Мне часто говорили, что из двух основных платформ электронной коммерции в Малайзии (Lazada и Shopee) одна, как правило, дешевле и привлекает охотников за скидками, а другая обычно обслуживает менее чувствительных к ценам покупателей.
Что ж, я решил проверить это сам, устроив битву этих e-commerce платформ.
Для этого мы напишем код на Python с использованием библиотеки Selenium и веб-драйвера Chrome. Таким образом мы автоматизируем процесс извлечения информации и построения нужного нам набора данных. Мы будем получать следующую информацию:
- название товара
- его цену
Затем, при помощи библиотеки Pandas мы произведем базовый анализ этого датасета. В рамках данного процесса потребуется некоторая очистка данных, а затем мы визуализируем полученные результаты при помощи библиотек Matplotlib и Seaborn.
Сравнив две платформы, я обнаружил, что сайт Shopee более труден в плане получения от него данных по двум причинам:
- Он содержит назойливые всплывающие окна, которые появляются при открытии каждой страницы.
- Элементы классов сайта определены нечетко, некоторые элементы содержат несколько классов.
Поэтому мы начнем работать с сайтом Lazada, а к платформе Shopee вернемся во второй части.
Для начала, импортируем необходимые библиотеки:
# Web Scraping from selenium import webdriver from selenium.common.exceptions import * # Data manipulation import pandas as pd # Visualization import matplotlib.pyplot as plt import seaborn as sns
Затем инициализируем глобальные переменные, а именно:
- Путь к веб-драйверу Chrome
- Адрес сайта
- Элемент, который мы будем искать
webdriver_path = 'C://Users//me//chromedriver.exe' # Enter the file directory of the Chromedriver Lazada_url = 'https://www.lazada.com.my' search_item = 'Nescafe Gold refill 170g' # Chose this because I often search for coffee!
Далее запустим браузер Chrome. Мы это сделаем с некоторыми специальными опциями:
# Выберем нужные опции для запуска Chrome
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('start-maximized')
options.add_argument('disable-infobars')
options.add_argument('--disable-extensions')
# Откроем браузер Chrome
browser = webdriver.Chrome(webdriver_path, options=options)
browser.get(Lazada_url)
Немного остановимся на этих самых опциях. Аргумент » --headless» позволяет запускать скрипт в браузере, работающем в фоновом режиме. Обычно я бы рекомендовал не добавлять этот аргумент в параметры Chrome, чтобы вы могли видеть автоматизацию в действии и легче выявлять ошибки. С другой стороны, это, конечно, менее эффективно!
Другие параметры, start-maximized, disable-infobars и -disable-extensions добавляются для обеспечения более плавной работы браузера. (Расширения, имеющие доступ к работе с веб-страницами, могут сорвать процесс нашей автоматизации).
Запуск этого небольшого блока кода откроет нам браузер.
[python_ad_block]Теперь, открыв браузер, нам нужно автоматизировать поиск нужного нам элемента. Инструменты Selenium позволяют искать HTML-документы, используя различные характеристики элементов. А именно: id, class, селекторы CSS и XPath (выражение пути в формате XML).
Но как нам определить, какие именно элементы следует искать? Проще всего это сделать, используя инструменты разработчика браузера Google Chrome.
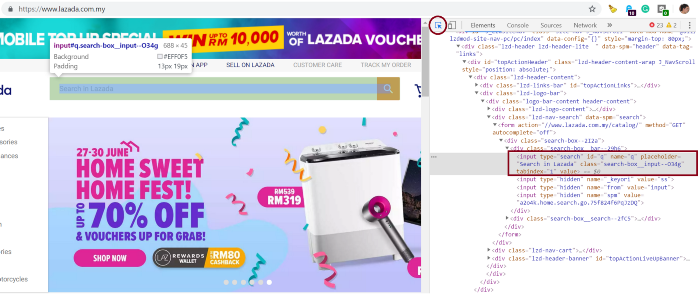
CTRL + Shift + I. Используйте селектор элементов, обозначенный красным кружком, для наведения курсора на элементы, которые хотите найти. Здесь мы видим, что в строке поиска есть id = ‘q’ (видно в красном поле).search_bar = browser.find_element_by_id('q')
search_bar.send_keys(search_item).submit()
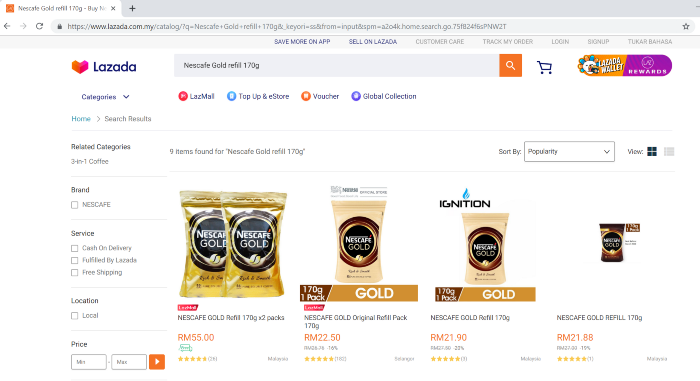
- headless в параметрах Chrome. Похоже, у нас здесь найдено 9 предметов!Ок, это была простая часть задачи. Теперь наступает более сложный этап, особенно если вы хотите извлечь информацию из сайта Shopee!
