Перевод статьи «Performant HTTP with Aiohttp in Python 3».
Что такое AIO?
Друзья, подписывайтесь на наш телеграм канал Pythonist. Там еще больше туториалов, задач и книг по Python.
Одно из критических замечаний, регулярно высказываемых в адрес Python, заключается в том, что в нем нет хорошей реализации параллелизма.
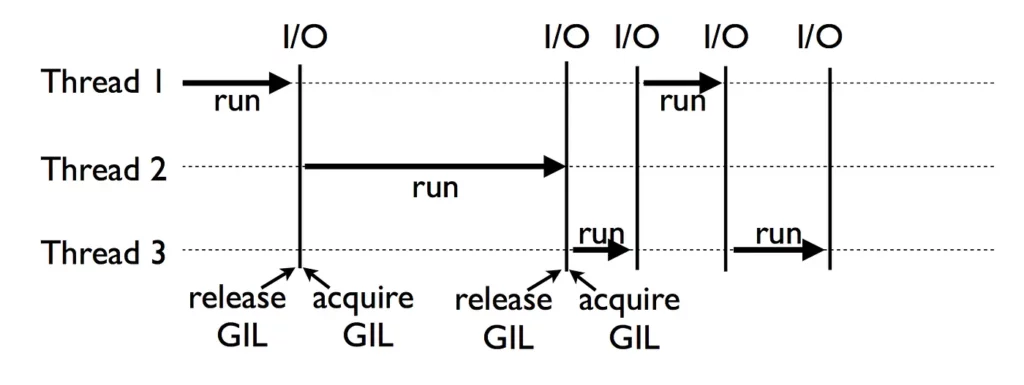
Если вы опытный программист на Python, то наверняка слышали о GIL или Global Interpreter Lock. Эта блокировка защищает доступ к объектам Python таким образом, что только один поток может одновременно выполнять байткод. Она необходима, поскольку Python (в частности, стандартная реализация CPython) не имеет потокобезопасного управления памятью.
Если позволить нескольким потокам работать с одной и той же памятью, могут произойти странные вещи. А подход Python к решению этой проблемы заключается в том, чтобы просто запретить это.
И это еще хуже: GIL приводит к накладным расходам из-за переключения контекста, так что выполнение одного и того же кода в двух разных потоках занимает больше времени, чем выполнение его дважды в одном и том же потоке.
Хотите скачать книги по Python в 2 клика? Тогда вам в наш телеграм канал PythonBooks
Итак, действительно ли параллелизм в Python невозможен? Вовсе нет! На самом деле, в нашем распоряжении есть несколько инструментов, каждый из которых имеет свои преимущества и недостатки.
Есть многопроцессорная обработка, которая хорошо работает во многих ситуациях, даже несмотря на большие начальные накладные расходы по сравнению с многопоточностью.
Кроме того, хотя я уже упоминал о том, что многопоточность в Python имеет некоторые недостатки по сравнению с другими языками, это не означает, что она бесполезна как способ структурировать выполнение кода. Есть и третий вариант, о котором я расскажу подробнее: асинхронное выполнение.
Пару лет назад среди языков программирования наблюдался некоторый асинхронный бум, и теперь, похоже, каждый основной язык имеет не только возможность асинхронного выполнения с помощью фьючерсов, корутин или обработчиков событий, но и синтаксис async/await. Подробнее об этом позже.
Так что же это такое? На первый взгляд, в Python async работает очень похоже на потоки, с одним существенным отличием — планированием.
Если вы используете потоки в Python, то ядро вашей операционной системы знает об этом и переключается между ними, когда считает нужным. Это называется вытесняющей многозадачностью. Код, выполняющийся в потоке, не знает, что его прерывают, и не может контролировать, когда это произойдет.
При использовании async Python сам выполняет планирование, что позволяет реализовать так называемую кооперативную многозадачность. Код, написанный с использованием этого подхода, должен каким-то образом передать управление интерпретатором, чтобы другой код мог продолжить выполнение. В JavaScript такая передача управления происходит при каждом вызове метода, а в Python вы можете контролировать, когда это происходит.
Зачем нам это нужно? Оказывается, есть класс операций, в которых имеет смысл на некоторое время передать управление: ввод/вывод!
Относительно выполнения логики программы получение чего-либо с жесткого диска занимает много времени, а получение ответа на сетевой запрос — еще больше. Если нам все равно придется ждать, почему бы не сделать за это время что-нибудь полезное?
Это также означает, что выполнение нескольких задач ввода-вывода может происходить практически одновременно. Это дает некоторые преимущества настоящего параллельного выполнения, если только время запуска новой задачи достаточно мало.
В программах, связанных со вводом-выводом, где вы читаете и записываете большое количество файлов, обмениваетесь данными с базами данных или отправляете большое количество сетевых запросов, это может значительно ускорить работу.
Немного истории
Кооперативная многозадачность в Python не является чем-то новым. Люди используют Python для реализации веб-серверов уже довольно давно, и столько же времени ищут способы увеличить количество запросов, которые они могут обрабатывать в минуту. Многие из этих решений основаны на каком-либо событийном цикле с кооперативным планированием.
