
PyTorch — один из самых популярных фреймворков глубокого обучения для специалистов в области machine learning. Создан он на основе библиотеки Torch.
Есть много вещей, которые делают PyTorch популярным. Это и простота использования, и динамический вычислительный граф, и тот факт, что он кажется более «питоновским», чем другие фреймворки, такие как Tensorflow.
В этом руководстве мы рассмотрим базовые компоненты PyTorch. Затем разберем задачу классификации изображений с использованием набора данных CIFAR10. Поскольку PyTorch имеет множество функций и вариантов их применения, очевидно, данное руководство не будет исчерпывающим. Это только введение в PyTorch. Цель этой статьи — создать общее представление об этом фреймворке и рассмотреть несколько его компонентов.
От редакции Pythonist. О глубоком обучении можно почитать в статье «Введение в глубокое обучение: пошаговое руководство».
Тензор
Центральным компонентом PyTorch является такая структура данных, как тензор. Если вы знакомы с NumPy, вы обнаружите, что тензоры PyTorch похожи на ndarrays в NumPy. Ключевое отличие заключается в том, что они поддерживают CUDA и созданы для запуска на аппаратных ускорителях, таких как графические процессоры.
Еще одна важная особенность тензоров заключается в том, что они оптимизированы для автоматического дифференцирования. Это основа алгоритма обучения нейронной сети, известного как обратное распространение ошибки.
Эти две особенности тензоров очень важны для глубокого обучения:
- огромные объемы данных, функций и итераций глубокого обучения требуют массивно-параллельной архитектуры графических процессоров для обучения в разумные сроки
- обучение с помощью обратного распространения ошибки требует эффективной и точной дифференциации.
PyTorch также поддерживает распределенные вычисления, расширяя процесс обучения за пределы одной машины!
С учетом сказанного выше давайте взглянем на тензорный API!
[machinelearning_ad_block]Тензоры в действии
Примечание. Если вы хотите вместе с нами запускать код, то перейдите сначала к разделу Установка.
Итак, мы можем естественным образом создавать тензоры из списков в Python:
A = [[6, 9, 2],
[3, 3, 7],
[1, 0, 3]]
A_tensor = torch.tensor(A)
Это также естественно работает с Numpy ndArrays:
B = np.array([0,1,2,3]) B_tensor = torch.from_numpy(B)
Как и в NumPy, мы можем инициализировать тензоры случайными значениями, одними единицами или одними нулями. Просто укажите форму (и dtype, если хотите указать тип данных):
# with no dtype argument, torch will infer the type C = torch.zeros(4,4) C # tensor([[0., 0., 0., 0.], # [0., 0., 0., 0.], # [0., 0., 0., 0.], # [0., 0., 0., 0.]])
Не будем забывать, что тензоры не обязательно должны быть двумерными!
D = torch.ones(3,3,2, dtype=torch.int) D # tensor([[[1, 1], # [1, 1], # [1, 1]], # # [[1, 1], # [1, 1], # [1, 1]], # # [[1, 1], # [1, 1], # [1, 1]]], dtype=torch.int32)
Новый тензор можно создать из существующего. Итак, при желании мы могли бы создать новый тензор нулей с теми же свойствами (форма и тип данных), что и созданный нами A_tensor:
A_tensor_zeros = torch.zeros_like(A_tensor) A_tensor_zeros # tensor([[0, 0, 0], # [0, 0, 0], # [0, 0, 0]])
Или, может быть, вам нужны случайные значения с плавающей запятой:
# Аргумент dtype позволяет явно указать тип данных тензора A_tensor_rand = torch.rand_like(A_tensor, dtype=torch.float) A_tensor_rand # tensor([[0.2298, 0.9499, 0.5847], # [0.6357, 0.2765, 0.0125], # [0.1215, 0.1747, 0.9935]])
Хотите получить атрибуты тензора?
A_tensor_rand.dtype # torch.float32 A_tensor_rand.shape # torch.Size([3, 3]) A_tensor_rand.device # device(type='cpu')
Создавать тензоры — это хорошо. Однако настоящее веселье начнется, когда мы начнем манипулировать ими и применять математические операции. Встроенных операций существует много, мы точно не успеем обсудить их все. По этой ссылке можно ознакомиться с ними более подробно. Здесь же просто назовем несколько:
- умножение матриц
- вычисление собственных векторов и значений
- сортировка
- индексы, срезы, соединения
- Окно Хэмминга (не уверены, что это такое, но звучит круто!!)
