
Предыдущая статья: Чат-бот на Python (Deep Learning + TensorFlow). Часть VII: обучение модели.
Добро пожаловать в восьмую часть серии статей про создание чат-бота при помощи алгоритмов глубокого обучения и библиотеки Tensorflow. Сейчас мы обсудим нашу модель.
Основное отличие для нас состоит в том, что мы не будем использовать группировку (bucketing), паддинг (padding), но добавим механизм внимания (attention mechanisms). Давайте сначала вкратце поговорим об этих вещах.
Во-первых, если вы хоть немного знакомы с нейронными сетями, давайте рассмотрим задачу sequence-to-sequence, где входная и выходная последовательности не всегда будут иметь одинаковую длину. Мы можем рассматривать это как в контексте чат-ботов, так и в других областях.
В случае с чат-ботом однословные комментарии могут давать ответы из 20 слов, а длинные комментарии могут возвращать однословные ответы, и каждый ввод будет отличаться от предыдущего с точки зрения символов, слов и многого другого. Самим словам будут назначены произвольные или осмысленные идентификаторы (при помощи токенизации слов), но как мы будем обрабатывать переменную длину?
Один из вариантов — просто сделать все словосочетания длиной 50 слов (например). Тогда, если предложение, например, состоит из 35 слов, мы можем добить его до 50 (процедура паддинга), добавив еще 15 слов. Любые данные длиннее 50 слов мы можем либо не использовать для обучения, либо обрезать.
К сожалению, это может сильно затруднить обучение, особенно в случае очень коротких ответов, которые могут быть весьма распространенными. Тогда большинство слов / токенов будут просто формальным заполнением. Первоначальная модель seq2seq (перевод с английского на французский) для решения этой проблемы использовала группировку (bucketing), и обучение происходило в четырех группах отдельно. Например, можно разбить на группы 5-10, 10-15, 20-25, и 40-50 и помещать наши пары вопрос — ответ в наиболее подходящие по размеру. Но это тоже не идеальное решение.
Далее, у нас еще есть код NMT, который может работать входными данными произвольных размеров без группировки и паддинга! Более того, данный код также содержит в себе поддержку механизма внимания (attention mechanisms). Этот механизм представляет собой попытку добавить поддержку долгой краткосрочной памяти (LSTM) в рекуррентные нейронные сети (RNN). А в конце концов мы будем использовать двунаправленные рекуррентные сети (BRNN). Давайте теперь обсудим эти решения.
Долгая краткосрочная память (LTSM)
В общем случае долгая краткосрочная память (LTSM) может достаточно хорошо запоминать последовательности длиной 10-20 токенов. Но для более длинных токенов производительность резко падает, сеть начинает забывать токены, чтобы освободить место для новых.
В нашем случае токены — это слова, поэтому базовая долгая краткосрочная память (LSTM) должна быть способна изучать предложения длиной от 10 до 20 слов. Но если мы будем увеличивать длину предложения, то, скорее всего, результат будет не слишком хорош.
Механизм внимания используется для увеличения «продолжительности концентрации внимания», что помогает сети охватить, например, более 30, 40 или даже 80 слов.
Представьте, как вам было бы трудно, если бы вы могли отвечать другим людям только 3-10 словами за раз, при этом обрабатывая примерно такое же количество слов, причем на отметке в 10 слов вы в любом случае испытывали бы затруднения.
Черт возьми, в последнем предложении вы бы уловили только «Представьте, как вам было бы трудно, если бы вы…» после чего вам нужно было бы начать хотя бы строить свой ответ из 10 слов. При небольшом сдвиге вы получите «вам было бы трудно, если бы вы только могли…». Опять же, это не вполне связно, и дать здесь хороший ответ весьма затруднительно.
И даже если вы дойдете до точки, когда знаете, что вам нужно что-то вообразить, то что дальше? Чтобы понять, что нужно представить, вы должны подождать и увидеть будущие элементы предложения, но к тому времени, когда мы дойдем до этих будущих элементов, мы уже давно прошли ту часть, где мы должны были представить, на что это будет похоже.
И тут на сцену выходит двунаправленная рекуррентная нейронная сеть (BRNN).
