Начало — Вебскрейпинг для сравнения цен на сайтах. Часть 1.
Продолжаем заниматься вебскрейпингом сайтов электронной коммерции с целью сравнения цен. В первой части мы исследовали использование библиотеки Selenium для автоматизации процесса парсинга названий продуктов и цен с сайта Lazada.
Во второй части мы продолжим делать тоже самое с сайтом Shopee. Мы сосредоточимся на конкретных проблемах, возникающих при парсинге платформы Shopee и рассмотрим альтернативу библиотеке Selenium, которая работает даже лучше!
Итак, приступим к делу!
Парсить платформу Shopee при помощи Selenium оказалось не так просто. Мы выделили четыре основные проблемы, вставшие перед нами:
1. Всплывающие окна сообщений (дополнительная сложность — низкая)
Первая проблема, с которой мы сталкиваемся, это всплывающие окна, появляющиеся при проведении поиска:
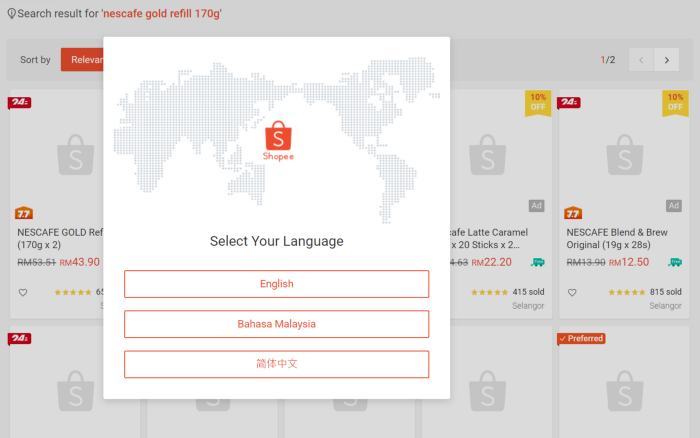
Мы можем автоматизировать процесс закрытия всплывающих окон при помощи следующего кода:
WebDriverWait(browser, 20).until(EC.element_to_be_clickable( (By.XPATH, “//div[@class=’shopee-modal__container’]//button[text()=’English’]”))).click()
2. Разные цены на один и тот же товар (дополнительная сложность — низкая)
Как оказалось, иногда в результатах поиска Shopee один товар может иметь два разных значения цены с одинаковым названием класса. Это связано с тем, что на товар может действовать скидка при покупке определенного объема (количества):

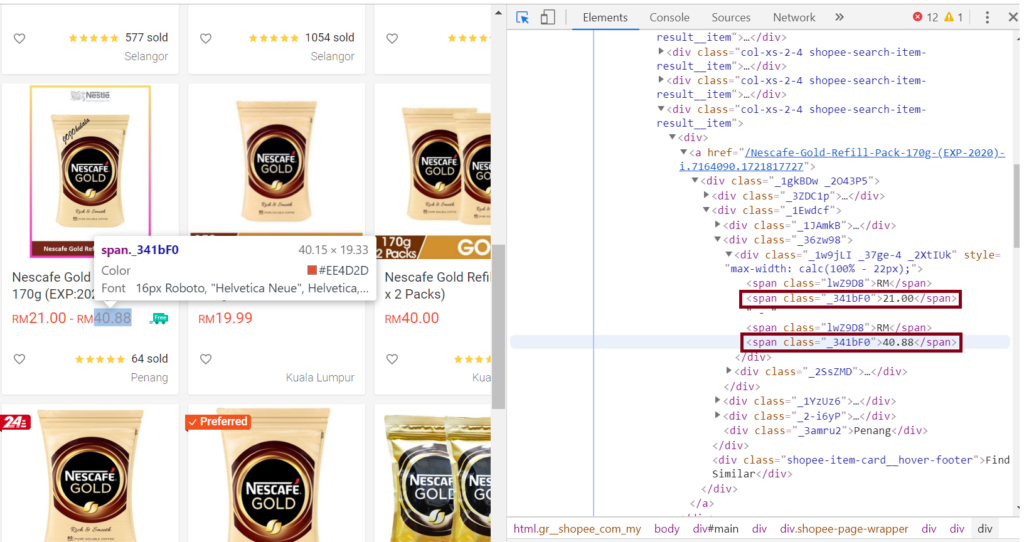
При помощи библиотеки Selenium мы можем выбрать то значение, которое хотим, используя селектор XPath. Таким образом, мы выбираем второе значение диапазона, которое отражает цену без скидки.
product_prices = browser.find_elements_by_xpath('//a/div/div[2]/div[2]/div[@*]/span[2]')
3. Поиск выдает 50 товаров на странице, но удается отобрать только 15 (дополнительная сложность — высокая)
Платформа Shopee — это динамический сайт, на котором новые товары отображаются только при прокрутке страницы вниз. В этом нет ничего необычного, ведь это позволяет странице загружаться быстрее, не загружая сразу все элементы (Facebook работает так же).

