
Вы когда-нибудь задумывались, как работает Amazon Alexa или Google Translate? В основе работы этих и многих других систем лежит глубокое обучение.
Глубокое обучение (англ. Deep Learning, DL), будучи разновидностью машинного обучения (англ. Machine Learning, ML), произвело революцию в мире технологий и нашло свое применение во всех сферах бизнеса.
В этом вступлении в глубокое обучение мы рассмотрим следующие темы:
- Что такое глубокое обучение и где оно применяется?
- Глубокое обучение vs. машинное обучение
- Что такое нейронные сети и как они работают?
- Платформы глубокого обучения
- Введение в TensorFlow
- Реализация кейса при помощи TensorFlow
Что такое глубокое обучение?
Прежде чем мы углубимся в глубокое обучение, его приложения и платформы, нам сперва нужно понять, что вообще из себя представляет глубокое обучение.
Глубокое обучение — это подраздел машинного обучения, который занимается алгоритмами, основанными на структуре и функциях мозга. Глубокое обучение — это разновидность машинного обучения, которое, в свою очередь, является частью сферы искусственного интеллекта (ИИ).
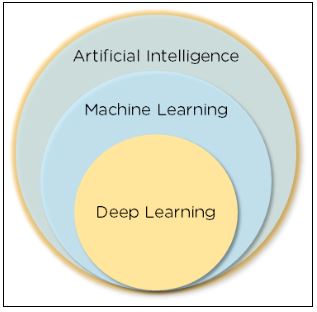
Искусственный интеллект — это способность машины имитировать разумное поведение человека. Машинное обучение позволяет системе автоматически обучаться и улучшать свой собственный опыт. Глубокое обучение — это разновидность машинного обучения, которая использует сложные алгоритмы и глубокие нейронные сети для обучения моделей.
Применение глубокого обучения
Теперь давайте познакомимся с несколькими вариантами применения глубокого обучения на практике.
- Глубокое обучение широко используется для прогнозирования погоды в отношении осадков, землетрясений и цунами. Это помогает принять необходимые меры предосторожности.
- Благодаря глубокому обучению машины могут понимать речь и обеспечивать хорошее качество ее распознавания.
- Модели глубокого обучения также помогают рекламодателям таргетировать рекламу и назначать ее ставки в реальном времени.
Глубокое обучение vs. машинное обучение
- Машинное обучение работает только с наборами структурированных и полуструктурированных данных, в то время как глубокое обучение работает как со структурированными, так и с неструктурированными данными.
- Алгоритмы глубокого обучения могут эффективно выполнять сложные операции, а алгоритмы машинного обучения — нет.
- Алгоритмы машинного обучения для извлечения закономерностей используют размеченные наборы данных. При глубоком обучении программа принимает большие объемы данных в качестве входных и анализирует их для извлечения свойств объекта.
- Производительность алгоритмов машинного обучения снижается по мере увеличения количества данных. Поэтому для поддержания работоспособности модели нам необходимо глубокое обучение.
