
Мы уже разбирали, что такое связный список и как его реализовать на Python. Вероятно, вы тогда подумали, что это все, конечно, хорошо, но зачем? Разве нельзя просто использовать обычный список Python? Хороший вопрос.
Дело в том, что мы пока только реализовали связный список, но ничего с ним не делали. Давайте забудем ненадолго об обычных списках Python и подумаем о массивах.
Во многих объектно-ориентированных языках (например, в Java), массивы имеют фиксированную длину. Это означает, что если вы захотите добавить или уменьшить пространство, вам нужно будет сделать новый массив и перенести в него содержимое из старого. Для наглядности представьте, что у вас есть трехкомнатная квартира. Вам по какой-то причине потребовалась четвертая комната, поэтому вам приходится паковать вещи и переезжать в четырехкомнатную квартиру.
Вернемся к спискам. Списки в Python — не настоящие массивы, а реализация динамических массивов. Их производительность отличается и от связных списков, и от массивов (больше информации здесь). Но связными списками проще манипулировать, по крайней мере по сравнению со старыми массивами. Чтобы добавить новый узел, вам не нужно создавать новый список: можно просто создать сам узел и изменить указатели от других узлов.
Давайте разберем задачу:
Напишите код для удаления дубликатов из несортированного связного списка.
Прежде всего нам понадобится класс Node из прошлой статьи. С его помощью мы сможем создать сам связный список, прежде чем начать что-то менять в нем. Вот код:
class Node:
def __init__(self, data):
self.next = None
self.data = data
def append(self, val):
end = Node(val)
n = self
while (n.next):
n = n.next
n.next = end
Начнем с определения метода для удаления дубликатов. Он будет принимать один параметр — первый узел в списке. Назовем этот узел front.
def remove_dups(front):
pass
Теперь давайте подумаем, как бы мы решили эту задачу, будь у нас обычный список Python. Мы бы сохраняли число вхождений каждого значения и, натыкаясь на какое-то повторяющееся значение, удаляли бы его. Вероятно, вы подумали об использовании словаря для этих целей. Мы будем использовать дефолтный словарь.
defaultdict — объект в коллекциях Python, позволяющий задавать значениям в словаре тип по умолчанию. Мы можем установить тип как булево значение: если ключ не имеет предыдущего значения, тип автоматически установится как False. Итак, давайте импортируем и инициализируем наш словарь. Назовем его counted, поскольку он представляет то, видели ли мы прежде каждое из значений.
from collections import defaultdict
def remove_dups(front):
counted = defaultdict(bool)
Теперь нам нужно сделать итератор для обхода списка. В предыдущей статье мы делали отдельный узел, указывающий на каждый узел в списке, «обходя» его. Благодаря этому список оставался нетронутым. Ниже вы видите полезную гифку от GeeksForGeeks, где указатель обходит связный список и удаляет последний узел.
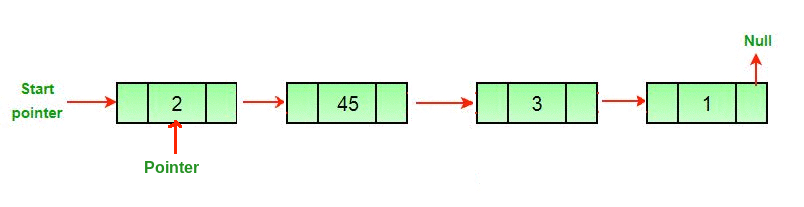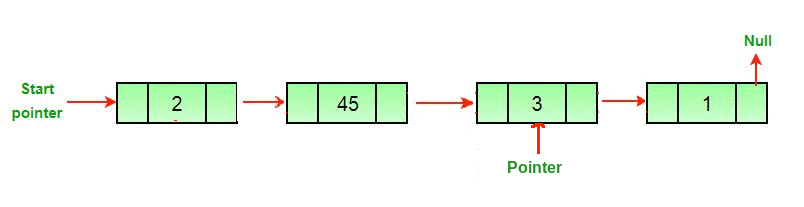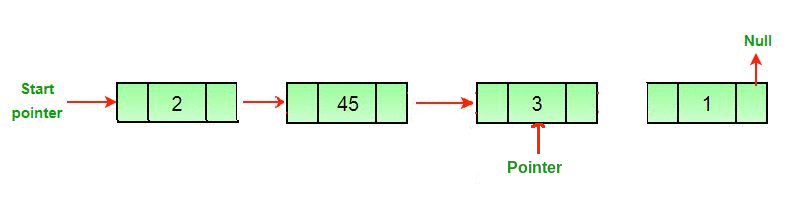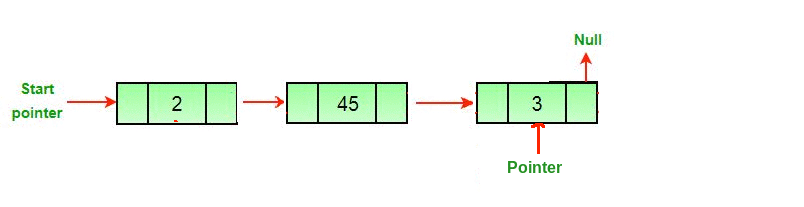
Итак, давайте сделаем наш указатель. Мы можем назвать его традиционно — temp.
