
Сегодня мы начинаем серию учебных статей про глубокое обучение и Pytorch. Это значит, что в данной серии в качестве основного фреймворка по глубокому обучению будет использоваться Pytorch, хотя позже в этой серии мы напишем нейронную сеть с нуля.
Также, изучив досконально один фреймворк, вы сможете в дальнейшем свободно ориентироваться и в других библиотеках.
Что такое нейронные сети?
Мы предполагаем, что многие из вас стартуют с нуля и поэтому вкратце объясним, что такое нейронные сети. Мы уверены, что лучше всего получать знания, работая с технологией напрямую, но все же определенные базовые вещи полезно знать.
Нейронные сети по своей сути являются просто одним из алгоритмов машинного обучения.
Нейронные сети состоят из групп так называемых «нейронов», в которых хранятся определенные значения, начиная со входных данных. Затем они домножаются на веса, суммируются и проходят через функцию активации, производя новые значения. И этот процесс повторяется на каждом слое вашей нейронной сети, вплоть до получения результата.
Это выглядит как-то так:
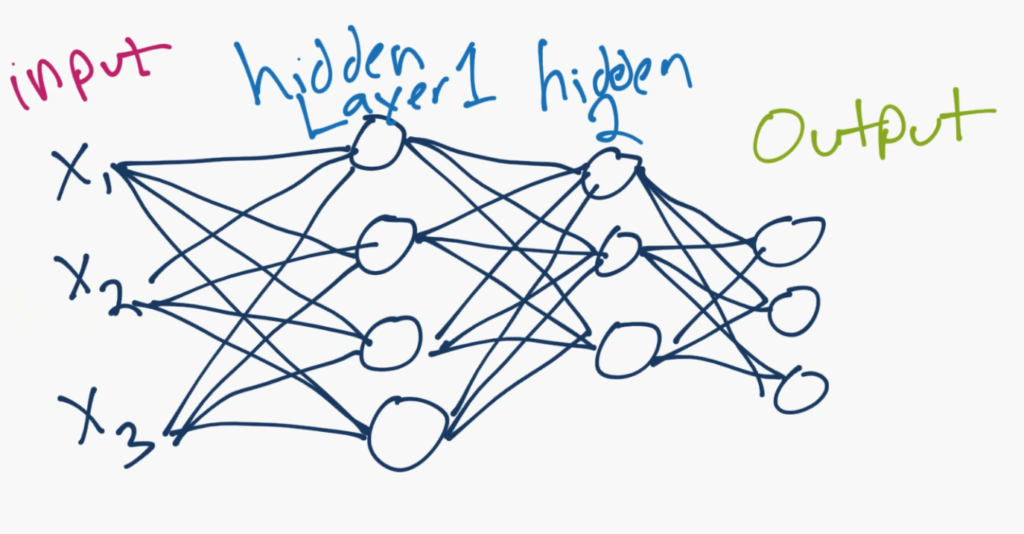
X1, X2, X3 — это характеристики ваших данных. Это могут быть, например значения пикселей изображения или какие-то другие числовые характеристики, описывающие ваши данные.
В скрытых слоях (скрытыми они назваются потому, что программист не контролирует значения, которые хранят нейроны в этих слоях) может находиться сколько угодно нейронов (то есть, программист не контролирует значения в этих нейронах, но не их количество!), а после них располагается выходной слой. Выходной слой может состоять как из одного нейрона (для задач регрессии), так и из нескольких (для задач классификации), в зависимости от того, сколько классов объектов есть в вашей задаче. В сети на картинке выходной слой состоит из трех нейронов, так что возможно данная сеть классифицирует например, собак, кошек и людей. Значение каждого из выходных нейронов может считаться показателем доверия принадлежности объекта данному классу.
У какого нейрона значение больше, к тому классу и относим объект предсказания! Представьте, что верхний нейрон нашей сети отвечает за класс «человек», средний за «собаку» и нижний за «кота». Если значение верхнего нейрона самое большое, значит нейронная сеть относит объект к классу «человек».
Все эти нейроны соединены линиями. У каждой линии есть вес и, опционально, смещение. Таким образом, входные значения умножаются на веса и к ним прибавлется смещение. Затем они все суммируются, проходят через функцию активации и становятся входными значениями для нейронов следующего слоя.
