
DDoS-атака — один из самых мощных методов взлома в интернете. Для уничтожения или разрушения сайтов используется сетевой трафик. Существуют различные подкатегории такой атаки, отличающиеся способами, которыми хакер пытается проникнуть в сеть. В данной статье мы обсудим подход к обнаружению угрозы DDoS-атаки при помощи модели искусственного интеллекта, точность которой составляет 96%. Мы классифицировали 7 различных подкатегорий угроз DDoS, а также безопасную или надежную сеть.
Введение
DDos-атаки нацелены на сайты и онлайн-сервисы. Смысл такой атаки — заблокировать сеть или сервер чрезмерным трафиком. Эффективность достигается за счет использования нескольких скомпрометированных систем в качестве источников атакующего трафика.
DDoS-атаки делятся на различные подкатегории в зависимости от уровня сетевого подключения, которое они пытаются атаковать (имеется в виду уровень по модели OSI). В ходе нашего исследования мы классифицировали следующие подкатегории: SYN Flood, UDP Flood, MSSQL, LDAP, Portmap, NetBIOS.
Машинное и глубокое обучение в наши дни является основой искусственного интеллекта. Мы используем эти методологии для решения проблем в различных областях с точностью, близкой к человеческой. В данном исследовании мы в очередной раз проверили пределы искусственного интеллекта в обнаружении угроз в области кибербезопасности.
Предподготовка данных
Подготовка данных была одной из первых проблем, с которыми мы столкнулись. У данных было 88 атрибутов или, иначе говоря, свойств. Обработка таких огромных массивов данных в ограниченной оперативной памяти была для нас действительно непростой задачей. Поэтому мы понизили тип данных атрибутов и, следовательно, уменьшили расход памяти. Типы данных float64 понижены до float32, int64 — до int32, int32 — до uint32 и так далее. Таким образом удалось сэкономить почти 42% памяти. Но в нашем датафрейме все еще оставались атрибуты с очень большими значениями и их также пришлось обработать на предварительном этапе.