temp = front
Теперь давайте поговорим об обходе. Мы можем проверить значение первого узла, затем перейти ко второму и проверить его значение, и так далее. Но есть одна проблема. Что, если узел, который мы проверяем, имеет значение-дубликат? Мы можем изменить только его указатель next, но не указатель, который идет перед ним. Поэтому мы будем просматривать значение каждого следующего узла (next), и если окажется, что это — дубликат, мы установим temp.next как None.
Допустим, у нас такой список:
[1] --> [1] --> [2]
Мы начинаем с того, что помещаем значение первого узла — 1 — в словарь counted.
counted[temp.data] = True
Далее, все еще указывая на первый узел, мы проверяем значение temp.next. Поскольку значение этого узла — дубликат, его нужно удалить. Поэтому мы назначаем temp.next узлом после этого узла: temp.next = temp.next.next.
counted[temp.data] = True
while (temp.next):
# проверяем значение следующего узла
if (counted[temp.next.data]):
# если значение найдено в словаре, удаляем его
temp.next = temp.next.next
Если значение temp.next в counted не True, мы устанавливаем его как True. Затем нам нужно перейти на следующий узел, установив temp = temp.next.
counted[temp.data] = True
while (temp.next):
# проверяем значение следующего узла
if (counted[temp.next.data]):
# если значение найдено в словаре, удаляем его
temp.next = temp.next.next
else:
counted[temp.next.data] = True
temp = temp.next
Вот и все! Наш метод целиком:
from collections import defaultdict
def remove_dups(front):
counted = defaultdict(bool)
temp = front
counted[temp.data] = True
while (temp.next):
# проверяем значение следующего узла
if (counted[temp.next.data]):
# если значение найдено в словаре, удаляем его
temp.next = temp.next.next
else:
counted[temp.next.data] = True
temp = temp.next
Проверяем наш метод
Давайте посмотрим, как наш метод работает. Начнем с создания связного списка и добавления в него каких-нибудь чисел.
ll = Node(1) ll.append(2) ll.append(3) ll.append(3) ll.append(1) ll.append(4)
Если вы хотите увидеть связный список, вам нужно обойти его, выводя значение каждого узла. Мы это делали в прошлой статье, но приведем код еще раз:
node = ll
print(node.data)
while node.next:
node = node.next
print(node.data)
Этот код выведет 1, 2, 3, 3, 1, 4.
Теперь, когда у нас есть наш список, давайте вызовем для него метод для удаления дубликатов. Вы помните, что мы передаем в метод первый узел списка, в нашем случае — ll.
remove_dups(ll)
Если все пройдет гладко, то при следующем выводе списка у нас уже не будет лишних 1 и 3, то есть в выводе мы получим 1, 2, 3, 4.
Возможно, вам по-прежнему непонятно, зачем это учить. Связные списки — это своего рода пережиток традиционной информатики. Но если вы хотите разобраться в более сложных структурах, таких как двоичные деревья, связные списки — хорошее подспорье. А если вы умеете реализовывать собственные связные списки, вы можете модифицировать их, чтобы получить кастомные методы для специфических нужд. Например, связный список можно использовать для реализации простого блокчейна. Да, вы не ослышались! Блокчейн — это, по сути, очень усложненный связный список.