[machinelearning_ad_block]Двунаправленная рекуррентная нейронная сеть (BRNN)
Мы можем неплохо решать многие seq2seq-задачи, например, связанные с языковым переводом, преобразовывая слова на месте и изучая простые шаблоны грамматики, поскольку многие языки синтаксически похожи. А в случае общения на естественных языках, а также при переводе, скажем, с английского на японский, важнее контекст, поток и т. д.
Двунаправленная рекуррентная нейронная сеть (BRNN) предполагает, что данные во входной последовательности как в настоящем, так и в прошлом, и в будущем одинаково важны. «Двунаправленная» часть двунаправленной рекуррентной нейронной сети (BRNN) может быть довольно хорошо описана. Ввод данных происходит в двух направлениях. Это можно проиллюстрировать следующей картинкой:
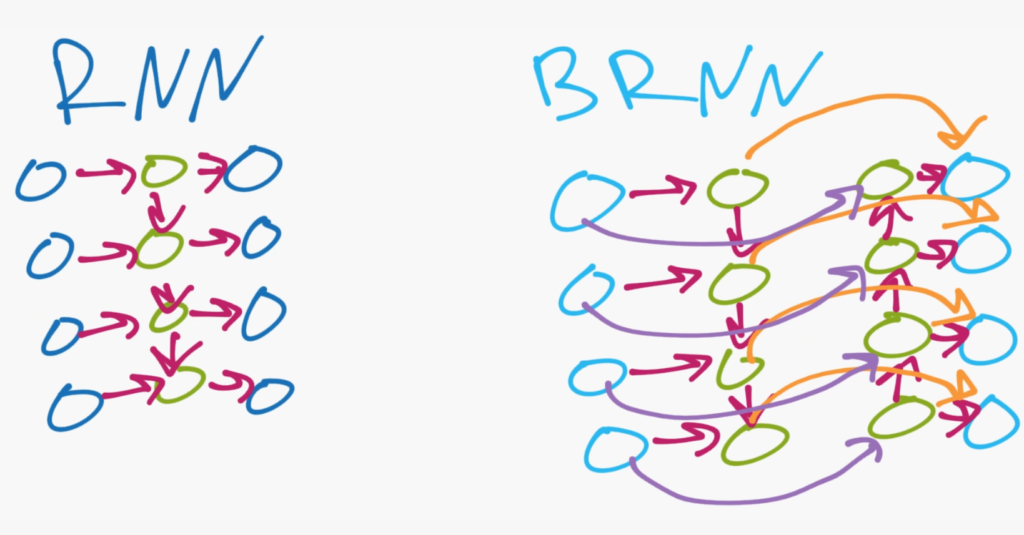
В простой RNN у нас есть входной, выходной и один скрытый слой. Таким образом, данные из входного слоя проходят в скрытый слой, где также потом поступают из верхних узлов слоя в нижние. Именно так мы получаем наши «переменные», а не статические характеристики из рекуррентных нейронных сетей, поскольку входные данные могут переноситься не только вперед к следующему слою, но и вниз по скрытому слою.
В BRNN, напротив, скрытый слой состоит из узлов, в которых данные могут передаваться в противоположенных направлениях. В отличии от обычной RNN скрытый слой передает данные как вверх, так и вниз (или вперед и назад, в зависимости от того, кто как рисует изображение). Это дает сети возможность обучаться на основании данных как из «прошлого», так и из «будущего».
Механизм внимания
Следующее дополнение к нашей сети — это механизм внимания, поскольку, несмотря на передачу данных вперед и назад, наша сеть не может запоминать более длинные последовательности (максимум 3-10 токенов за один раз). Если вы токенизируете слова, как это делаем мы, это означает максимум 3-10 слов за раз, но для моделей, где токенизируются символы (буквы, цифры и т.п.), это еще проблематичнее. В последнем случае можно запомнить только 3-10 букв или цифр. В такой модели ваш словарный запас будет еще меньше.
