В данной статье мы расскажем, как представление списков (list comprehension) работает в Python. Будет приведено много примеров, чтобы вы могли хорошо познакомиться с этой важной концепцией и применять ее на практике в своих проектах.
Что такое представление списков
Python — это объектно-ориентированный язык. Практически все, что в нем есть, может рассматриваться как объект. Однако, в нем есть все необходимые возможности для функционального программирования. Чтобы понять, что это такое, давайте вспомним математику, где функция, принимая несколько раз одно и то же значение, дает всегда один и тот же результат. Например, функция f(x) = x2 при одном и том же x будет всегда давать один и тот же результат. Функции в Python не имеют побочного эффекта, что означает, что работа функции никак не влияет на переменные, которые находятся вне зоны видимости данной функции. Это свойство дает нам возможность не допускать так называемых «утечек данных», когда переменные или структуры данных изменяемого типа меняются нежелательным для нас образом.
Функциональное программирование также отлично подходит для параллельных вычислений, поскольку не дает одновременного доступа к данным.
Представление списков — это часть функционального программирования, которая предоставляет нам ясный способ создавать списки без написания полноценного цикла.

На рисунке выше оператор for производит итерацию по каждому элементу списка list. Оператор if производит фильтрацию списка list и оставляет только те элементы, которые отвечают условию condition. Оператор if является необязательным: если фильтрация не нужна, он не используется.
Рассмотрим выражение [i**3 for i in [1, 2, 3, 4] if i > 2]. Здесь производится итерация по списку [1,2,3,4] и каждый элемент списка проверяется условием i > 2. Если оно выполняется, то данный элемент возводится в степень 3 (i**3 ), и из таких элементов формируется новый список. Результат: [27, 64].
Представление списков в сравнении с обычным циклом for и конструкцией lambda + map().
Рассмотрим три разных способа производить итерацию списков в Python. Они соответствуют разным стилям программирования, но приводят к одинаковому результату.
Представление списков более читаемое и удобное, чем остальные
| Представление списков | Цикл for |
lambda + map() |
[i**2 for i in range(2, 10)]
|
sqr = []
for i in range(2,10):
sqr.append(i**2)
sqr
|
list(map(lambda i: i**2, range(2, 10)))
|
Результат: [4, 9, 16, 25, 36, 49, 64, 81]
В представлении списков производится операция цикла и затем формируется новый список. Все это выражено в одной строчке кода, что удобнее, чем два других варианта.
В цикле for функция range(2, 10) возвращает последовательность от 2 до 9 включительно ( 10 не входит). **2 означает возведение в степень 2. Выражение sqr = [] создает пустой список, а функция append() добавляет в него элементы при каждой итерации цикла for.
Функция map() применяет lambdaфункцию к каждому члену итерируемой последовательности. Чтобы получить в результате список, эту функцию надо также обернуть в функцию list()( Прим. переводчика — если этого не делать, то на выходе будет обычный генератор).
Представление списков несколько быстрее, чем другие способы
Мы провели небольшой эксперимент, сравнив скорость вычислений всех трех вариантов кода. Мы вычисляли квадрат каждого значения последовательности от 1 до 10 миллионов при условии, что он является четным числом, то есть нацело делится на 2.
Это проверяет оператор if. Например, 5 % 2 дает нам в результате 1, это остаток от целочисленного деления 5 на 2. А когда остаток равен 0, это означает, что число четное.
| Представление списков | Цикл for |
lambda + map() |
l1= [x**2 for x in range(1, 10**7) if x % 2 == 0] # Время работы: 3.96 seconds |
sqr = []
for x in range(1, 10**7):
if x%2 == 0:
sqr.append(x**2)
# Время работы: 5.46 seconds |
l0 = list(map(lambda x: x**2, filter(lambda x: x%2 == 0, range(1, 10**7)))) # Время работы: 5.32 seconds |
Функция filter(lambda x: x%2 == 0, range(1, 10**7)) возвращает все четные числа от 1 до 10 миллионов. Грубо говоря, функция filter() работает, как инструкция WHERE в SQL.