def Pre_process_data(df,col):
'''
Input: Data-frame and Column name.
Operation: Fills the nan values with the minimum value in their respective column.
Output: Returns the pre-processed data-frame.
'''
#df['primary_use'] = df['primary_use'].astype("category").cat.codes
print("Name of column with NaN: "+str(col))
print(df[col].value_counts(dropna=False, normalize=True).head())
df[col].replace(np.inf, -1, inplace=True)
return df
def reduce_mem_usage(df):
'''
Input - data-frame.
Operation - Reduce memory usage of the data-frame.
'''
start_mem_usg = df.memory_usage().sum() / 1024**2
print("Memory usage of properties dataframe is :",start_mem_usg," MB")
#NAlist = [] # Keeps track of columns that have missing values filled in.
for col in df.columns:
if df[col].dtype != object: # Exclude strings
# Print current column type
print("******************************")
print("Column: ",col)
print("dtype before: ",df[col].dtype)
# make variables for Int, max and min
IsInt = False
mx = df[col].max()
mn = df[col].min()
#print("min for this col: ",mn)
#print("max for this col: ",mx)
# Integer does not support NA, therefore, NA needs to be filled
if not np.isfinite(df[col]).all():
#NAlist.append(col)
df = Pre_process_data(df,col)
# test if column can be converted to an integer
asint = df[col].fillna(0).astype(np.int64)
result = (df[col] - asint)
result = result.sum()
if result > -0.01 and result < 0.01:
IsInt = True
# Make Integer/unsigned Integer datatypes
if IsInt:
if mn >= 0:
if mx < 255:
df[col] = df[col].astype(np.uint8)
elif mx < 65535:
df[col] = df[col].astype(np.uint16)
elif mx < 4294967295:
df[col] = df[col].astype(np.uint32)
else:
df[col] = df[col].astype(np.uint64)
else:
if mn > np.iinfo(np.int8).min and mx < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif mn > np.iinfo(np.int16).min and mx < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif mn > np.iinfo(np.int32).min and mx < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif mn > np.iinfo(np.int64).min and mx < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
# Make float datatypes 32 bit
else:
df[col] = df[col].astype(np.float32)
# Print new column type
print("dtype after: ",df[col].dtype)
print("******************************")
# Print final result
print("___MEMORY USAGE AFTER COMPLETION:___")
mem_usg = df.memory_usage().sum() / 1024**2
print("Memory usage is: ",mem_usg," MB")
print("This is ",100*mem_usg/start_mem_usg,"% of the initial size")
return df
Распределение целевых переменных
labels = 'UDPLag', 'Syn', 'UDP', 'NetBIOS','Portmap','MSSQL','BENIGN'
sizes = [len(data_[data_[' Label']=='UDPLag']), len(data_[data_[' Label']=='Syn']),
len(data_[data_[' Label']=='UDP']), len(data_[data_[' Label']=='NetBIOS']),
len(data_[data_[' Label']=='Portmap']),len(data_[data_[' Label']=='MSSQL']),
len(data_[data_[' Label']=='BENIGN'])]
colors = ['gold', 'yellowgreen', 'lightcoral', 'lightskyblue','yellow','purple','grey']
explode = (0, 0.1, 0, 0,0,0,0) # explode 1st slice
# Plot
plt.rcParams.update({'font.size': 22})
plt.figure(figsize=(10,10))
plt.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', shadow=True, startangle=140)
plt.axis('equal')
plt.show()
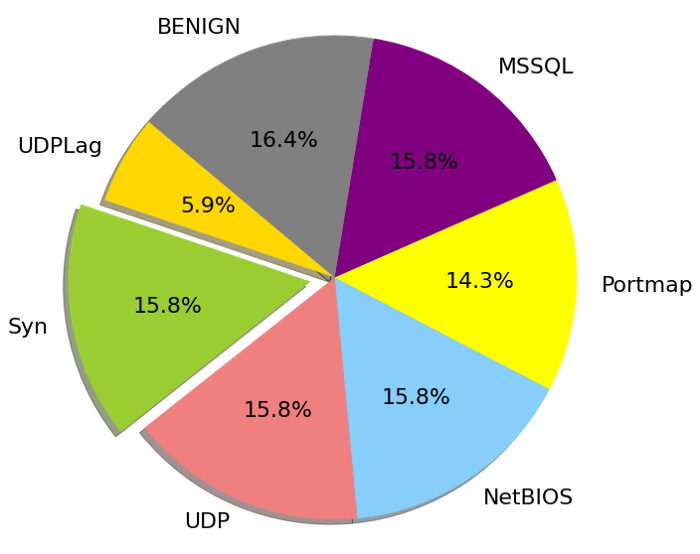
Как видите, мы попытались сохранить равномерное распределение целевых переменных относительно друг друга.
