Ознакомьтесь с последней версией PyTorch, которая стала более быстрой, более питонизированной и более динамичной.
Содержание:
- Что нового в PyTorch 2.0?
- Компиляция PyTorch 2.0
- Как установить PyTorch 2.0
- Ускорение работы программы Hugging Face с помощью PyTorch 2.0
PyTorch — это фреймворк глубокого обучения с открытым исходным кодом и поддержкой сообщества, обеспечивающий гибкий и эффективный способ построения моделей машинного обучения. Он обладает удобным интерфейсом, широкой поддержкой сообщества и легко интегрируется в экосистему Python.
В PyTorch 2.0 были внесены фундаментальные изменения в основные операции компилятора, сохраняя при этом тот же уровень знакомства и удобства для разработчиков. Это последнее обновление обещает ускоренную производительность и расширенную поддержку для динамических форм и распределенного обучения.
От редакции Pythonist: вас может заинтересовать обзор книги «Знакомство с PyTorch». А если вы не знакомы с этим фреймворком, рекомендуем статью «Введение в PyTorch».
Хотите скачать книги по Python в 2 клика? Тогда вам в наш телеграм канал PythonBooks
Что нового в PyTorch 2.0?
PyTorch перемещает части из C++ обратно в Python, делая его более быстрым и лучше поддающимся модификации. В версии 2.0 появилась функция torch.compile, которая меняет работу PyTorch на уровне компилятора. Эта возможность является опциональной и не влияет на ваш старый код.
Компиляция PyTorch 2.0
Для создания прочной основы для функции torch.compile были введены новые технологии:
- TorchDynamo. Компилятор Just-in-Time (JIT) на уровне Python, специально разработанный для ускорения работы PyTorch. Интегрируясь с API оценки кадров в CPython, он динамически модифицирует байткод Python во время выполнения, обеспечивая более быстрое выполнение кода.
- AOTAutograd. Инструмент для в ускорения обучения моделей на PyTorch. Он заранее трассирует прямые и обратные графы. Кроме того, AOTAutograd предлагает простые механизмы для беспрепятственной компиляции извлеченных графов с помощью современных компиляторов глубокого обучения.
- PrimTorch. Благодаря значительному сокращению числа операторов PyTorch с более чем 2000 до краткого набора из примерно 250 примитивных операторов, PrimTorch значительно упростил процесс разработки функций или бэкендов PyTorch.
- TorchInductor. Компилятор глубокого обучения на основе PyTorch, который автоматически транслирует модели PyTorch в сгенерированный код для различных ускорителей и бэкендов. TorchInductor использует OpenAI Triton для GPU-ускорения.
Все новые технологии написаны на языке Python и поддерживают динамические формы. Это делает новый код для запуска PyTorch более быстрым, гибким и легко кастомизируемым, снижая барьер входа.
Примеры кода
Давайте рассмотрим быструю и простую реализацию кода PyTorch Compiler.
Без torch.compile:
import torch
model = torch.hub.load("pytorch/vision", "resnet50", weights="IMAGENET1K_V2")
Чтобы повысить производительность модели, достаточно добавить обертку torch.compile вокруг модели и получить скомпилированную модель. Это и есть plug-and-play.
import torch
model = torch.hub.load("pytorch/vision", "resnet50", weights="IMAGENET1K_V2")
compiled_model = torch.compile(model)
Вы сможете просто обучать свою модель, ничего не меняя.
import torch
model = torch.compile(model)
for batch in dataloader:
run_epoch(model, batch)
Или можно запустить режим вывода.
model = torch.compile(model) model(**input)
torch.compile() поддерживает следующие параметры:
- mode: можно указать, какой компилятор должен использоваться при компиляции.
- dynamic: используется для активации кодового пути для динамических форм (Dynamic Shapes).
- fullgraph: компилирует программу в один граф.
- backend: по умолчанию используется TorchInductor, но можно указать и другие доступные бэкенды компилятора.