Представление списков: конструкция if - else
В данном примере мы хотим преобразовать список строк следующим образом: если строка содержит более четырех символов, мы приводим ее к верхнему регистру при помощи функции upper( ), в противном случае мы приводим строку к нижнему регистру функцией lower().
| Представление списков | Цикл for |
mylist = ['Dave', 'Micheal', 'Deeps'] [x.upper() if len(x)>4 else x.lower() for x in mylist] |
k = []
for x in mylist:
if len(x) > 4:
k.append(x.upper())
else:
k.append(x.lower())
k
|
Фильтрация словарей при помощи представления списков
Предположим, у вас есть словарь, и вы хотите выбрать определенные ключи и конкретные значения. Иными словами, вы хотите при помощи условного оператора if выбрать некое подмножество или, попросту говоря, отфильтровать словарь. Возьмем для примера следующий словарь:
d = {'a': [1,2,1], 'b': [3,4,1], 'c': [5,6,2]}
Фильтрация словаря по значениям
Сейчас мы выберем все значения по ключу ‘b’, которые больше 2.
[x for x in d['b'] if x >2]
Результат:
[(3, 4)]
Фильтрация словаря по нескольким условиям
Теперь усложним условие. Давайте выберем только те элементы, где значения по ключу 'a' равны 1, а по ключу 'b' — больше 1.
[(x,y) for x, y in zip(d['a'],d['b']) if x == 1 and y > 1]
Результат:
[(1, 3)]
В приведенном коде x относится к d['a'], а y — к d['b'].
Фильтрация словаря с использованием функций all() и any()
Функция all() проверяет условие (или несколько условий) для всех элементов списка и возвращает либо True, либо False.
[(k,v) for k,v in d.items() if all(x > 1 for x in v) ]
Здесь k относится к ключам словаря, а v — к значениям.
Результат:
[('c', [5, 6, 2])]
Только у ключа 'c' все значения больше 1.
Аналогичным образом мы можем использовать функцию any(), которая возвращает значение True, если хоть один элемент списка отвечает заданным условиям.
[(k,v) for k,v in d.items() if any(x > 2 for x in v) ]
Результат:
[('b', [3, 4, 1]), ('c', [5, 6, 2])]
Используем представление списков в Pandas
Обычно в нашей жизни все данные хранятся (либо могут быть сохранены) в формате csv или в реляционной базе данных. Такие данные очень удобно преобразовать (для очистки и других манипуляций с ними) в формат DataFrame библиотеки pandas. Поэтому очень важно научиться использовать представления списков вместе с этим популярным форматом.
Предположим, у нас есть данные сотрудников с их именами и зарплатами, текущими и предыдущими. Давайте создадим датафрейм, чтобы проиллюстрировать такую ситуацию.
import pandas as pd
df = pd.DataFrame({'name': ['Sandy', 'Sam', 'Wright', 'Atul'],
'prevsalary': [71, 65, 64, 90],
'nextsalary': [75, 80, 61, 89]})
df
Результат:
name prevsalary nextsalary 0 Sandy 71 75 1 Sam 65 80 2 Wright 64 61 3 Atul 90 89
Допустим, мы хотим создать колонку под названием ‘Flags', которая может содержать две метки: либо 'High Bracket', либо 'Low Bracket'. Если значение в колонке prevsalary будет больше 70, нужно поставить метку 'High Bracket', в противном случае — 'Low Bracket'. Код, приведенный ниже, создаст колонку в нашем датафрейме по такому правилу:
df['Flag'] = ["High Bracket" if x > 70 else "Low Bracket" for x in df['prevsalary']]
Результат:
name prevsalary nextsalary Flag 0 Sandy 71 75 High Bracket 1 Sam 65 80 Low Bracket 2 Wright 64 61 Low Bracket 3 Atul 90 89 High Bracket
Операции с несколькими колонками
Допустим, нам нужно сравнить две переменные, значения которых содержатся в колонках prevsalary и nextsalary. Если prevsalary > nextsalary, то в результате имеем "Increase", в противном случае — "Decrease". Эти результаты сохраним в новую колонку под названием 'Flag2'.
df['Flag2'] = ["Increase" if x > y else "Decrease" for (x, y) in zip(df['nextsalary'], df['prevsalary'])]
Результат:
name prevsalary nextsalary Flag Flag2 0 Sandy 71 75 High Bracket Increase 1 Sam 65 80 Low Bracket Increase 2 Wright 64 61 Low Bracket Decrease 3 Atul 90 89 High Bracket Decrease
В представлении списка были созданы две локальные переменные x = df['nextsalary'], y = df['prevsalary'].