Twisted, событийно-ориентированный фреймворк сетевого программирования, существует с 2002 года и используется до сих пор. На нем основаны такие проекты, как Scrapy, а Twitch использует его в своем бэкенде.
В настоящее время нет недостатка в библиотеках и фреймворках, реализующих ту или иную форму асинхронного рабочего процесса, причем многие из них специально предназначены для работы с сетями. Вот лишь некоторые из них:
- tornado, веб-сервер/фреймворк
- gevent, сетевая библиотека, основанная на Greenlet
- curio — библиотека для параллельного ввода-вывода, созданная тяжеловесом сообщества Python Dabeaz
- trio — библиотека, призванная сделать асинхронное программирование более доступным
Однако долгое время не хватало интегрированного в язык способа реализации асинхронного ввода-вывода, с функциональностью, упакованной прямо в стандартную библиотеку, и удобными ключевыми словами, позволяющими более прямолинейно и удобно программировать, избегая ада колбэков, который так хорошо знаком программистам, давно работающим на JavaScript.
Осознавая эту необходимость, в PEP 3156 было представлено видение BDFL Гвидо ван Россума по асинхронному вводу/выводу в Python, реализованное в Python 3.3 в виде модуля asyncio.
От редакции Pythonist: вас также может заинтересовать статья «asyncio — параллелизм в Python».
PEP 492, реализованный в Python 3.5, принес нам ключевые слова async/await, и с тех пор появилось множество других дополнений и улучшений, в частности, в версии 3.7.
Сразу оговорюсь, что я не пропагандирую использование asyncio вместо альтернатив, о которых я говорил ранее. У всех них есть свои достоинства и недостатки, но поскольку asyncio является частью стандартной библиотеки Python 3, с него можно начать.
Добро пожаловать в asyncio
Итак, вы убедились в том, что хотите попробовать асинхронность, и решили, что встроенный модуль asyncio — это то, что вам нужно. Какие же возможности вам доступны?
Во-первых, это сам модуль asyncio, который предоставляет несколько необходимых нам примитивов и на котором построены другие библиотеки, упомянутые в этом разделе. Примеры этих примитивов мы рассмотрим в практическом разделе ниже.
Цикл событий (event loop) — это то, что позволяет осуществлять всю кооперативную планировку. На высоком уровне это просто обычный цикл, который отслеживает все и обрабатывает события одно за другим, когда они происходят.
Цикл событий отслеживает задачи, которые помещаются в очередь, откуда их можно разбудить, когда завершится то, чего они ждут (если это вообще возможно). Задачи могут быть проверены на предмет завершения или отменены, если их результат больше не нужен или достигнут тайм-аут.
Задача (Task), в свою очередь, оборачивает корутину (Coroutine). Именно этот код выполняется, когда задача снова активируется. Далее мы на примерах рассмотрим, как это использовать. Пока просто запомните, что цикл событий фактически выполняет только одну задачу за раз и переключается только тогда, когда эта задача передает управление. Поэтому, если у вас есть одна задача, которая продолжает выполняться, то другие, которые все еще находятся в очереди, никогда не завершатся.
Многие библиотеки, которые вы наверняка будете использовать при работе с asyncio, содержатся в группе aio-libs на GitHub. Сюда входят aiohttp, о которой мы подробнее поговорим ниже, а также библиотеки для большого количества других задач, такие как aioftp, aiopg (для PostgreSQL), aioredis, aioelasticsearch, aiokafka, aiodocker, … Есть и другие библиотеки, построенные на их основе, в частности, пара веб-фреймворков, но я предоставлю вам возможность найти их самостоятельно.
Aiohttp — это, безусловно, самый активный проект aio-libs, который, возможно, является основным вариантом использования asyncio.
Aiohttp представляет собой HTTP-клиент и сервер с поддержкой Web-Sockets и таких тонкостей, как промежуточное ПО для обработки запросов и подключаемая маршрутизация.
Вики предоставляет два минимальных примера для начала работы с клиентом или сервером прямо на первой странице, что позволяет быстро опробовать их в работе.
Перейдем к коду
Начнем с самого простого примера:
import asyncio
async def a_square(x):
print(f'Asynchronously squaring {x}!')
return x ** 2
# This will only work in Python 3.7 and above
asyncio.run(a_square(2))
Если вы не используете версию Python 3.7 или выше, то вам необходимо заменить вызов run на что-то вроде:
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(a_square(2))
finally:
loop.close()
Довольно просто, не так ли? Функция a_square является корутиной. Ключевое слово async перед определением функции означает, что если вы ее вызовете, на самом деле ничего не произойдет, а произойдет только тогда, когда вы обернете ее в задачу (Task), и цикл событий разбудит ее для выполнения вычислений.
В большинстве случаев нам не нужно делать это явно. Здесь функция run позаботилась обо всем: она запустила цикл, обернула наш корутинный объект и запланировала его как задачу, после чего он немедленно начал выполняться, так как других задач не было.