Так как UDPLag несколько выбивается из этой картины, мы рассмотрим эту переменную отдельно.
Исследовательский анализ данных
plt.figure(figsize=(20,16))
g1 = sns.countplot(x=' Label', hue=' Label', data=data_)
gt = g1.twinx()
gt = sns.pointplot(y=' Flow Packets/s', x=' Label', data=data_, color='black', legend=False)
gt.set_ylabel(" Flow Packets/s", fontsize=16)
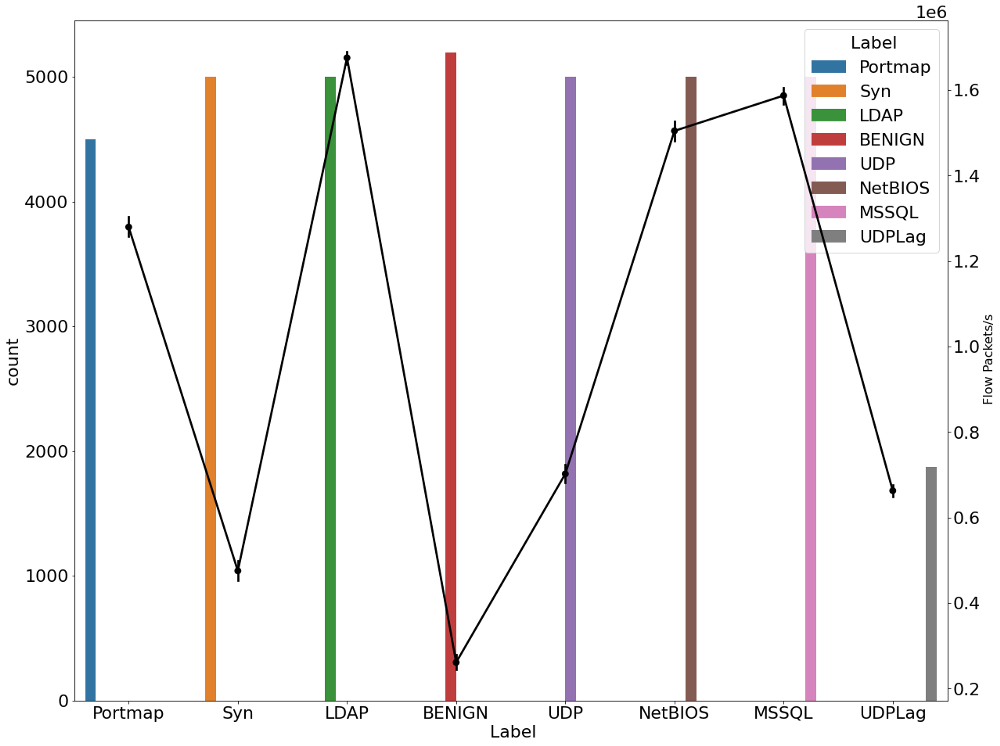
plt.figure(figsize=(20,16))
g1 = sns.countplot(x=' Label', hue=' Label', data=data_)
gt = g1.twinx()
gt = sns.pointplot(y='Flow Bytes/s', x=' Label', data=data_, color='black', legend=False)
gt.set_ylabel("Flow Bytes/s", fontsize=16)
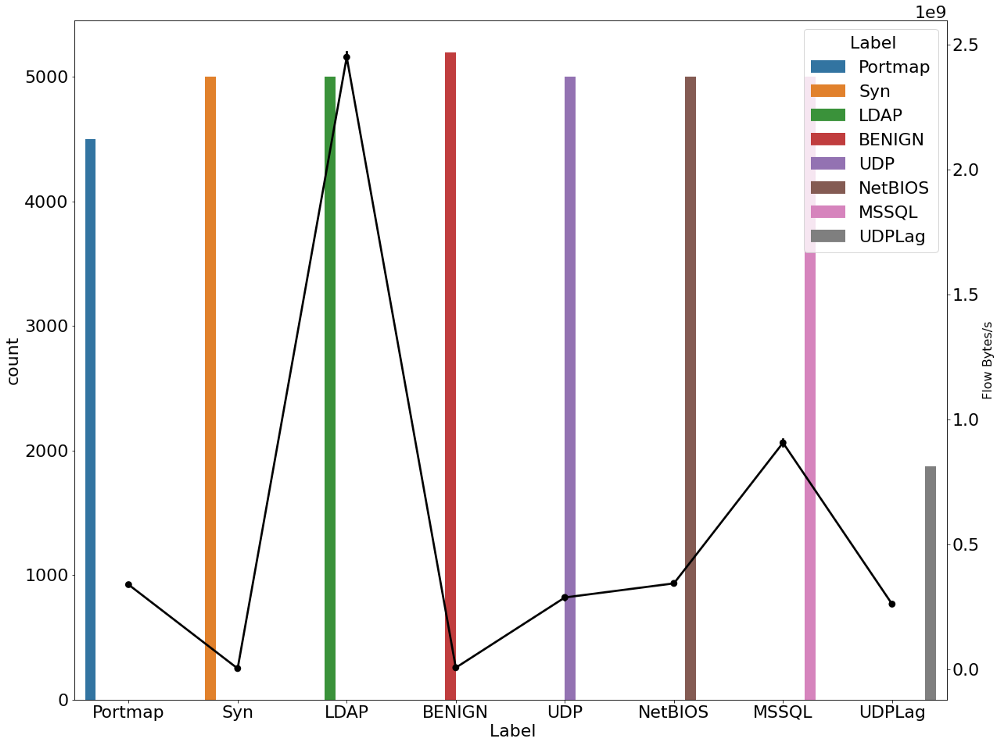
В двух приведенных выше графиках мы можем ясно заметить, что существует дрейф в потоке битов и потоке пакетов во время DDoS-атаки по сравнению с безопасным соединением.
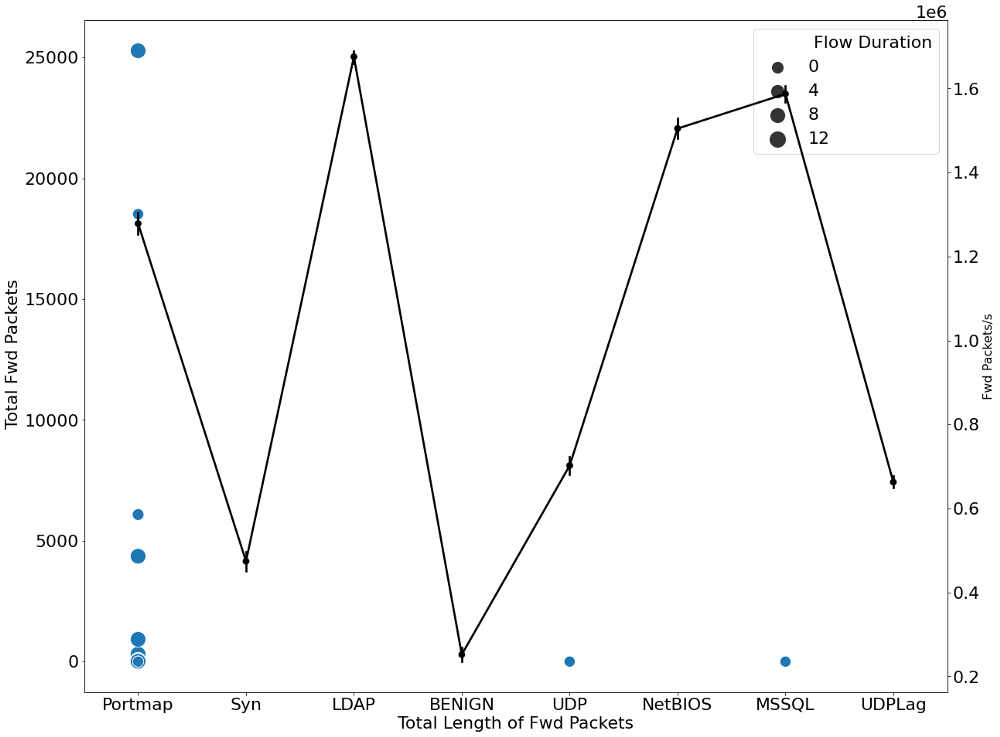
plt.figure(figsize=(20,16))
g1 = sns.scatterplot(y=' Total Fwd Packets', x='Total Length of Fwd Packets',
sizes=(200, 400), size=' Flow Duration',data=data_)
gt = g1.twinx()
t = sns.pointplot(y='Fwd Packets/s', x=' Label', data=data_, color='black', legend=False)
gt.set_ylabel("Fwd Packets/s", fontsize=16)
plt.figure(figsize=(20,16))
g1 = sns.scatterplot(y=' Total Backward Packets', x=' Total Length of Bwd Packets',
sizes=(200, 400), size=' Flow Duration',data=data_)
gt = g1.twinx()
t = sns.pointplot(y=' Bwd Packets/s', x=' Label', data=data_, color='black', legend=False)
gt.set_ylabel("Bwd Packets/s", fontsize=16)
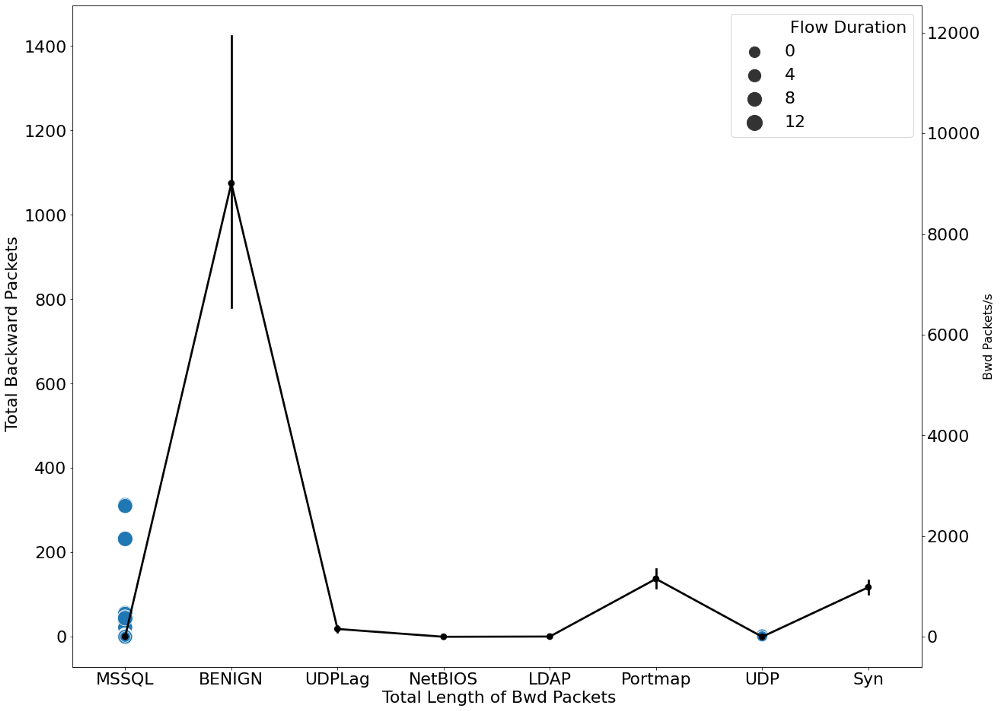
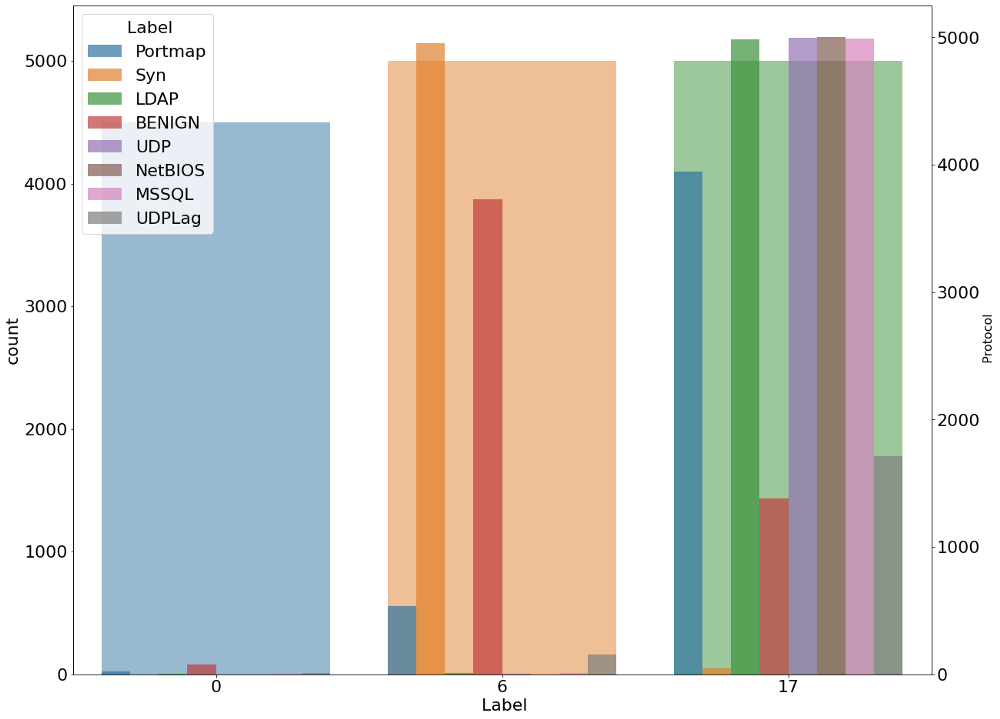
Мы также проанализировали распределение угроз всех видов внутри каждого типа протокола и входящих угроз. Ниже приведены диаграммы, отображающие этот анализ.