Преобразование символов в числа
Предположим, у вас есть колонка, которая содержит числовые значения, но они хранятся в строковом формате. Это распространенная ситуация, когда вы импортируете данные из онлайн-портала или из базы данных. Давайте для примера создадим датафрейм с такого типа данными.
import pandas as pd
df = pd.DataFrame({"col1" : ['1', '2', '3']})
Теперь приведем данные к числовому формату и сохраним их в колонке под названием 'col2'.
df['col2'] = [int(x) for x in df['col1']]
Теперь наши колонки имеют следующий тип данных:
col1 object col2 int64
Такой же результат может быть получен и без использования представления списков: при помощи встроенной в библиотеку pandas функции. (Прим. переводчика: надо сказать, что в библиотеке pandas есть функции на все случаи жизни.)
df['col2'] = df['col1'].astype(int)
Вложенные представления списков
Это эквивалентно вложенным циклам for. Стандартный синтаксис для вложенного представления списков будет следующим:
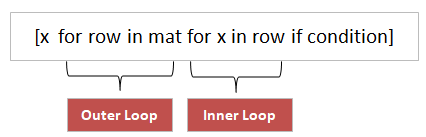
Предположим, что у нас есть список списков и нам необходимо выбрать только нечетные числа. Напоминаем, что нечетными называются числа, которые не делятся на 2 нацело.
| Представление списков | Цикл for |
mat = [[1,2], [3,4], [5,6]] [x for row in mat for x in row if x%2 == 1] |
b = []
for row in mat:
for x in row:
if x%2 == 1:
b.append(x)
b
|
Если вы посмотрите на синтаксис, то увидите что он очень схож.
Результат:
[1, 3, 5]
Представление списков со словарями внутри
Пусть у нас есть список, который содержит внутри себя несколько словарей. И мы хотим отфильтровать значения и выбрать определенные ключи.
mylist = [{'a': 1, 'b': 2}, {'a': 3, 'b': 4}, {'a': 5, 'b': 6}]
В следующем коде мы выбираем только данные с ключом ‘a’ и больше 1.
[i['a'] for i in mylist if 'a' in i if i['a'] > 1]
Результат:
[3, 5]
Как создать кортежи из списков
Сейчас мы с помощью представления списков составим все возможные комбинации элементов двух списков. Они будут объедены в кортежи по одному элементу из каждого списка, а эти кортежи будут в свою очередь составлять список.
l1 = ['a','b'] l2 = ['c','d'] [(x,y) for x in l1 for y in l2]
Результат:
[('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd')]
Как при помощи преставления списков составить из предложения массив (список) слов
В задачах по обработке текстов одним из первоочередных шагов является разбивка предложения на слова. Перед этим надо обязательно привести все слова в предложении к одному регистру (верхнему или нижнему), чтобы в массиве не оказалось одинаковых слов.
text = ["Life is beautiful", "No need to overthink", "Meditation help in overcoming depression"]
Вот код, который выполняет эту задачу:
[word for sentence in text for word in sentence.lower().split(' ')]
Результат:
['life', 'is', 'beautiful', 'no', 'need', 'to', 'overthink', 'meditation', 'help', 'in', 'overcoming', 'depression']
Как это работает?
- Выражение
for sentence in textпроизводит итерацию по каждому предложению в спискеtext. - Выражение
text[0].lower().split(' ')приводит все символы к нижнему регистру и затем разбивает предложение на слова. Так данное выражение дает нам в результате следующий список:['life', 'is', 'beautiful'].
Упражнения для практики
Следующие упражнения помогут вам получить собственный опыт и закрепить полученные знания.
- Удалите слова
is, in, to, noиз спискаtext. Ожидаемый результат должен выглядеть следующим образом:
['life', 'beautiful', 'need', 'overthink', 'meditation', 'help', 'overcoming', 'depression']
- Найдите совпадающие числа в следующих списках:
x = [51, 24, 32, 41] y = [42, 32, 41, 50]
Ожидаемый результат: [32, 41]
- если число из списка находится между 30 и 45, выводите 1, в противном случае — 0
x = [51, 24, 32, 41]
Ожидаемый результат: [0, 0, 1, 1]