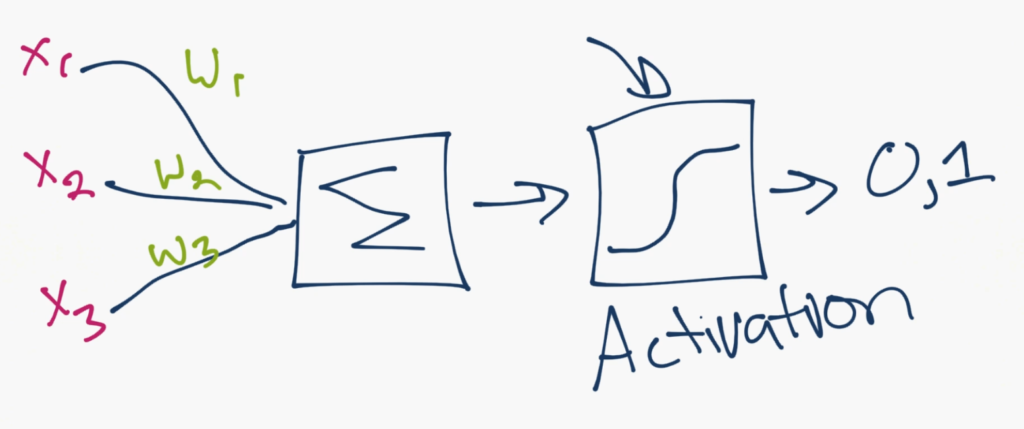
На рисунке выше показан механизм работы для одного нейрона из сети. Вы можете видеть входные значения (X), которые умножаются на веса (W), затем суммируются и проходят через функцию активации. Задача функции активации — вычислить, в какой степени данный нейрон работает, и работает ли он вообще. На выходе может быть значение 0 или 1, но как правило, оно варьируется между 0 и 1. И это значение является входным для следующего слоя.
Как нейронные сети обучаются?
На данный момент мы будем рассматривать только обучение с учителем, когда программист дает нейронной сети данные и затем сообщает правильный результат.
После этого машина должна сообразить, как ей надо преобразовать веса (каждая линия асссоциирована с определенным весом), чтобы результат классификации как можно ближе совпадал с теми данными, что ей дали. Это происходит не за один раз, конечно, а за миллионы и миллионы проходов, веса медленно подбираются, чтобы результат был все ближе и ближе к идеалу.
Отлично, теперь вы практически эксперты в этом деле! Давайте перейдем непосредственно к Pytorch. Но все же, если вас еще что-то смущает, то это абсолютно нормально. Почти все вопросы могут быть сняты практической работой с нейронными сетями.
Что вам потребуется для работы
- Python 3+. Здесь мы использовали Python 3.7.
- Pytorch. Здесь мы использовали версию 1.2.0.
- Понимание основ программирования на языке Python.
- Понимание концепции ООП.
По желанию, вы можете запускать все примеры на GPU вместо CPU.
Почему GPU?
Мы, как правило, предпочитаем работу на GPU, потому что, имея дело с тезорными библиотеками, мы производим огромное количество элементарных вычислений. Каждое ядро CPU способно произвести только одно вычисление за такт. С виртуальными ядрами это число удваивается, но CPU предназначен для выполнения гораздо более сложных задач. GPU был создан для обработки графики, где требуется также большое количество простых вычислений. Таким образом, ваш CPU способен осуществить от 8 до 24 вычислений за такт, а приличный GPU — буквально тысячи.
Для работы с нашим учебным кодом вы вполне сможете обойтись и CPU, почти любой процессор подойдет. Однако, для любой практической задачи глубокого обучения вам потребуется хороший GPU.
Облачные GPU
Есть ряд платформ, которые предоставляют GPU для вычислений на бесплатной основе. Однако, практически для любой реальной задачи вам все равно придется апгрейдить ваш аккаунт и вы, скорей всего, будете платить выше рынка. Эту проблему не обойти, все равно на каком-то этапе вам потребуется GPU — либо локально, либо в облаке.
На данный момент лучшим вариантом по набору предлагаемых опций будет Linode.com.
Но $1.5 за час могут показаться слишком дорогим удовольствием. К тому же, для ряда задач такая вычислительная мощность избыточна. На второе место мы поставим Paperspace, который предлагает более дешевые GPU. Также он очень прост в установке. Здесь вы получите GPU за $0.5 в час и деньги будут сниматься только при работе сервера.
Собственные GPU
Если у вас Linux и вы хотите использовать свой сосбтвенный GPU, вот отличное пособие как это сделать.
