
Давайте поговорим немного о связных списках. Вероятно, вы о них слышали. Скажем, на лекциях по структурам данных. И возможно, вы думали, что это как-то сильно заумно. Почему бы не использовать массив? На самом деле связные списки имеют некоторые преимущества перед массивами и простыми списками. Поначалу эта тема может показаться сложной, но не волнуйтесь: мы все разберем.
Если вы представите себе фотографию людей, взявшихся за руки в хороводе, вы получите примерное представление о такой структуре, как связный список. Это некоторое количество отдельных узлов, связанных между собой ссылками, т. е. ссылками на другие узлы. Связные списки бывают двух видов: однонаправленные и двунаправленные (односвязные и двусвязные).
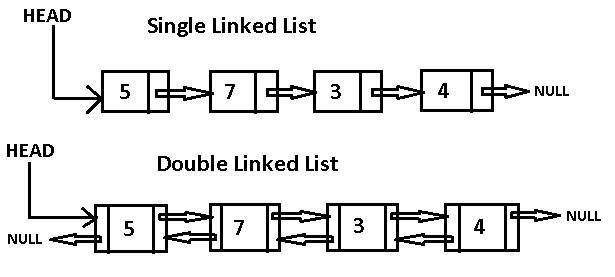
В односвязных списках каждый узел имеет одну стрелку, указывающую вперед, а в двусвязных узлы имеют еще и стрелки, указывающие назад. Но на собеседованиях в вопросах, касающихся связных списков, чаще всего имеются в виду односвязные. Почему? Их проще реализовать. Да, у вас не будет возможности перемещаться по списку в обратном направлении, но для отслеживания узлов хватит и однонаправленных связей.
Давайте попробуем реализовать связный список на Python. Возможно, вы бы начали с class Linked_list, а затем создали в нем узлы, но все можно сделать куда проще. Представьте цепочку из скрепок. Мы берем кучку скрепок и соединяем их, цепляя друг за дружку.

Цепочку создают отдельные скрепки плюс тот факт, что они сцеплены между собой. Поэтому вместо создания класса Linked_list мы просто создадим класс Node и позволим отдельным узлам связываться друг с другом.
class Node:
Далее, как обычно при создании класса на Python, мы создаем метод __init__. Этот метод инициализирует все поля, например, переменные в классе, при создании каждого нового объекта Node.
Мы будем принимать переменную data — это значение, которое мы хотим сохранять в узле. Также нам нужно определить ссылку, направленную вперед, она традиционно называется next. Сначала узел не связан ни с чем, поэтому мы устанавливаем next в None.
class Node:
def __init__(self, data):
self.data = data
self.next = None
Это почти все, что нам нужно. Можно оставить, как есть, но в книге «Cracking the Coding Interview» также реализуется метод appendToTail(), который создает новый узел и добавляет его в конец списка, проходя его, так что нам не приходится делать это вручную.
Начнем с определения этого метода в классе Node. Метод будет принимать значение, которое мы хотим поместить в новый узел, и ключевое слово self (это специфично для Python).
class Node:
def __init__(self, data):
self.data = data
self.next = None
def append(self, val):
pass
Первое, что мы делаем, это создаем новый узел с заданным значением. Назовем его end.
def append(self, val):
end = Node(val)
Затем мы создаем указатель (поинтер). Это может звучать слишком технически, но по сути мы создаем ссылку на головной элемент (head) нашего списка. Мы делаем так, потому что хотим проходить по списку, не переназначая в нем ничего. Итак, мы делаем ссылку на первый узел, self, и сохраняем его в переменной n.
def append(self, val):
end = Node(val)
n = self
Наконец, мы проходим список. Как мы это делаем? Нам нужно всего лишь перемещаться к следующему узлу, если он есть. А если следующего узла нет, мы поймем, что мы уже в конце списка. Для прохождения списка до предпоследнего узла мы используем простой цикл while.