Чтобы понять, как добыть информацию о названии и цене товаров, для начала представим, что мы это делаем вручную. Нам нужно сделать следующее:
- Скопировать каждое название товара и его цену в электронную таблицу.
- Переходить на следующие страницы и повторять п. 1 до конца.
Именно так и будет выглядеть наш процесс автоматизации. Для этого нам нужно будет найти элементы, содержащие названия товаров и их цены, а также кнопку перехода на следующую страницу.
Используя все те же инструменты разработчика Chrome, мы видим, что названия продуктов и цены имеют имена классов c16H9d и c13VH6. Важно убедиться, что одни и те же имена классов применяются ко всем элементам на странице, чтобы обеспечить их успешное извлечение.
item_titles = browser.find_elements_by_class_name('c16H9d')
item_prices = browser.find_elements_by_class_name('c13VH6')
Далее, поместим эти элементы (item_titles и item_prices) в соответствующие списки:
# Инициализируем пустые списки
titles_list = []
prices_list = []
# Наполним их названиями товаров и ценами
for title in item_titles:
titles_list.append(title.text)
for price in item_prices:
prices_list.append(prices.text)
Распечатав оба списка, получим следующий результат:
[‘NESCAFE GOLD Refill 170g x2 packs’, ‘NESCAFE GOLD Original Refill Pack 170g’, ‘Nescafe Gold Refill Pack 170g’, ‘NESCAFE GOLD Refill 170g’, ‘NESCAFE GOLD REFILL 170g’, ‘NESCAFE GOLD Refill 170g’, ‘Nescafe Gold Refill 170g’, ‘[EXPIRY 09/2020] NESCAFE Gold Refill Pack 170g x 2 — NEW PACKAGING!’, ‘NESCAFE GOLD Refill 170g’] [‘RM55.00’, ‘RM22.50’, ‘RM26.76’, ‘RM25.99’, ‘RM21.90’, ‘RM27.50’, ‘RM21.88’, ‘RM27.00’, ‘RM26.76’, ‘RM23.00’, ‘RM46.50’, ‘RM57.30’, ‘RM28.88’]
Получив всю информацию с этой страницы, давайте перейдем на следующую. Здесь мы снова будем использовать метод find_element, но на этот раз с применением XPath. Последнее нужно потому, что кнопка перехода на следующую страницу имеет два класса, а метод find_element_by_class_name может находить элементы только из одного.
Также отметим, что нам здесь нужно указать браузеру, что делать, если кнопка перехода на следующую страницу отключена (то есть, если результаты отображаются только на одной странице или мы достигли конечной страницы результатов).
try:
browser.find_element_by_xpath(‘//*[@class=”ant-pagination-next” and not(@aria-disabled)]’).click()
except NoSuchElementException:
browser.quit()
Таким образом, мы закрываем браузер, если кнопка неактивна. А если активна, то идем на следующую страницу и повторяем процесс получения нужной информации.
К счастью, в данном случае у нас только девять элементов и все они помещаются на одной странице. Поэтому процесс вебскрейпинга здесь завершен.
Теперь проанализируем полученные нами данные при помощи библиотеки Pandas. Для начала преобразуем наши списки в датафрейм:
dfL = pd.DataFrame(zip(titles_list, prices_list), columns=[‘ItemName’, ‘Price’])
Распечатав датафрейм, можно убедиться, что данные были успешно получены:

Хотя наш датасет выглядит неплохо, он еще требует определенного улучшения. Если мы выведем на экран информацию о нем, использовав функцию pandas.info(), то увидим, что тип данных столбца price строковый — вместо нужного нам float. Это неудивительно, так как значения этого столбца содержат буквы RM (Малазийский ринггит) — обозначение валюты Малайзии. Однако, если тип данных столбца отличен от float или integer, то никаких статистических расчетов мы произвести не сможем.
Поэтому нам нужно убрать символ валюты и сконвертировать тип данных во float. Мы это сделаем при помощи следующей команды:
dfL[‘Price’] = dfL[‘Price’].str.replace(‘RM’, ‘’).astype(float)
Чудесно! Но это еще не все. Может быть, вы заметили еще одну аномалию в нашем наборе данных. Один из наших товаров — это двойной набор, и мы бы хотели удалить его из рассмотрения.