Что такое нейронные сети?
Теперь, когда вы знаете, что такое глубокое обучение, где оно применяется и чем отличается от машинного обучения, давайте рассмотрим нейронные сети и их работу.
Нейронная сеть — это система, смоделированная на основе человеческого мозга, состоящая из входного слоя, нескольких скрытых слоев и выходного слоя. Данные поступают на вход нейронной сети. Далее информация передается на следующий уровень с применением соответствующих весов и смещений. На выходе сети оказывается окончательное значение, предсказанное искусственным нейроном.
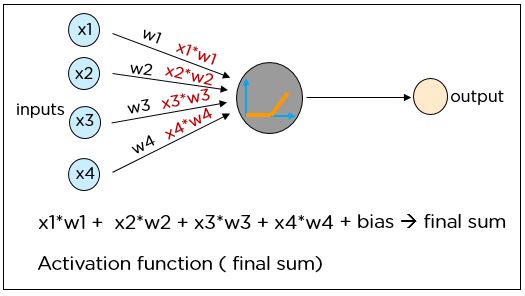
Каждый нейрон в нейронной сети выполняет следующие операции:
- Находится произведение каждого входа и веса канала, через который он проходит.
- Вычисляется сумма взвешенных произведений, которая называется взвешенной суммой.
- К взвешенной сумме добавляется смещение.
- Затем окончательная сумма подается в специальную функцию, которая называется функцией активации.
Функция потерь
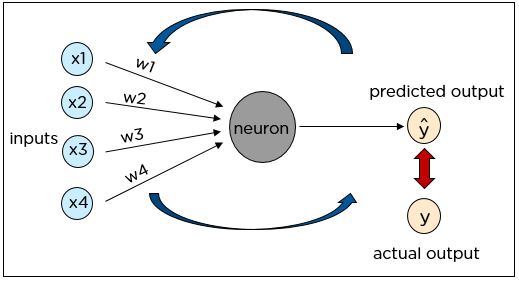
Функция потерь — один из важнейших компонентов нейронной сети. Потери — это разность между полученным результатом нейронной сети и правильным ответом из размеченного набора обучающих данных. Минимизация функции потерь посредством корректировки весов и смещений производится на протяжении всего процесса обучения.
Как работают нейронные сети?
В этом разделе мы рассмотрим, как нейронная сеть обучается распознавать различные формы. Формы представляют собой изображения размером 28 х 28 пикселей.
Каждый пиксель подается на вход нейронов первого слоя, а скрытые слои будут повышать точность вывода. Данные передаются от слоя к слою по каналам, где они умножаются на разные веса. Причем каждый нейрон в одном слое имеет разные веса по отношению к каждому нейрону в следующем слое.
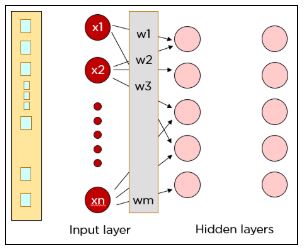
Каждый нейрон в первом скрытом слое принимает подмножество входных данных и обрабатывает их. Все входные данные умножаются на соответствующие веса и к ним еще добавляется смещение. Результаты функции активации определяют, данные из каких нейронов будут переданы в следующий слой.
Шаг 1: x1*w1 + x2*w2 + b1
Шаг 2: Φ(x1* w1 + x2*w2 + b1)
(Ф — это функция активации).
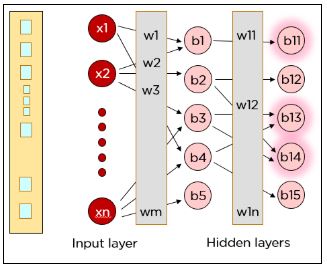
Вышеупомянутые шаги выполняются снова во втором скрытом слое, после чего информация достигает выходного слоя. А затем один из нейронов в выходном слое должен активироваться (в зависимости от значения функции активации).
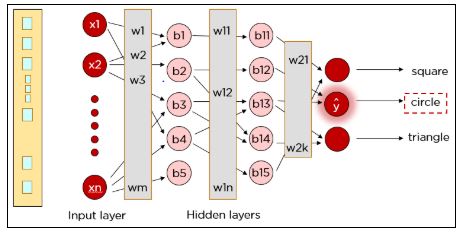
Как видите, наш правильный результат был квадратом, но нейронная сеть предсказала круг. Итак, что-то пошло не так?