Рассмотрим кое-что посложнее. Мы можем выстраивать цепочки coroutine, заставляя их ждать друг друга. Например:
import asyncio
async def sleeper(x):
await asyncio.sleep(x)
return x + 1
async def waiter(x):
sleepy_result = (await sleepy(x)) ** 2
return sleepy_result
# python >= 3.7
asyncio.run(waiter(2))
Здесь корутина waiter должна дождаться завершения работы корутины sleeper.
asyncio.sleep() — это асинхронная версия time.sleep(), поэтому она также является корутинной функцией, как и waiter и sleeper.
Ключевое слово await здесь делает несколько вещей. Во-первых, оно гарантирует, что все, что мы передаем ему, будет обернуто в задачу. Во-вторых, оно назначает эту задачу в очередь активного цикла и, когда задача будет выполнена, возвращает результат.
Это также означает, как вы уже поняли из названия, что код после этой строки начнет выполняться только тогда, когда этот результат будет доступен. Если вы хотите запланировать задачу и продолжить ее выполнение, то это тоже возможно:
import asyncio
async def delayed_print(text, time=1):
await asyncio.sleep(time)
print(text)
async def main_coro():
# python >= 3.7
task1 = asyncio.create_task(delayed_print("I'm printed second!", 2))
# python >= 3.3
task2 = asyncio.ensure_future(delayed_print("I'm printed first!"))
await asyncio.gather(
task1,
task2,
delayed_print("I'm printed last!", 3)
)
# python >= 3.7
asyncio.run(main_coro())
Здесь есть несколько интересных моментов.
Во-первых, мы видим функцию create_task, которая была добавлена в Python 3.7. Она принимает корутину, который оборачивается в Task и планирует выполнение. До версии 3.7 ее эквивалентом была функция ensure_future (которая на самом деле является более низкоуровневой, но выполняет то же самое).
Затем есть функция gather, которая, как следует из названия, собирает результаты всех переданных ей задач и корутин и возвращает их в виде списка.
Теперь, когда мы разобрались с основами, давайте перейдем к тому, ради чего мы, собственно, и собрались: aiohttp! Следующий пример демонстрирует работу клиентской части:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def fetch_all(urls):
async with aiohttp.ClientSession() as session:
texts = await asyncio.gather(*[
fetch(session, url)
for url in urls
])
return texts
years_to_fetch = [f'https://en.wikipedia.org/wiki/{year}' for year in range(1990, 2020)]
asyncio.run(fetch_all(years_to_fetch))
Этот код представляет собой версию примера на первой странице документации aiohttp с несколькими запросами. Он получает (HTML) текст страниц Википедии за 1990-2019 годы.
Эти GET-запросы запускаются параллельно, поэтому выполнение всех из них занимает примерно столько же времени, сколько выполнение самого длинного.
От редакции Pythonist: также предлагаем почитать «Пособие по HTTP-запросам в Python и Web API».
Конечно, есть ограничения на количество запросов, которые можно выполнить подобным образом. Если вам нужно выполнить тысячи запросов, то, вероятно, следует запускать их частями, но в большинстве случаев это будет работать, как показано на рисунке.
Как и в случае с обычной библиотекой requests, вы можете отправлять не только GET-запросы. Если вам интересны другие методы, вы всегда можете почитать об их использовании в документации.
Библиотека aiohttp также включает в себя серверный компонент, укомплектованный маршрутизатором и всем необходимым для работы с простым веб-сервером или REST API. В следующем примере показаны некоторые вещи, которые можно сделать с его помощью:
from aiohttp import web
async def empty(request):
return web.Response()
async def get_json(request):
return web.json_response({
'path_name_variable': request.match_info.get('name'),
'query_param_a': request.rel_url.query.get('a'),
'query_param_b': request.rel_url.query.get('b'),
})
async def redirected(request):
location = request.app.router['default'].url_for()
raise web.HTTPFound(location=location)
async def index(request):
return web.FileResponse('./index.html')
app = web.Application()
app.add_routes([
web.get('/', redirected),
web.get('/empty', empty),
web.get('/json/{name}', get_json),
web.static('/index', index, name='default'),
])
web.run_app(app)
Это последний пример и самый подробный. Он представляет веб-приложение с 4 маршрутами (routes): один маршрут, который перенаправляется на другой, еще один возвращает пустой ответ, третий возвращает статический HTML-файл, а четвертый имеет необязательную переменную пути (path variable) и параметры запроса (query parameters) и возвращает JSON-документ.
Очередь на сверхвысоких скоростях
Одним из интересных моментов в цикле событий asyncio является то, что он подключаемый. Это означает, что вы можете создать свою собственную реализацию. Хотя стандартная реализация, основанная на libev, уже достаточно хороша, есть и другой вариант. Более быстрый вариант!
Эта реализация называется uvloop и основана на libuv — библиотеке асинхронного ввода-вывода, изначально разработанной для node.js, а теперь используемой, в частности, в Julia.
Библиотека uvloop проста в использовании и позволяет ускорить практически все, что вы делаете с помощью asyncio, поэтому было бы стыдно не упомянуть о ней здесь.
От редакции Pythonist: также предлагаем почитать «Асинхронность в Django: бесконечная история».