Очистка данных необходима для любого вида анализа данных, и сейчас мы отсеиваем ненужные нам записи при помощи следующего кода:
# This removes any entry with 'x2' in its title dfL = dfL[dfL[‘ItemName’].str.contains(‘x2’) == False]
В данном случае больше ничего делать не надо, но вы всегда должны проверять правильность данных в своих датасетах. Иногда в них могут появляться другие похожие товары, особенно если ваш поисковый запрос был недостаточно конкретен.
Например, если бы мы искали «nescafe gold refill» вместо «nescafe gold refill 170g», то было бы 117 позиций вместо 9, полученных нами ранее. И там было бы много ненужных нам товаров, например капсулы.
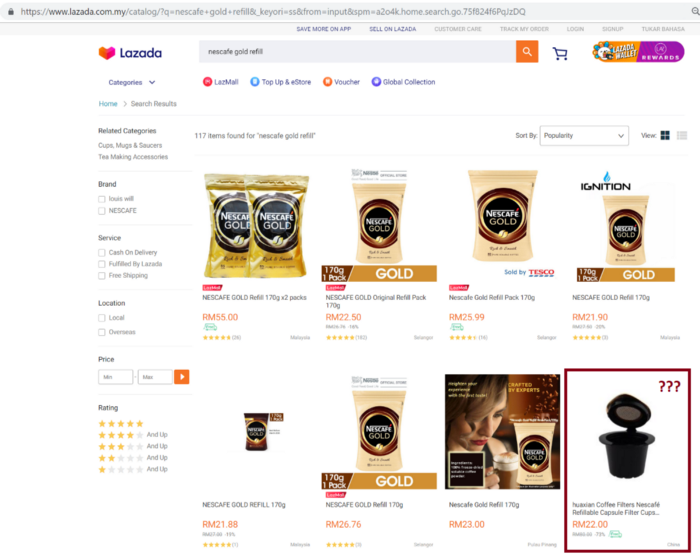
Тем не менее, не помешает еще раз отфильтровать набор данных с помощью следующего кода:
dfL = dfL[dfL[‘ItemName’].str.contains(‘170g’) == True]
В качестве финального штриха мы создадим столбец ‘Platform’ и присвоим каждому его элементу значение ‘Lazada’. Это пригодится нам в дальнейшем, когда мы захотим группировать наши данные из двух сайтов и сравнивать цены.
dfL[‘Platform’] = ‘Lazada’
Вот так, наш датасет наконец-то очищен и готов к использованию!
Теперь настало время для визуализации наших данных при помощи библиотек Matplotlib и Seaborn. Мы будем использовать «ящик с усами» (box plot) так как именно этот вид графика удачно представляет все нужные нам ключевые статистические характеристики. А именно:
- минимальную цену
- максимальную цену
- медиану
- 25-процентный и 75-процентный процентили
# Построим график sns.set() _ = sns.boxplot(x=’Platform’, y=’Price’, data=dfL) _ = plt.title(‘Comparison of Nescafe Gold Refill 170g prices between e-commerce platforms in Malaysia’) _ = plt.ylabel(‘Price (RM)’) _ = plt.xlabel(‘E-commerce Platform’) # Отобразим его plt.show()
Каждый ящик будет представлять свой сайт. По оси y отложена цена. Пока у нас только один ящик, так как данные с сайта Shopee нам только предстоит получить.
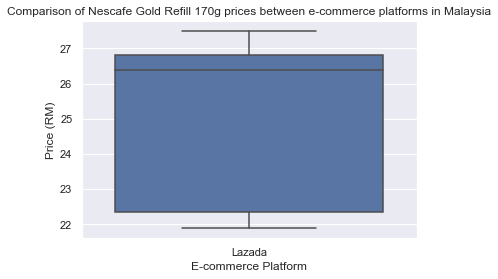
Мы видим, что цены на товар находятся в диапазоне от 21 до 28 ринггитов, а средняя цена — от 27 до 28 ринггитов. Также можно заметить, что у нашего ящика короткие «усы». Это говорит о том, что цены достаточно стабильны и не имеют резких выбросов.
Но это только для платформы Lazada! Во второй части мы рассмотрим конкретные проблемы, которые возникают при сканировании сайта Shopee, а затем построим еще один «ящик с усами» и завершим наше соревнование!
Вторая часть — Вебскрейпинг для сравнения цен на сайтах. Часть 2
Перевод статьи Wilson Wong Web scraping E-commerce sites to compare prices with Python — Part 1.