plt.figure(figsize=(20,16))
g1 = sns.countplot(x=' Label', data=data_,alpha=0.5)
gt = g1.twinx()
gt = sns.countplot(x=' Protocol', hue=' Label',alpha=0.7, data=data_)
gt.set_ylabel(" Protocol", fontsize=16)
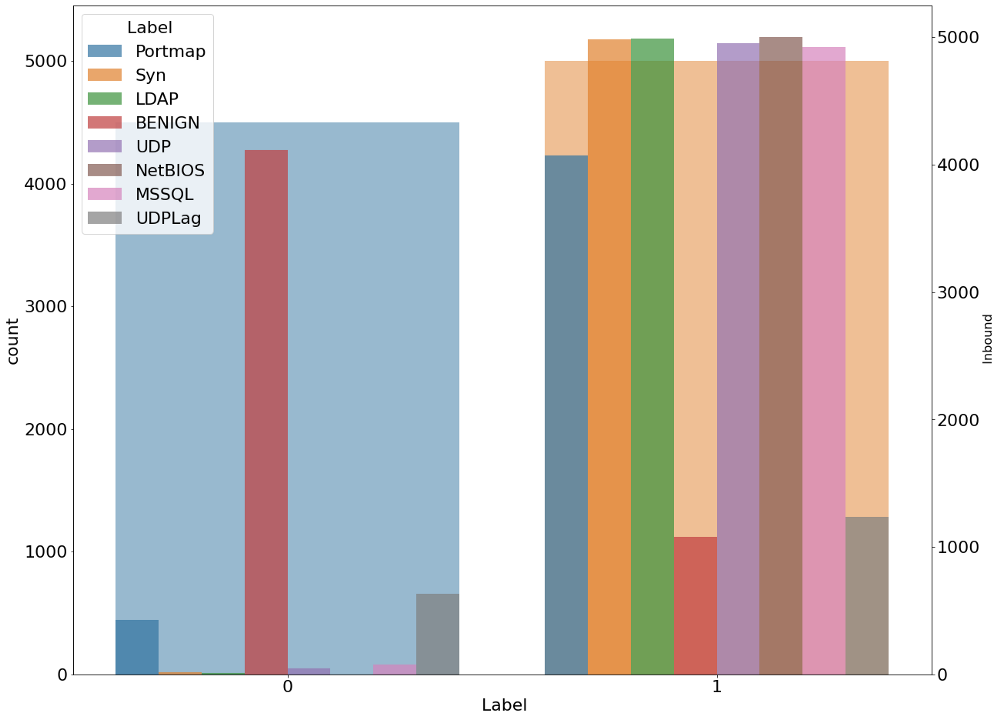
plt.figure(figsize=(20,16))
g1 = sns.countplot(x=' Label', data=data_,alpha=0.5)
gt = g1.twinx()
gt = sns.countplot(x=' Inbound', hue=' Label',alpha=0.7, data=data_)
gt.set_ylabel(' Inbound', fontsize=16)
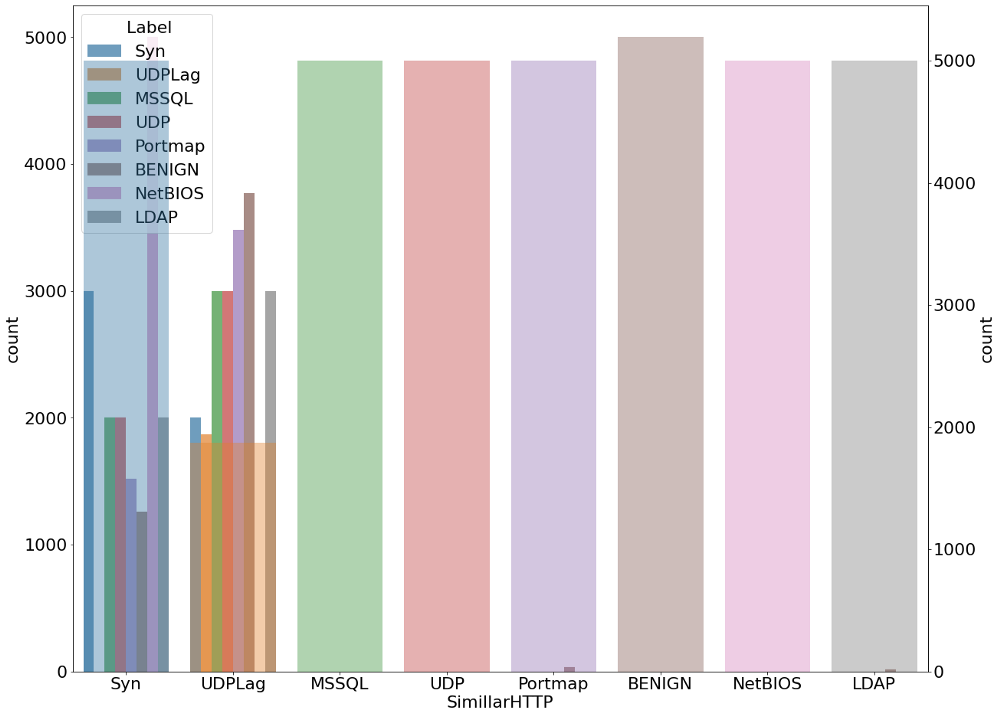