Таким образом, это требует от нас автоматизации прокрутки страницы вниз, причем с учетом небольшого времени ожидания для появления товаров. Так, как будто вы это делаете вручную.
Selenium позволяет автоматизировать прокрутку браузера, но сценарий для этой конкретной автоматизации будет несколько длинным. Дело в том, что нам нужно будет воспроизвести ручной процесс прокрутки вниз, а затем подождать несколько секунд, пока элементы страницы появятся и будут обработаны. И этот процесс нужно будет повторять, пока мы не дойдем до конца страницы.
[python_ad_block]Исходя из этого, напишем следующий код:
import time
scroll_pause_time = 1
while True:
last_height = driver.execute_script(“return document.body.scrollHeight”)
browser.execute_script(“window.scrollTo(0, window.scrollY + 500);”)
time.sleep(SCROLL_PAUSE_TIME)
new_height = browser.execute_script(“return document.body.scrollHeight”)
if new_height == last_height:
browser.execute_script(“window.scrollTo(0, window.scrollY + 500);”)
time.sleep(scroll_pause_time)
new_height = browser.execute_script(“return document.body.scrollHeight”)
if new_height == last_height:
break
else:
last_height = new_height
continue
Видно, что код усложняется и сам процесс также несколько замедляется из-за возникающих пауз.
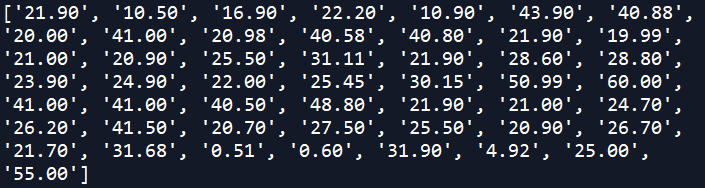
4. Невозможность выделить элементы товаров
Как вы могли видеть ранее, имена элементов нельзя выделить, даже если их можно идентифицировать с помощью селекторов классов или XPath. Также их можно видеть при помощи инструментов разработчика Chrome. Из-за этого функция find_elements() возвращает не имена элементов, а пустые строки.
Тут, надо честно признаться, я встал в тупик. При более тщательном рассмотрении выяснилось, что для свойства CSS user-select установлено значение none. Это означает, что пользователи не могут выделять и копировать текст.
Чтобы манипулировать свойствами CSS, нам нужно написать код на JavaScript. А это не то, в чем в настоящее время я силен.
К счастью, тут я обнаружил более простой способ вебскрейпинга Shopee: использовать API платформы для запросов результатов поиска.
Нам очень повезло, что мы обнаружили этот вариант, так как далеко не все сайты делятся своим API. Поскольку Shopee имеет API для парсинга элементов товаров, будет гораздо проще воспользоваться именно этим способом.
Таким образом, вместо автоматизации с использованием библиотеки Selenium напишем следующий код:
import requests
Shopee_url = 'https://shopee.com.my'
keyword_search = 'Nescafe Gold refill 170g'
headers = {
‘User-Agent’: ‘Chrome’,
‘Referer’: ‘{}search?keyword={}’.format(Shopee_url, keyword_search)
}
url = ‘https://shopee.com.my/api/v2/search_items/?by=relevancy&keyword={}&limit=100&newest=0&order=desc&page_type=search'.format(keyword_search)
# Shopee API request
r = requests.get(url, headers = headers).json()
# Shopee scraping script
titles_list = []