Модули Dataset и DataLoader
Dataset
Как и Tensorflow, PyTorch имеет несколько наборов данных, включенных в пакет (например, Text, Image и Audio). В этом руководстве будет использоваться один из таких встроенных наборов данных изображений — CIFAR10. Эти датасеты очень распространены и широко задокументированы в сообществе ML. Они отлично подходят для прототипирования и сравнительного анализа моделей, поскольку вы можете сравнить производительность своей модели с тем, чего смогли достичь другие.
import torch
import torchvision
from torchvision.datasets import FashionMNIST # torchvision for image datasets
from torchtext.datasets import AmazonReviewFull # torchtext for text
from torchaudio.datasets import SPEECHCOMMANDS #torchaudio for audio
training_data = FashionMNIST(
# the directory you want to store the dataset, can be a string e.g. "data"
root = data_directory,
# if set to False, will give you the test set instead
train = True,
# download the dataset if it's not already available in the root path you specified
download = True,
# as the name implies, will transform images to tensor data structures so PyTorch can use them for training
transform = torchvision.transforms.ToTensor()
)
Кроме того, если в вашем наборе данных есть метки или классификации, можно быстро просмотреть их список:
training_data.classes
# ['T-shirt/top',
# 'Trouser',
# 'Pullover',
# 'Dress',
# 'Coat',
# 'Sandal',
# 'Shirt',
# 'Sneaker',
# 'Bag',
# 'Ankle boot']
training_data.class_to_idx # get the corresponding index with each class
# {'Ankle boot': 9,
# 'Bag': 8,
# 'Coat': 4,
# 'Dress': 3,
# 'Pullover': 2,
# 'Sandal': 5,
# 'Shirt': 6,
# 'Sneaker': 7,
# 'T-shirt/top': 0,
# 'Trouser': 1}
Очевидно, что встроенные наборы данных — это не все, что нужно специалисту по машинному обучению. Создание собственного набора данных с помощью PyTorch — довольно простой и гибкий процесс, хотя и немного более сложный, чем простой импорт.
DataLoader
Итерация по набору данных будет проходить каждую выборку постепенно, поэтому PyTorch предоставляет нам модуль DataLoader для простого создания мини-пакетов в наших наборах данных. DataLoader позволяет нам указать размер батча, а также перемешать данные:
train_dataloader = DataLoader(training_data, batch_size = 32, shuffle = True)
Таким образом, в процессе глубокого обучения вы сможете передавать свои данные в модель для обучения в мини-батчах и через DataLoader.
Прежде чем перейти к глубокому обучению, разберем еще один важный момент — настройку устройства. Если вы хотите тренироваться на графическом процессоре, вы можете проверить, доступен ли он для использования PyTorch:
torch.cuda.is_available() # True if GPU available
PyTorch по умолчанию использует центральный процессор. Поэтому даже при наличии графического процессора все равно нужно указать, что вы хотите его использовать для обучения. Если вы уверены, что ваш графический процессор доступен, вы можете использовать .to("cuda") для своих тензоров и моделей. В противном случае вы можете рассмотреть возможность установки переменной device для любого доступного устройства:
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Device: {device}")
# 'cuda'
# you can specify .to("cuda") or .to(device)
tensor = tensor.to("cuda")
# attaching your neural network model to your GPU
model = model.to(device)
Если вы используете Google Colab, у вас будет бесплатный доступ к графическому процессору.
Установка
Итак, мы будем использовать Google Colab.
Colab является хорошим помощником в проектах по машинному обучению. Для небольших проектов и учебных пособий это лучшее решение, т.к. Colab предоставляет бесплатный доступ к графическому процессору и среду, которая включает в себя уже установленные пакеты, такие как PyTorch, NumPy, Scikit-Learn.
Итак, для начала перейдите на страницу Google Colab и войдите в свою учетную запись Google. File > New notebook. Измените имя своего notebook на pytorchIntro.ipynb или какое-нибудь другое.