plt.figure(figsize=(20,16)) g1 = sns.countplot(x='SimillarHTTP', hue=' Label',alpha=0.7, data=data_) gt = g1.twinx() gt = sns.countplot(x=' Label', data=data_,alpha=0.4)
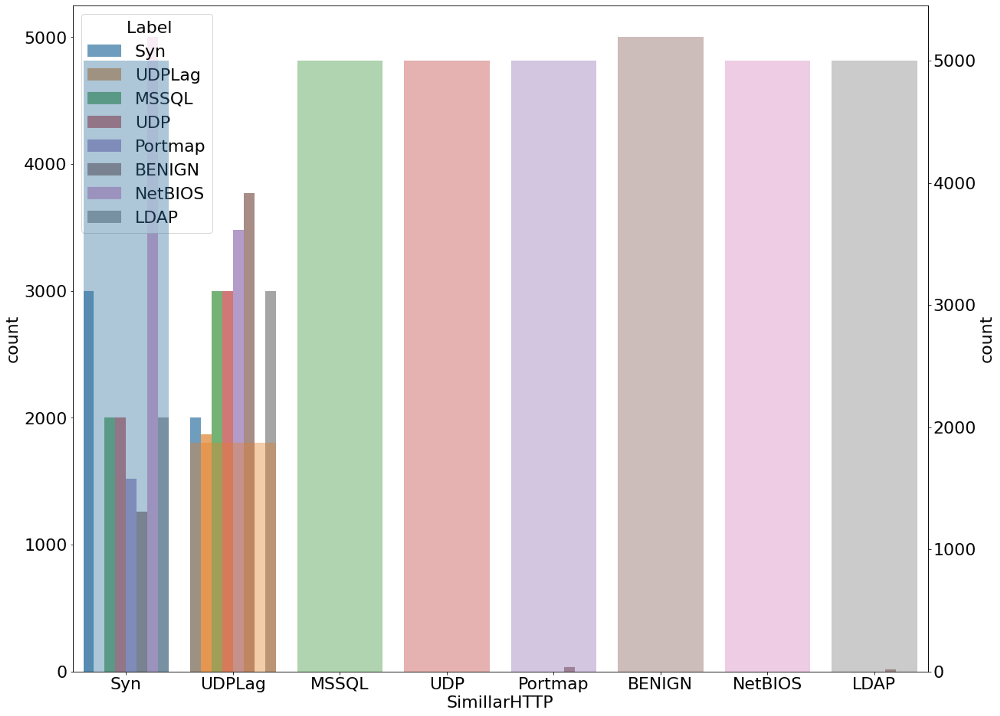
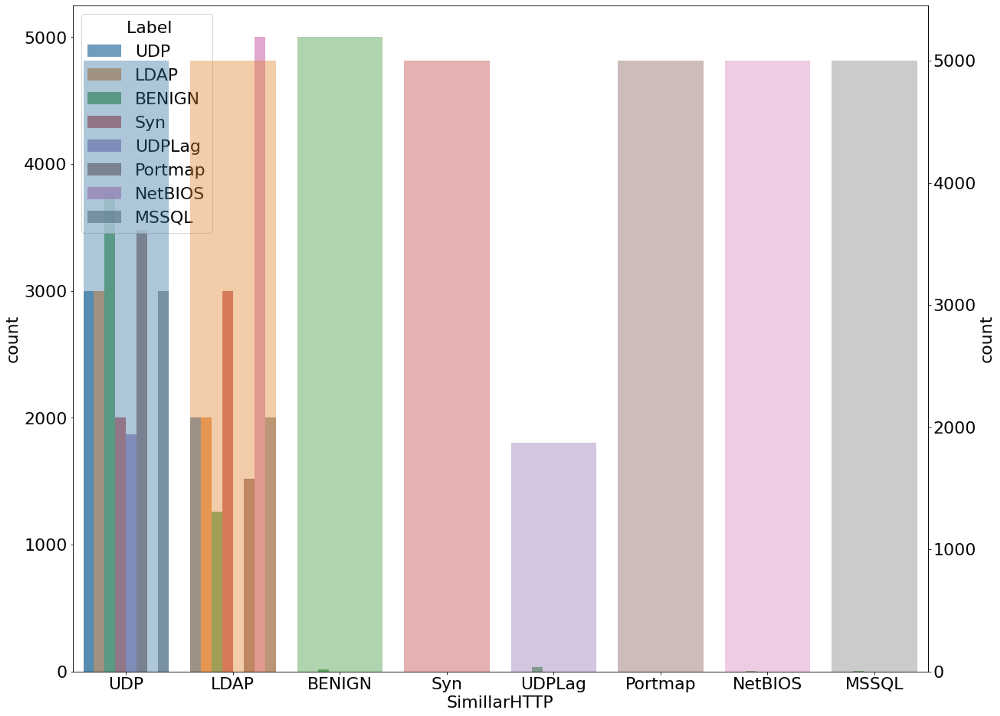
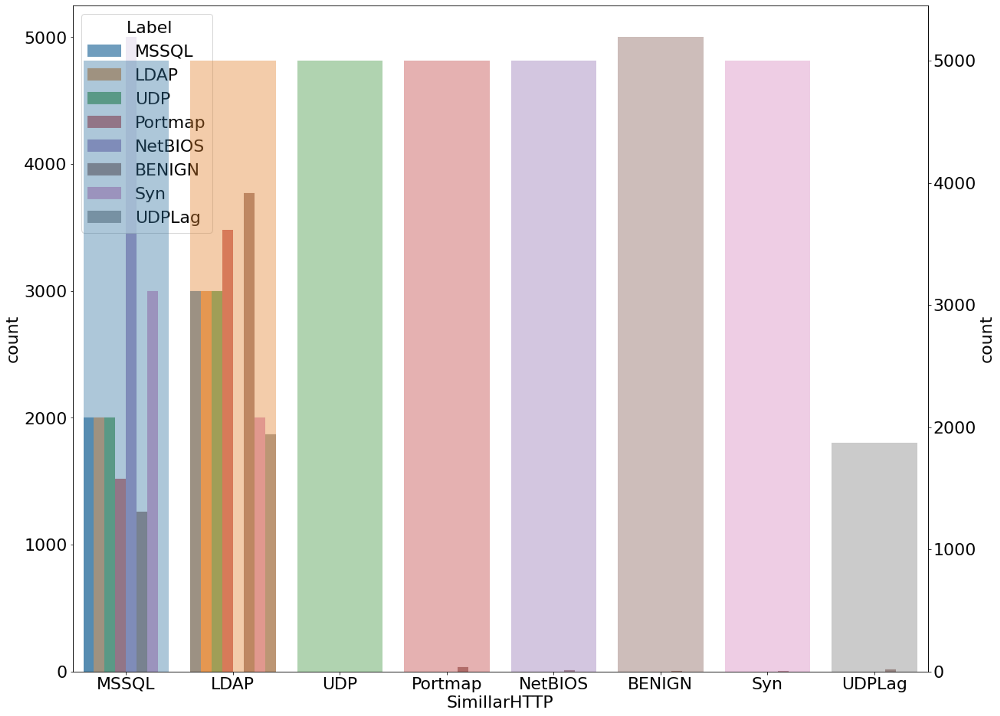
Обнаружение угрозы при помощи обучения без учителя
При обучении без учителя у нас нет целевых переменных, мы учимся непосредственно на входных данных, самостоятельно обнаруживая в них информацию и закономерности.
Преподготовка данных перед обучением. Мы удалили из наших данных столбцы Flow ID, Source IP, Source Port, Destination