналогично шаблону a|b|c.
[a-c] — то же самое, что и в предыдущем случае.
[0-9]% — строка, в которой перед знаком % есть символы от 0 до 9.
[^a-zA-Z] — строка, в которой нет букв от a до z или от A до Z. В данном случае ^ использован как отрицание выражения.
Классы символов — \d \w \s и .
Пример. Есть несколько групп символов:
abc ab acb aob a2b a42_c abccc
\d — соответствует единичному цифровому символу.
\w — соответствует словарному символу (алфавитно-цифровому символу плюс нижнее подчеркивание).
\s — соответствует пробельному символу (включая табуляцию и разрыв строки).
Жадное и ленивое соответствие
<.+?> — соответствует любому символу, один или более раз включенному внутрь <>. Поиск расширяется по мере необходимости (ленивое соответствие)
<[^<>]+> — соответствует любому символу, за исключением символов < или >, один или более раз включенных внутрь <>.
Теперь давайте разберем четыре регулярных выражения с конкретными практическими примерами.
1. Проверка соответствия для имени пользователя

Шаблон:
/^[a-z0-9_-]{3,16}$/
Описание:
В начале мы велим парсеру найти начало строки (^), за которым следуют любая строчная буква (a-z), число (0–9), знак подчеркивания или дефис. Затем выражение {3,16} проверяет, что символов не меньше 3 и не больше 16. И в конце мы ищем конец строки $.
Подходящая строка:
my-us3r_n4m3
Неподходящая строка:
th1s1s-wayt00_l0ngt0beausername(слишком длинная)
2. Проверка соответствия для пароля

Шаблон:
/^[a-z0-9_-]{6,18}$/
Описание:
Проверка соответствия пароля очень похожа на проверку имени пользователя. Единственное отличие состоит в том, что вместо требования количества символов (букв, цифр, нижнее подчеркивание и дефис) от 3 до 16, теперь мы требуем от 6 до 18 {6, 18}.
Подходящая строка:
myp4ssw0rd
Неподходящая строка:
mypa$$w0rd (содержит значок доллара $)
3. Проверка соответствия для URL-слагов
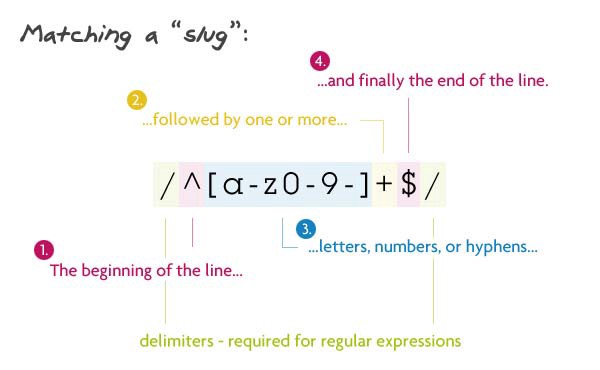
Шаблон:
/^[a-z0-9-]+$/
Описание:
Данное регулярное выражение вам пригодится при работе с mod_rewrite и «красивыми» URL. Вначале мы велим парсеру найти начало строки (^), за которым следует один или более (знак +) символ буквы, цифры или дефиса. И в конце мы хотим увидеть конец строки ($).
Подходящая строка:
my-title-here
Неподходящая строка:
my_title_here (содержит нижние подчеркивания)
4. Проверка соответствия для Email-адресов
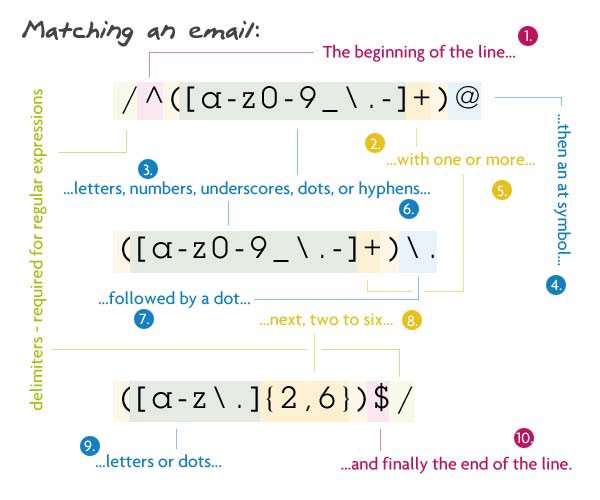
Шаблон:
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
Описание:
Вначале мы даем указание парсеру искать начало строки. Внутри первой группы мы проверяем соответствие одного или более символов букв в нижнем регистре, чисел, нижних подчеркиваний, точек или дефисов. Знак точки мы экранировали, так как иначе он обозначает любой символ. Непосредственно после этого должен быть символ @.Затем идет имя домена: один или более символов букв в нижнем регистре, чисел, нижних подчеркиваний, точек или дефисов. Затем еще одна (экранированная) точка и после нее расширение, состоящее из букв и точек в количестве от 2 до 6. Мы взяли такое количество, потому что домены верхнего уровня могут быть весьма специфическими (например .ny.us или .co.uk). И далее мы хотим видеть конец строки ($).
Подходящая строка:
john@doe.com
Неподходящая строка:
john@doe.something (домен верхнего уровня слишком длинный)