prices_list = []
for item in r['items']:
titles_list.append(item['name'])
prices_list.append(item['price_min'])
Далее, для работы с полученными данными создадим датафрейм Pandas:
Shopee = pd.DataFrame(zip(titles_list, prices_list), columns=[‘ItemName’, ‘Price’])
Вывод данных на экран даст следующий результат:
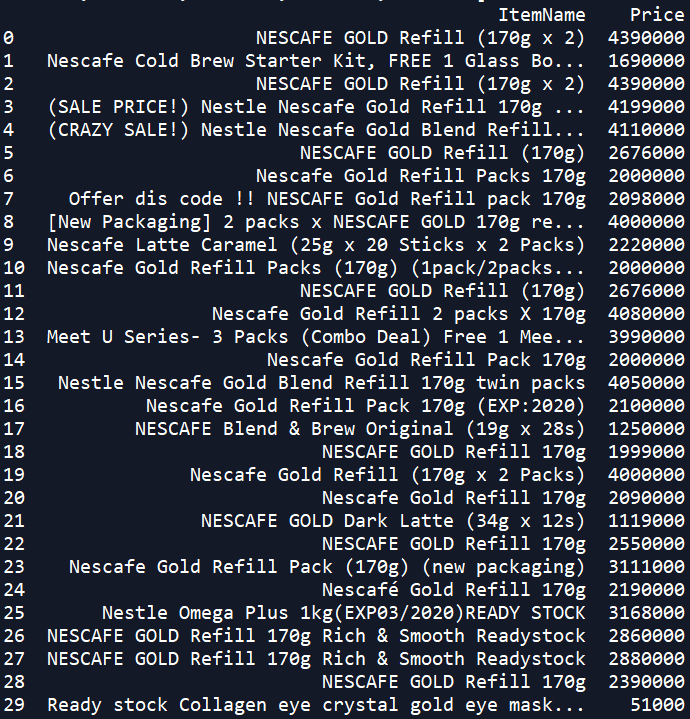
Как и в случае с датасетом из платформы Lazada, нам нужно произвести определенную очистку полученых данных. Главным образом, нам нужно сделать следующее:
- Преобразовать значения в столбце с ценами в тип
floatс двумя знаками после запятой - Удалить из нашего набора нерелевантные записи (я ищу кофе, а не коллагеновые маски для глаз!)
- Удалить двойные упаковки
# Удаляем строку ‘RM’ и меняем тип данных на float
dfS[‘Price’] = dfS[‘Price’] / 100000
# Удаляем случайные записи
dfS = dfS[dfS[‘ItemName’].str.contains(‘170g’) == True] # Poor search function Shopee!!!
# Удаляем двойные упаковки
dfS = dfS[dfS[‘ItemName’].str.contains(‘[2x\s]{3}|twin’, flags=re.IGNORECASE, regex=True) == False]
Теперь давайте объединим датасеты из сайтов Lavada и Shopee! Для этого мы применим метод concat() из библиотеки Pandas.
# Добавляем столбец [‘Platform’] для каждой платформы dfL[‘Platform’] = ‘Lazada’ dfS[‘Platform’] = ‘Shopee’ # Объединяем датафреймы df = pd.concat([dfL,dfS])
Теперь, наконец, мы можем произвести сравнение двух платформ. Для начала выведем на экран статистические характеристики при помощи метода describe().
print(df.groupby([‘Platform’]).describe())

Далее построим графики данных, используя все тот же «ящик с усами».
sns.set() _ = sns.boxplot(x=’Platform’, y=’Price’, data=df) _ = plt.title(‘Comparison of Nescafe Gold Refill 170g prices between e-commerce platforms in Malaysia’) _ = plt.ylabel(‘Price (RM)’) _ = plt.xlabel(‘E-commerce Platform’) # выводим график на экран plt.show()
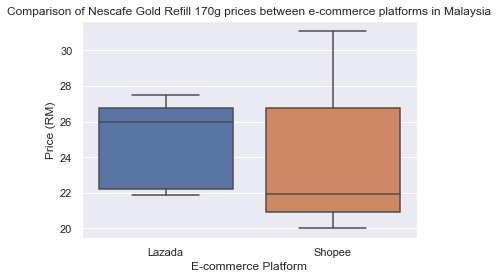
И вот мы сделали это! На основании сравнения одного товара видно, что платформа Shopee дешевле и там больше предложений.
Несколько замечаний перед тем как мы закончим:
- Очень полезно производить сравнение цен в разные периоды времени, чтобы анализировать динамику цен на конкретный товар. Для этого мы можем добавить столбец
datetimeи сохранить его в файл форматаcsv.
import time
# Add Timestamp
dfL[‘datetime’] = pd.Timestamp.today()
dfS[‘datetime’] = pd.Timestamp.today()
# Save dataframe to a csv file
timestamp = str(pd.Timestamp.today()).replace(":", ".")
df.to_csv('PriceComparison_{}.csv'.format(timestamp))
- Разумеется, вы можете парсить другие товары, просто изменив переменную
keyword_search. Но будьте готовы, что вам придется использовать другие способы для очистки полученных данных. - Здесь мы работали с очень небольшими наборами данных, поэтому все операции выполнялись очень быстро.
Перевод статьи Wilson Wong Web scraping E-commerce sites to compare prices with Python — Part 2.