Если у вас Windows, вас нужно просто установить Cuda Toolkit 10.0. Затем загрузите CuDNN for Cuda Toolkit 10.0 (на этом этапе вам, возможно, придется создать аккаунт для входа).
Установите Cuda Toolkit, а затем распакуйте файлы CuDNN. Там будут директории bin, include и lib. Вам всего лишь нужно перенести их в место расположения Cuda Toolkit. Скорей всего, он будет находиться здесь: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0. И там тоже будут директории bin, include и lib.
Что такое Pytorch?
Библиотека Pytorch, как и все другие билиотеки глубокого обучения, в действительности всего лишь производит операции с тензорами.
Что такое тензоры?
Вы можете считать тензоры просто массивами. Реально, все что мы тут делаем, это просто перемножаем массивы друг с другом. Больше ничего тут нет. Немного магии есть в том, что когда мы запускаем алгоритм оптимизации, веса начинают меняться. Нейронные сети, сами по себе, очень просты. Их оптимизация несколько сложнее, но большинство библиотек глубокого обучения помогут вам и с этой математикой. Если же вы хотите узнать, как сделать все самостоятельно, ждите следующих серий. Мы считаем, что с этого начинать неправильно.
Итак, давайте пощупаем, что такое тензоры:
import torch x = torch.Tensor([5,3]) y = torch.Tensor([2,1]) print(x*y)
Результат:
tensor([10., 3.])
Вау, это просто [5*2, 3*1]. Нехитрая штука!
Ввиду большого количества операций с массивами, Pytorch старается копировать другую очень популярную библиотеку Python под названием NumPy. Существует большое количество совершенно одинаковых методов, как правило они носят одно и то же название, но иногда разнятся. Одна из типичных задач это создание пустого массива определенной формы. В NumPy мы используем метод np.zeros. В Pytorch то же самое:
x = torch.zeros([2,5]) print(x)
Результат:
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
print(x.shape)
Результат:
torch.Size([2, 5])
Если нам нужно сгенерировать массив определенной формы со случайными значеними:
y = torch.rand([2,5]) print(y)
Результат:
tensor([[0.2632, 0.9136, 0.5702, 0.9915, 0.4885],
[0.5025, 0.7631, 0.5265, 0.4594, 0.1881]])
И, кстати, мы сейчас с данными примерами не тратим впустую ваше время: все эти методы и многие другие нам пригодятся в дальнейшем.
И напоследок, как насчет метода reshape для изменения размеров массива? Оказывается, в Pytorch решили придумать для него совершенно новое, нигде больше не используемое название — .view().
Для людей, знакомых с NumPy или другими библиотеками машинного обучения, это может показаться несколько глупым. Но зато данное название очень легко запоминается.
Итак, выше у нас есть тензор, состоящий из двух тензоров по пять элементов в каждом. Мы хотим получить один тензор из десяти элементов. Для этого мы используем метод .view().
y.view([1,10])
Результат:
tensor([[0.2632, 0.9136, 0.5702, 0.9915, 0.4885, 0.5025, 0.7631, 0.5265, 0.4594,
0.1881]])
Мы здесь абсолютно не должны быть против такого имени. Мы действительно, в буквальном смысле, «видим» (view) наш тензор в таком виде, 1Х10. А сам тензор не был изменен:
y
Результат:
tensor([[0.2632, 0.9136, 0.5702, 0.9915, 0.4885],
[0.5025, 0.7631, 0.5265, 0.4594, 0.1881]])
Разумеется, мы можем и переопределить его таким образом навсегда:
y = y.view([1,10]) y
Результат:
tensor([[0.2632, 0.9136, 0.5702, 0.9915, 0.4885, 0.5025, 0.7631, 0.5265, 0.4594,
0.1881]])
Итак, на этом мы завершаем очень краткое введение в нейронные сети и Pytorch. В следующей части мы будет обсуждать то, что вначале входит в нашу нейронную сеть, а именно данные.
Данные — это то немногое, что мы можем контролировать при работе с нейронными сетями. А именно — управлять их форматом и структурой.
Сначала нам нужно добыть сами данные, затем решить, каким образом преобразовать их в численные величины, далее разобраться с их масштабированием, и после этого придумать, как эти данные преподнести нейронной сети.
Следующая статья — Глубокое обучение и нейронные сети с Python и Pytorch, данные. Часть II.
