
В современном цифровом мире нас засыпают бесконечным потоком информации. Мы постоянно прокручиваем социальные сети и 24 часа в сутки имеем доступ к новостным каналам. Таким образом, существует множество новостей, которые нам надо знать и мы должны быть в состоянии их все быстро переварить.
Итак, давайте разберем упражнение по сжатию новостных статей до размера, более удобного для их восприятия.
Мы спарсим примерную статью, используя библиотеки request и BeautifulSoup, а затем сформируем ее краткое изложение при помощи великолепной библиотеки gensim. Вы можете загрузить Jupiter Notebook с кодом статьи с GitHub.
Итак, перейдем непосредственно к делу!
# Импорт необходимых библиотек import requests from bs4 import BeautifulSoup from gensim.summarization import summarize
Теперь выберем интересную статью:
Выбрав статью, мы можем загрузить ее содержимое:
# Получаем текст страницы url = 'https://www.npr.org/2019/07/10/740387601/university-of-texas-austin-promises-free-tuition-for-low-income-students-in-2020' page = requests.get(url).text
Вебскрейпинг
Теперь приступим непосредственно к вебскрейпингу!
Сначала мы превратим содержимое страницы в объект BeautifulSoup, что позволит нам анализировать HTML-теги.
# Turn page into BeautifulSoup object to access HTML tags soup = BeautifulSoup(page)
Затем нам нужно выяснить, какие HTML-теги содержат заголовок и основной текст статьи. В качестве отличного учебника по HTML можно использовать сайт HTML.com.
[python_ad_block]Чтобы это сделать, мы будем использовать инструменты разработчика Google Chrome. Откроем статью в новой вкладке, кликнем по ней правой кнопкой мыши и в выпавшем меню выберем пункт Inspect (Просмотр кода). Это вызовет DevTools (инструменты разработчика) в панели справа:
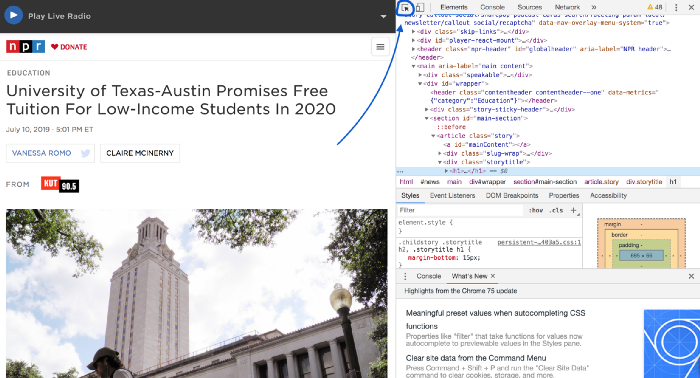
Чтобы найти все HTML-теги, соответствующие всему, что вы видите на странице, нажмите на небольшую кнопочку наверху. На картинке она отмечена синей стрелкой.
Теперь наводим указатель мыши на фрагмент страницы, который мы хотим исследовать. В данном случае это заголовок и основной текст статьи. И мы видим, какие теги отвечают за формат данного текста.
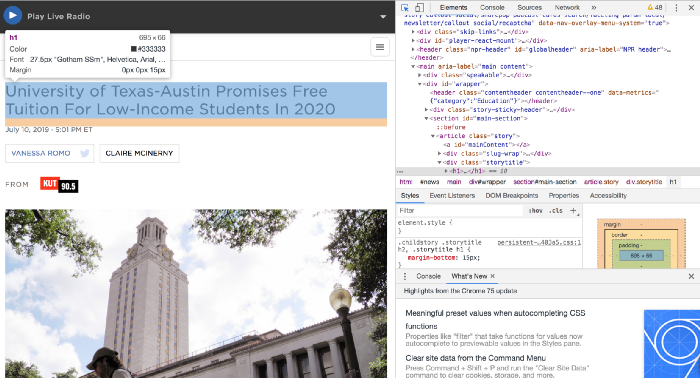
Заголовок статьи окружен c двух сторон тегом <h1>. Загрузим этот фрагмент следующим образом:
# Get headline
headline = soup.find('h1').get_text()
Основной текст статьи окружен тегами <p>. На этот раз нам нужно будет найти все такие теги, содержащиеся на странице, поскольку в них заключен каждый абзац статьи.
# Get text from all <p> tags.
p_tags = soup.find_all('p’)
# Get the text from each of the “p” tags and strip surrounding whitespace.
p_tags_text = [tag.get_text().strip() for tag in p_tags]
Если вы изучите текст, который мы сохранили в переменную p_tags_text, то заметите, что есть некоторые фрагменты текста, не относящиеся к основной статье, например имя автора и некоторые подписи к изображениям. Они также заключены в теги <p>, поэтому и оказались здесь. Чтобы очистить этот текст от фрагментов, которые не являются частью основной статьи, мы в качестве фильтров используем несколько представлений списков.
В этой статье подписи к изображениям содержат символ новой строки \n. Поскольку мы знаем, что в настоящих предложениях в статье не бывает случайных переносов строк, мы можем смело отказаться от таких фрагментов. Точно так же мы можем отбрасывать фрагменты текста, не содержащие точки, поскольку мы знаем, что любое правильное предложение в статье будет содержать точку. Так мы сможем отбросить имя автора и некоторые другие ненужные нам вещи.
# Filter out sentences that contain newline characters '\n' or don't contain periods. sentence_list = [sentence for sentence in p_tags_text if not '\n' in sentence] sentence_list = [sentence for sentence in sentence_list if '.' in sentence] # Combine list items into string. article = ' '.join(sentence_list)
Резюме статьи
Теперь, имея полный текст статьи, мы хотим получить его резюме (краткий пересказ содержания статьи).
Gensim — отличный пакет Python для большого количества задач нейролингвистического программирования (НЛП). Он включает в себя довольно надежную функцию резюмирования, которой достаточно легко пользоваться. Она реализует разновидность алгоритма TextRank.
Для использования этой функции нам нужна лишь одна строчка кода:
summary = summarize(article_text, ratio=0.3)
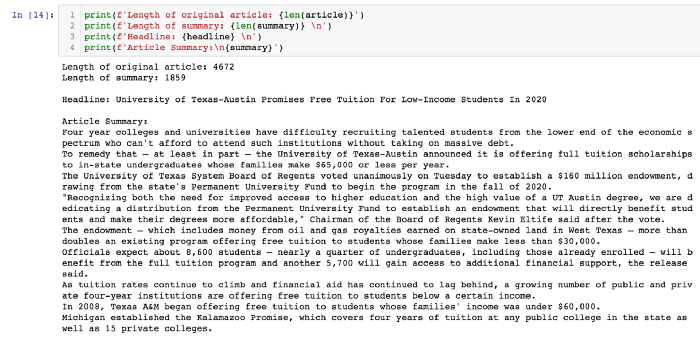
Вот и все, мы сделали, что хотели! Мы извлекли заголовок статьи и получили краткое изложение ее содержания. Теперь вы можете понять суть статьи примерно в три раза быстрее и сэкономить время для других дел.
Перевод статьи Chaim Gluck «Easily Web Scrape and Summarize News Articles Using Python».