Colab не предоставляет экземпляр с доступом к графическому процессору по умолчанию. Поэтому вам нужно явно указать, что вы хотите его использовать. Вверху выберите Runtime > Change runtime type > Hardware accelerator > Select "GPU" > Save. Теперь у вас есть графический процессор для обучения ваших моделей!
Теперь, когда у нас есть Colab и графический процессор, давайте перейдем к коду.
Импорт
import torch from torch import nn from torch.utils.data import DataLoader from torchvision.utils import make_grid from torchvision.datasets import CIFAR10 from torchvision.transforms import ToTensor from torchvision.transforms import Normalize, Compose import os import matplotlib.pyplot as plt import numpy as np
Для начала импортируйте следующие модули. Это основные модули PyTorch, которые мы будем использовать, а также несколько вспомогательных импортов. Позже мы рассмотрим их более подробно.
Dataset
Набор данных CIFAR-10
Этот набор данных состоит из 60 000 цветных изображений 32×32, помеченных как один из 10 классов. Учебный набор составляет 50 000 изображений, а тестовый — 10 000.
Вот хорошая визуализация набора данных из домашнего источника:

Цель этого проекта — создание модели, которая сможет точно классифицировать изображения по одной из 10 классификаций.
Загрузка набора данных
Итак, мы импортировали CIFAR10 из torchvision, и теперь нам нужно загрузить фактический набор данных и подготовить его для загрузки в нейронную сеть.
Перед подачей в модель мы должны нормализовать наши изображения. Поэтому мы определим функцию преобразования transform() и используем torchvision.transforms.Normalize для нормализации всех наших изображений при создании переменных обучающих и тестовых данных.
Метод Normalize() использует желаемое среднее значение и стандартное отклонение в качестве аргументов. Поскольку это цветные изображения, значение должно быть предоставлено для каждого цветового канала (R, G, B).
Мы установим значения здесь равными 0,5, так как хотим, чтобы значения данных нашего изображения были близки к 0. Однако есть и другие, более точные подходы к нормализации.
transform = Compose(
[ToTensor(),
Normalize((0.5, 0.5, 0.5), # mean
(0.5, 0.5, 0.5))] # std. deviation
)
Теперь мы можем использовать нашу функцию transform() в качестве аргумента transform, чтобы PyTorch применил ее ко всему набору данных.
training_data = CIFAR10(root="cifar",
train = True, # train set, 50k images
download = True,
transform=transform)
test_data = CIFAR10(root = "cifar",
train = False, # test set, 10k images
download = True,
transform = transform)
Когда наш набор данных загружен и нормализован, мы можем подготовить его для передачи в нейронную сеть с помощью PyTorch DataLoader, где можно определить размер пакета batch_size .
batch_size = 4
train_dataloader = DataLoader(training_data,
batch_size=batch_size,
shuffle=True)
test_dataloader = DataLoader(test_data,
batch_size=batch_size,
shuffle=True)
DataLoader является итерируемым, поэтому давайте взглянем на train_dataloader, проверив размеры одной итерации:
for X, y in train_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
# Shape of X [N, C, H, W]: torch.Size([4, 3, 32, 32])
# Shape of y: torch.Size([4]) torch.int64
Здесь X — изображения, а y — метки. Мы установили batch_size = 4, чтобы каждая итерация через train_dataloader представляла собой мини-пакет из 4 изображений 32×32 и соответствующих им 4 меток.
Теперь давайте рассмотрим некоторые примеры в нашем наборе данных.
def imshow(img):
img = img / 2 + .05 # revert normalization for viewing
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1,2,0)))
plt.show()
classes = training_data.classes
training_data.classes
#['airplane',
# 'automobile',
# 'bird',
# 'cat',
# 'deer',
# 'dog',
# 'frog',
# 'horse',
# 'ship',
# 'truck']
dataiter = iter(train_dataloader)
images, labels = dataiter.next()
imshow(make_grid(images))
print(' '.join(f'{classes[labels[j]]:5s}' for j in range(batch_size)))

Обычно стоит провести более тщательное исследование и анализ данных, прежде чем переходить к построению модели. Однако, поскольку это всего лишь введение в PyTorch, мы перейдем к построению и обучению модели.
Определение базовой модели
Давайте построим нейронную сеть.