def torch.compile(model: Callable, *, mode: Optional[str] = "default", dynamic: bool = False, fullgraph:bool = False, backend: Union[str, Callable] = "inductor", **kwargs ) -> torch._dynamo.NNOptimizedModule
Benchmark
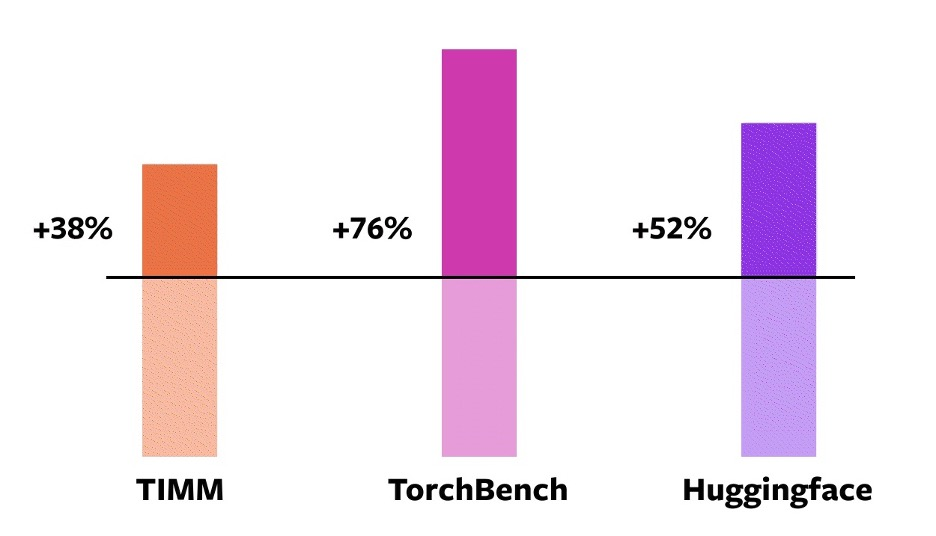
Приступая к работе с PyTorch 2.0, разработчики использовали 163 модели с открытым исходным кодом (46 HuggingFace Transformers, 61 TIMM и 56 TorchBench) для создания бенчмарков производительности новой компилируемой функции. Бенчмарк включает такие задачи, как классификация и генерация изображений, языковое моделирование, рекомендательные системы и обучение с подкреплением.
Результат показывает значительное повышение производительности при обучении на графических процессорах NVIDIA A100.
Примечание: в настоящее время бэкэнд по умолчанию поддерживает только CPU с графическими процессорами Nvidia серий Volta и Ampere.
Это только начало, и в ближайших обновлениях вы увидите дополнительные улучшения производительности и масштабируемости.
Как установить PyTorch 2.0
Вы можете просто установить новую версию PyTorch с помощью команды pip.
Скопируйте и вставьте соответствующую команду в терминал.
Для графических процессоров: CUDA 11.8
Оказалось, что новые версии графических процессоров демонстрируют значительно более высокую производительность.
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu118
Для графических процессоров: CUDA 11.7
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu117
Центральные процессоры:
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cpu
Верификация:
git clone https://github.com/pytorch/pytorch cd tools/dynamo python verify_dynamo.py
Ускорение Hugging Face с помощью PyTorch 2.0
Давайте попробуем функцию torch.compile для ускорения Hugging Face трансформеров. Вы можете сделать свой код Hugging Face быстрее с помощью однострочного декоратора.
Примечание: При использовании torch.compile() мы наблюдали прирост производительности на 30%-200% при обучении — TorchDynamo Performance Dashboard.
В данном примере мы применим torch.compile() к большой языковой модели «dolly-v2-3b» для ускорения вывода. Чтобы запустить код в Google Colab, нам нужно сначала установить необходимые библиотеки Python.
%%capture %pip install transformers accelerate xformers
Затем мы загрузим и подгрузим токенизатор и языковую модель с помощью трансформеров Hugging Face. После этого мы добавим nn.Module в функцию torch.compile().
import torch
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
GenerationConfig,
pipeline,
)
tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-3b")
model = AutoModelForCausalLM.from_pretrained(
"databricks/dolly-v2-3b", device_map="auto", torch_dtype=torch.bfloat16
)
model = torch.compile(model) #only line of code is required
На последнем этапе мы преобразуем текст в лексемы с помощью tokenizer, передадим их в model.generate, а затем декодируем полученный результат в текст с помощью tokenizer.batch_decode.
prompt = "I love you because"
inputs = tokenizer(prompt, return_tensors="pt").to(device="cuda:0")
# Generate
generate_ids = model.generate(inputs.input_ids, max_length=50)
tokenizer.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)[0]
Как видим, «dolly-v2» завершила предложение, добавив: «You are a good person».
"I love you because you are a good person. You are kind, you help others, you are honest, you are loyal, you are humble, you are humble, you are humble. You are a good person."
Он также работает с Hugging Face пайплайном. Просто укажите тип задачи, модель и токенизатор.
generator = pipeline("text-generation", model= model,tokenizer=tokenizer)<br>generator("What is the name of Germany's Capital?")
Вывод:
[{'generated_text': "What is the name of Germany's Capital?
The name of Germany's Capital is Berlin."}]
Функция компиляции работает с трансформаторами, ускорителем и библиотеками TIMM Python.
Перевод статьи «PyTorch 2.0 is Here: Everything We Know».