При помощи механизма внимания мы можем обрабатывать последовательности длиной в 30, 40 и даже более 80 токенов. Ниже приведены графики зависимости оценки качества перевода BLEU от длины последовательности токенов с включением механизма внимания и без него (красная кривая):
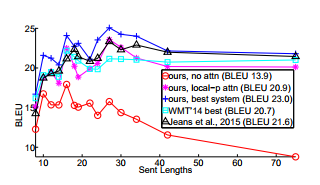
BLEU расшифровывается как «bilingual evaluation understudy». При помощи этой оценки можно определить эффективность алгоритма перевода с одного языка на другой, вероятно, наилучшим образом.
Однако важно заметить, что оценка BLUE зависит от вида тех последовательностей слов (то есть языков), которые мы переводим. Так, например, при переводе с английского на французский, мы, вероятно получим более высокий балл BLEU, чем при переводе с английского на японский или даже на немецкий. Или вообще на любой язык, где не всегда будет прямой перевод одного слова на другое.
В нашем случае мы преобразуем одну последовательность в другую, причем обе являются последовательностями на английском языке. Должны ли мы всегда получать высокую оценку BLEU? Ну, наверное, нет.
При языковых переводах часто существует одно точное или, по крайней мере, несколько идеальных вариантов для перевода (опять же, будут некоторые фразы, которые не переводятся идеально, но это не будет происходить часто). А вот существует ли некий «точный» ответ на какое-либо утверждение в случае разговорных данных? Точно нет. Мы надеемся, что BLEU будет медленно расти с течением времени, но не рассчитывайте увидеть оценку BLEU, аналогичную оценкам языкового перевода.
Механизм внимания не только помогает нам обрабатывать более длинные последовательностям, он также улучшает и работу с короткими фразами. Он вообще создает существенно большие возможности для обучения, чем необходимо для обучения простого чат-бота.
Изначально механизм внимания создавался для относительно простого перевода с английского на французский, однако структура такого языка как японский требует буквально гораздо большего «внимания». Иногда нужно посмотреть на конец японского предложения из 100 слов, чтобы правильно перевести первое слово на английский.
И с нашим чат-ботом мы сталкиваемся с такой же проблемой. Мы не производим дословный перевод различных частей предложения. Напротив, иногда именно конец входной последовательности будет определять ответ, то есть то, какой будет наша выходная последовательность. Возможно, далее мы еще глубже погрузимся в изучения механизма внимания, однако на данный момент этого вполне достаточно для общего представления о нем.
Помимо оценки BLEU есть еще одна важная характеристика качества перевода под названием perplexity (перплексия), часто сокращаемая как PPL. Это еще один отличный показатель качества модели. В отличие от оценки BLEU, здесь чем ниже PPL, тем лучше, поскольку это распределение вероятностей того, насколько эффективна наша модель при прогнозировании выходных данных из выборки.
Используя оценки BLEU и PPL при создании модели для перевода, вам, вероятно, надо продолжать обучение модели, пока BLEU растет, а PPL падает. В случае создания чат-бота мы не советуем такой прямой подход, так как это может привести к модели, которая будет давать откровенно роботизированные ответы. Способы борьбы с этой проблемой мы обсудим позже.
Мы надеемся, что это не первый ваш проект по машинному обучению и вам уже знакома такая важная характеристика как loss (потери). Фактически, эта характеристика показывает, насколько результат выходного слоя нейронной сети соответствуют правильным результатам в обучающих данных. Чем меньше потери, тем лучше.
И последнее, о чем мы хотим в этой статье рассказать — это Beam Search (поиск по лучу). Эту концепцию можно использовать для создания коллекции из нескольких лучших ответов (или переводов — в случае задач перевода), не выделяя сразу именно один.
Это приведет к увеличению времени обучения, но, на наш взгляд, это обязательное условие для создания качественного чат-бота. Дело в том, что тренировка только на единственных ответах может вызвать переобучение нашей модели. А разрешение нескольких ответов поможет в обучении и будет хорошо для дальнейшей работы данного бота.
Итак, в следующей статье мы с вами обсудим наше взаимодействие с созданным ботом.
Следующая статья — Чат-бот на Python (Deep Learning + TensorFlow). Часть IX: взаимодействие с нашим чатботом.