Сперва мы определим класс нашей модели и назовем его NeuralNetwork. Наша модель будет подклассом PyTorch nn.Module, который является базовым классом для всех модулей нейронной сети в PyTorch.
Поскольку в нашем наборе данных есть цветные изображения, форма каждого изображения будет (3, 32, 32) — тензор 32×32 в каждом из 3 цветовых каналов RGB.
Т.к. наша исходная модель будет состоять из полностью связанных слоев, нам нужно будет применить функцию nn.Flatten() для входных данных изображения. Наш метод сглаживания выведет линейный слой с 3072 (32 x 32 x 3) узлами.
Функция nn.Linear() принимает количество входных нейронов и количество выходных в качестве аргументов соответственно (nn.Linear(1024 in, 512 out)). После этого вы можете добавить слои Linear layers и ReLU в основной контент. Output нашей модели составляет 10 логитов, соответствующих 10 классам в нашем наборе данных.
После определения структуры модели мы зададим последовательность прямого прохода. Поскольку наша модель представляет собой последовательную модель, метод forward будет очень простым. Он будет вычислять выходной Tensor из входных Tensors.
При желании вы можете просто вывести модель model после ее определения, чтобы получить сводную информацию о структуре.
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(32*32*3, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
#NeuralNetwork(
# (flatten): Flatten(start_dim=1, end_dim=-1)
# (linear_relu_stack): Sequential(
# (0): Linear(in_features=3072, out_features=1024, bias=True)
# (1): ReLU()
# (2): Linear(in_features=1024, out_features=512, bias=True)
# (3): ReLU()
# (4): Linear(in_features=512, out_features=10, bias=True)
# )
#)
Функция потерь и оптимизатор
Поскольку это задача классификации, мы будем использовать функцию кросс-энтропийных потерь Cross-Entropy. Напомним, что Cross-Entropy вычисляет логарифмическую потерю, когда модель выводит прогнозируемое значение вероятности между 0 и 1. Таким образом, поскольку прогнозируемая вероятность отличается от истинного значения, потери быстро возрастают. График ниже иллюстрирует поведение функции потерь по мере того, как прогнозируемое значение становится ближе и дальше от истинного значения.
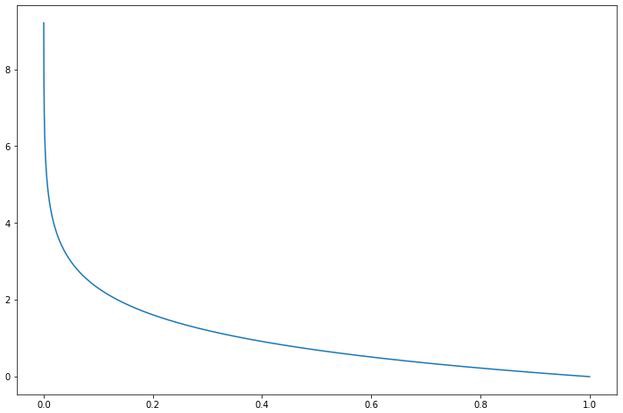
В PyTorch мы можем просто использовать функцию CrossEntropyLoss(). Для нашего алгоритма оптимизации мы применим стохастический градиентный спуск, который реализован в пакете torch.optim вместе с другими оптимизаторами, такими как Adam и RMSprop. Нам просто нужно передать параметры нашей модели и скорость обучения lr. Если вы хотите использовать затухание импульса или веса при оптимизации модели, вы можете передать это оптимизатору SGD() в качестве параметров momentum и weight_decay (по умолчанию они равны 0).
loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.SGD( model.parameters(), lr=0.001 ) # momentum=0.9
Определение цикла обучения
Здесь мы определяем нашу функцию train(), которой мы будем передавать train_dataloader, model, loss_fn и optimizer в качестве аргументов в процессе обучения. Переменная size — это длина всего обучающего набора данных (50 КБ). В следующей строке model.train() — это метод nn.Module в PyTorch, который переводит модель в режим обучения, обеспечивая определенные варианты поведения, которые нам нужны (например, отсев, пакетная норма и т.д.). Затем мы пройдемся по каждому мини-пакету, указав, что мы хотели бы использовать GPU с to(device). Мы загружаем мини-пакет в нашу модель, вычисляем потери, а затем выполняем обратное распространение.