Нейронную сеть необходимо обучать до тех пор, пока прогнозируемые выходные данные не будут совпадать с правильными. Сравнение осуществляется путем вычисления функции потерь.
Функция потерь определяет ошибку прогноза и сообщает об этом нейронной сети. Это называется алгоритмом обратного распространения ошибки (backpropagation).
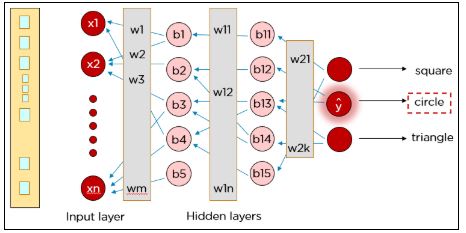
Чтобы уменьшить ошибку, мы корректируем веса, и сеть продолжает обучение с ними.
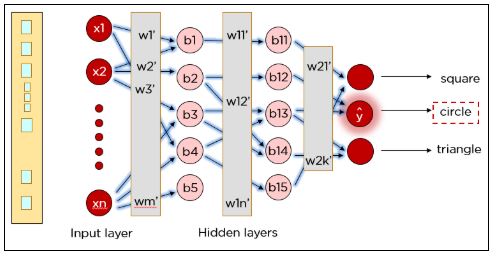
Снова вычисляется функция потерь, и процедура обратного распространения ошибки запускается вновь — до тех пор, пока ошибки не перестанут уменьшаться.
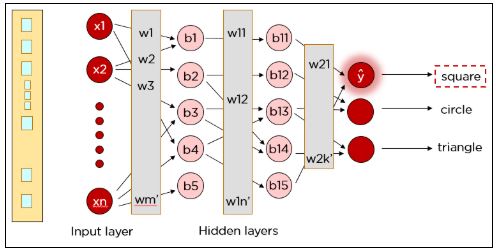
Точно так же нашу сеть можно обучить предсказывать круги и треугольники.
[machinelearning_ad_block]Платформы глубокого обучения
Теперь, когда вы хорошо понимаете, как работают нейронные сети, давайте кратко рассмотрим некоторые из основных платформ глубокого обучения.
Torch
Torch был разработан с использованием языка LUA и реализован на языке C. Реализация на языке Python называется PyTorch.
Keras
Keras — это фреймворк Python для глубокого обучения. Его большим плюсом является возможность использовать код как на CPU, так и на GPU.
TensorFlow
TensorFlow — это библиотека глубокого обучения с открытым исходным кодом, созданная Google. Она разработана на C++ и реализована на Python. Keras можно запускать поверх TensorFlow.
DL4J
Deep Learning for Java (DL4J) — первая библиотека глубокого обучения, написанная для Java и Scala. Она интегрирована с Hadoop и Apache Spark.
Введение в TensorFlow
TensorFlow от Google в настоящее время является самой популярной библиотекой глубокого обучения в мире. Она основана на концепции тензоров, которые являются векторами или матрицами в n-мерном пространстве.
Ниже приведен пример одномерного, двухмерного и трехмерного тензоров.
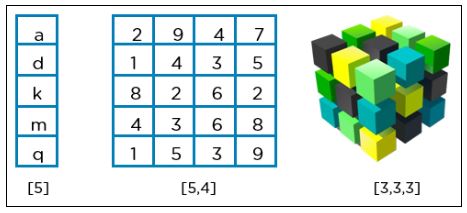
Все вычисления, выполняемые с использованием TensorFlow, включают в себя тензоры.
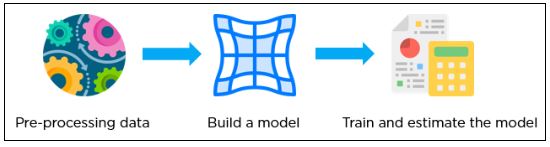
Ниже представлена простая архитектура работы TensorFlow:
Реализация кейса при помощи TensorFlow
Давайте воспользуемся набором данных из репозитория машинного обучения UCI и предскажем (на основе определенных критериев), превышает ли доход человека 50 тысяч долларов в год.
Этот набор данных имеет следующие атрибуты:
- age (возраст)
- work-class
- fnlwgt (окончательный вес)
- education (образование)
- education-num
- marital-status (семейное положение)
- occupation (вид деятельности)
- relationship (отношения)
- race (раса)
- sex (пол)
- capital-gain
- capital-loss
- hours-per-week
- native-country (родная страна)
- salary (оклад)
Приступим к демонстрации:
- Импортируем необходимые библиотеки:

2. Определим пути, где расположены наши данные, а также зададим переменные столбцов.

3. При помощи библиотеки Pandas создадим тестовый и обучающий набор данных:

4. Выведем на экран размер тестового и обучающего набора данных:

5. Установим для столбца label значение 0 — если оно <= 50 000, и 1 — если оно >= 50 000.
6. Подсчитаем общее количество уникальных значений в наборах данных:

7. Проверим типы данных в наших столбцах:

8. Разделим переменные на категориальные и числовые (непрерывные):

9. Создадим непрерывные переменные:
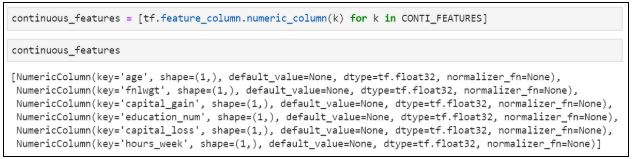
10. Создаем переменную relationship, добавляем категориальные переменные:

11. Создаем модель с двумя классами и непрерывными и категориальными переменными:
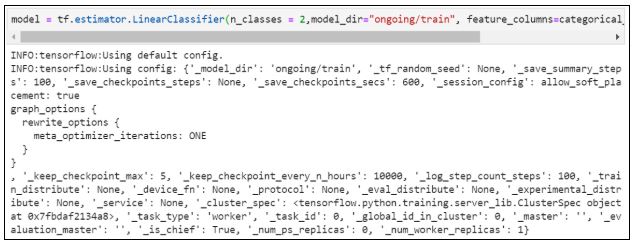
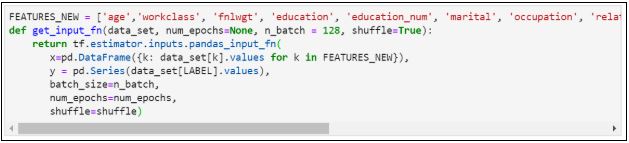
12. Присваиваем значения и определяем функцию:
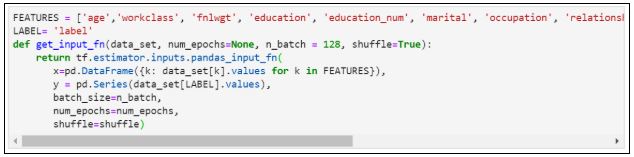
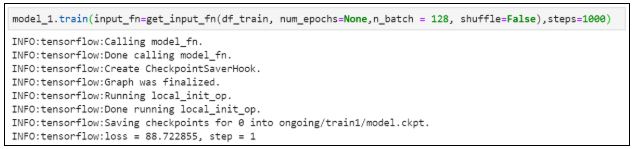
13. Обучаем модель:

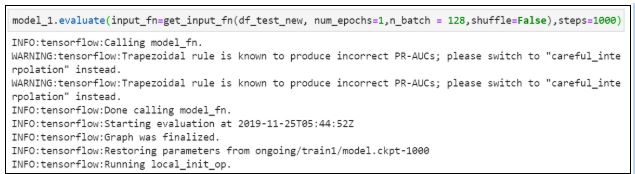
14. Оцениваем модель:

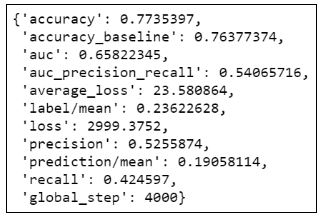
15. Возводим переменную age в квадрат:

16. Создаем новый датафрейм, состоящий из обучающих и тестовых данных:

17. Заново определяем категориальные и непрерывные переменные:

18. Создаем модель с линейным классификатором:
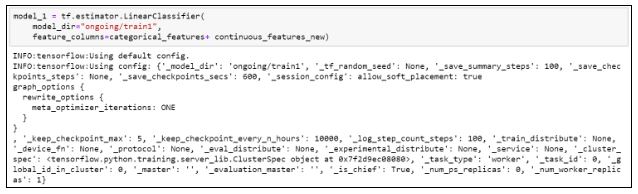
19. Присваиваем новые значения и заново определяем функцию:
20. Обучаем модель:
21. Оцениваем модель:
22. Осуществляем предсказание при помощи обученной модели:
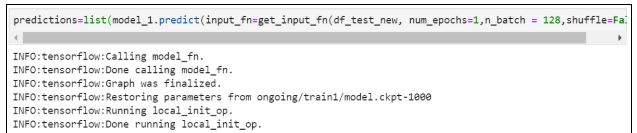
23. Проверяем предсказание на тестовом наборе данных:
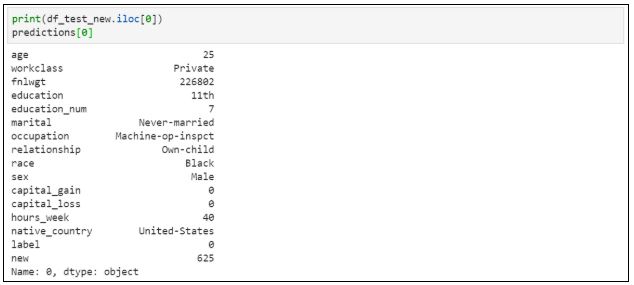
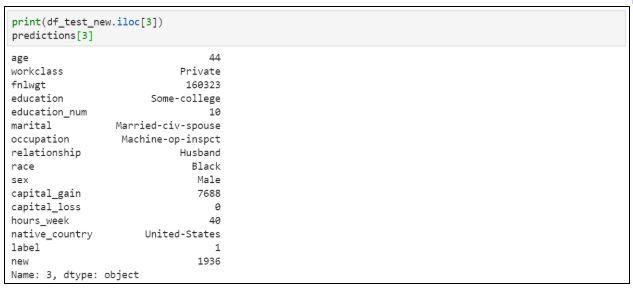
Как видите, модель успешно смогла предсказать два результата из набора тестовых данных.
Заключение
Надеемся, что после прочтения этой статьи вы уже лучше понимаете, как работают нейронные сети, что такое веса, смещения и функции активации. Также вы узнали о TensorFlow и о том, как работают тензоры. Наконец, вы знаете, как использовать TensorFlow для классификации людей по их заработной плате на основе конкретных характеристик.