def append(self, val):
end = Node(val)
n = self
while (n.next):
n = n.next
Наконец, мы указываем на последний узел, за которым нет следующего узла. Мы просто берем end — наш новый узел — и устанавливаем n.next = end.
def append(self, val):
end = Node(val)
n = self
while (n.next):
n = n.next
n.next = end
Вот и все! Вот как выглядит наш класс полностью:
list_node.py
class Node:
def __init__(self, data):
self.next = None
self.data = data
def append(self, val):
end = Node(val)
n = self
while (n.next):
n = n.next
n.next = end
Проверяем наш связный список
Давайте все это проверим. Начнем с создания нового объекта Node. Назовем его ll (две латинские буквы «l» в нижнем регистре как сокращение Linked List). Назначим ему значение 1.
ll = Node(1)
Поскольку мы написали такой классный метод append(), мы можем вызывать его для добавления в наш список новых узлов.
ll.append(2) ll.append(3)
Как нам увидеть, как выглядит наш список? Теоретически, выглядеть он должен следующим образом:
[1] --> [2] --> [3]
Но нет способа вывести его именно в таком виде. Нам нужно пройти список, выводя каждое значение. Вы же помните, как проходить список? Мы только что это делали. Повторим:
- Создаем переменную, указывающую на
head. - Если есть следующий узел, перемещаемся к этому узлу.
И просто выводим data в каждом узле. Мы начинаем с шага № 1: создаем новую переменную и назначаем ее головным элементом списка.
node = ll
Далее мы выводим первый узел. Почему мы не начали с цикла while? Цикл while проитерируется только дважды, потому что только у двух узлов есть next (у последнего узла его нет). В информатике это называется ошибкой на единицу (когда нужно сделать что-то Х раз плюс 1). Это можно представить в виде забора. Вы ставите столб, затем секцию забора, и чередуете пару столб + секция столько раз, сколько нужно по длине.

Но вы не можете оставить последнюю секцию забора висящей в воздухе. Ограда должна закончиться столбом, а не секцией. Поэтому вам приходится либо добавлять еще один столб в конце, либо (что в информатике более распространено) начать с постановки столба, а затем добавлять пары секция + столб. Это мы и сделаем.
Для начала мы выведем первый узел, а затем запустим цикл while для вывода всех последующих узлов.
node = ll
print(node.data)
while node.next:
node = node.next
print(node.data)
Запустив это для нашего предыдущего списка, мы получим в консоли:
1 2 3
Ура! Наш связный список работает.
Зачем уметь создавать связный список на Python?
Зачем вообще может понадобиться создавать собственный связный список на Python? Это хороший вопрос. Использование связных списков имеет некоторые преимущества по сравнению с использованием просто списков Python.
Традиционно вопрос звучит как «чем использование связного списка лучше использования массива». Основная идея в том, что массивы в Java и других ООП-языках имеют фиксированный размер, поэтому для добавления элемента приходится создавать новый массив с размером N + 1 и помещать в него все значения из предыдущего массива. Пространственная и временная сложность этой операции — O(N). А вот добавление элемента в конец связного списка имеет постоянную временную сложность (O(1)).
Списки в Python это не настоящие массивы, а скорее реализация динамического массива, что имеет свои преимущества и недостатки. В Википедии есть таблица со сравнением производительности связных списков, массивов и динамических массивов.
Если вопрос производительности вас не тревожит, тогда да, проще реализовать обычный список Python. Но научиться реализовывать собственный связный список все равно полезно. Это как изучение математики: у нас есть калькуляторы, но основные концепции мы все-таки изучаем.
В сообществе разработчиков постоянно ведутся горячие споры о том, насколько целесообразно давать на технических интервью задания, связанные с алгоритмами и структурами данных. Возможно, в этом и нет никакого смысла, но на собеседовании вас вполне могут попросить реализовать связный список на Python. И теперь вы знаете, как это сделать.