Результат обратного распространения и обучения
Для шага обратного распространения нам нужно сначала запустить optimizer.zero_grad(). Это устанавливает градиент в ноль перед запуском обратного распространения, поскольку мы не хотим накапливать градиент за последующие проходы.
Метод loss.backward() использует потери для вычисления градиента, затем мы используем Optimizer.step() для обновления весов.
Наконец, мы можем вывести обновления процесса обучения, печатая вычисленные потери после каждых 2000 обучающих выборок.
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 2000 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
Определение метода тестирования
Перед обучением модели давайте реализуем тестовую функцию. Это нужно для того, чтобы мы могли оценивать нашу модель и выводить точность на тестовом наборе. Большие отличия от метода тестирования заключаются в том, что мы используем model.eval(), чтобы перевести модель в режим тестирования, и torch.no_grad(), который отключит вычисление градиента, так как мы не используем обратное распространение во время тестирования. Наконец, мы вычисляем средние потери для набора тестов и общую точность.
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
Обучение модели
Теперь, когда мы всё сделали, мы готовы к обучению! Укажите количество epochs, на которых вы хотите обучить модель. Каждая эпоха будет проходить цикл train, который выводит прогресс каждые 2000 выборок. Затем он проверяет модель на тестовом наборе и выводит точность и потери на тестовом наборе.
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print("Done!")
Сохранение и загрузка модели
После завершения обучения, если вы хотите сохранить свою модель для использования в выводах, используйте torch.save().
Передайте model.state_dict() в качестве первого аргумента. Это просто словарь, который сопоставляет слои с их соответствующими изученными параметрами (весами и смещениями).
В качестве второго аргумента дайте имя вашей модели (принято сохранять модели PyTorch с использованием расширений .pth или .pt). Также можно указать полный путь, если вы хотите сохранить его в определенном каталоге.
torch.save(model.state_dict(), "cifar_fc.pth")
Если вы хотите загрузить свою модель для логического вывода, используйте torch.load(), чтобы получить сохраненную модель, и сопоставьте изученные параметры с помощью load_state_dict.
model = NeuralNetwork()
model.load_state_dict(torch.load("cifar_fc.pth"))
Оценка модели
Вы можете пройти через test_dataloader, чтобы сверить образец изображений с их метками.
dataiter = iter(test_dataloader)
images, labels = dataiter.next()
imshow(make_grid(images))
print('Ground Truth: ', ' '.join(f'{classes[labels[j]]:5s}' for j in range(4)))

Затем сравните его с предсказанными метками нашей модели, чтобы предварительно оценить ее производительность:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join(f'{classes[predicted[j]]:5s}' for j in range(4)))
# Predicted: dog ship automobile deer
Итак, мы видим, что наша модель учится классифицировать! Давайте посмотрим на цифры производительности нашей модели.
correct = 0
total = 0
with torch.no_grad():
for data in test_dataloader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Model accuracy: {100 * correct // total} %')
# Model accuracy: 53 %
Точность в 53% далеко не самый хороший результат. Однако это намного лучше, чем случайное угадывание или просто предсказание одного класса. Так что наша модель определенно чему-то научилась!
Далее мы можем быстро проверить, как она работает при классификации каждого класса:
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
with torch.no_grad():
for data in test_dataloader:
images, labels = data
outputs = model(images)
_, predictions = torch.max(outputs, 1)
for label,prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class {classname:5s}: {accuracy:.1f}%')
# Accuracy for class airplane: 58.9%
# Accuracy for class automobile: 61.2%
# Accuracy for class bird : 33.5%
# Accuracy for class cat : 35.4%
# Accuracy for class deer : 52.8%
# Accuracy for class dog : 49.4%
# Accuracy for class frog : 60.6%
# Accuracy for class horse: 59.6%
# Accuracy for class ship : 64.5%
# Accuracy for class truck: 63.1%
Теперь у нас есть немного лучшее представление о производительности нашей модели. Сети было сложнее классифицировать изображения кошек и птиц.
Заключение
Безусловно, такие модели обычно не используются для классификации изображений. Это был всего лишь обучающий пример.
Надеемся, данная статья была вам полезна! Успехов в написании кода!
Перевод статьи «Intro to PyTorch: Part 1».