IP, Destination Port, Timestamp, Flow Packets / s, Flow Bytes / s ‘. «Flow plackets / s» и «Flow Bytes / s» были удалены потому, что даже после стандартного масштабирования значения этих переменных были бы слишком велики или, наоборот, очень малы.
scale = preprocessing.StandardScaler() X = scale.fit_transform(X) X_norm = preprocessing.normalize(X)
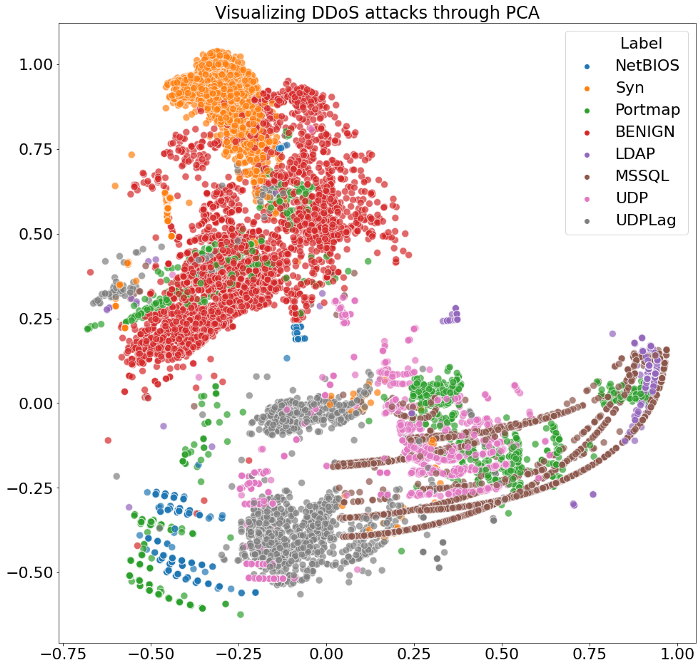
Мы отмасштабировали наши данные при помощи стандартной функции масштабирования с последующей их нормализацией. Для уменьшения размерности был использован метод главных компонент.
pca = PCA(n_components=2)
principalComponents = pca.fit_transform(X_norm)
plt.figure(figsize=(16,16))
g1 = sns.scatterplot(principalComponents[:, 0], principalComponents[:, 1], s= 100, hue=data_[' Label'], cmap='Spectral',alpha=0.7)
plt.title('Visualizing DDoS attacks through PCA', fontsize=24);
pca_ = PCA(n_components=2)
principalComponents = pca_.fit_transform(X_norm)
tsne_ = TSNE(random_state = 42, n_components=2,verbose=0, perplexity=40, n_iter=600).fit_transform(principalComponents)
plt.figure(figsize=(16,16))
g1 = sns.scatterplot(tsne_[:, 0], tsne_[:, 1], s= 100, hue=data_[' Label'], cmap='Spectral',alpha=0.7)
plt.title('Visualizing DDoS attacks through t-SNE', fontsize=24);
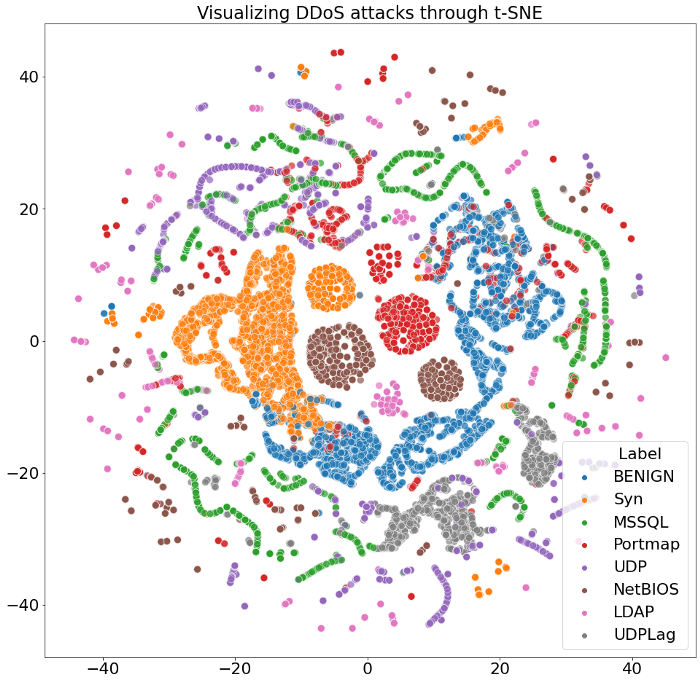
Итак, из двух вышеупомянутых визуализаций можно ясно увидеть, что наш алгоритм умеет в некоторой степени успешно выделять различные угрозы из данных.
Давайте посмотрим, как наша модель обучения без учителя может маркировать сгенерированные кластеры.
Agglo = AgglomerativeClustering(n_clusters=8)
Agglo.fit(principalComponents)
plt.figure(figsize=(20,11))
plt.scatter(tsne_[:, 0],tsne_[:, 1], c=Agglo.labels_,edgecolors='black')
plt.gca().set_aspect('equal', 'datalim')
plt.colorbar(boundaries=np.arange(11)-0.5).set_ticks(np.arange(8))
plt.title('Visualizing DDoS attacks after Agglomerative Clustering', fontsize=24);
plt.show()
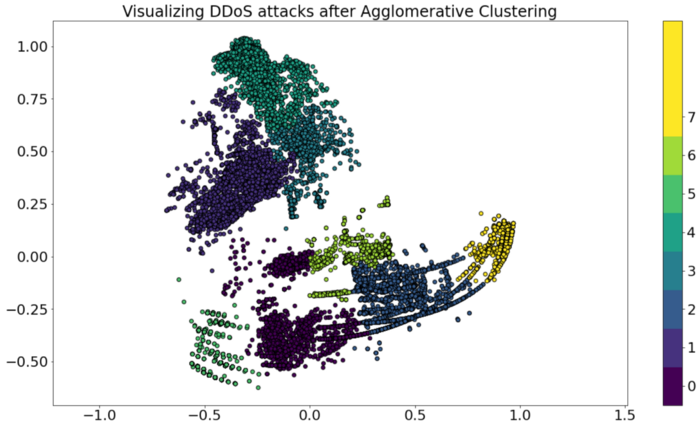
Что ж, похоже, наша модель обучения без учителя успешно нашла закономерности в данных и смогла до некоторой степени самостоятельно сегментировать нашу целевую переменную.
Замечание: Обучение без учителя дает вам подробное и проанализированное представление о форме и структуре данных. Кластеризация при обучении без учителя и прогнозирование целевой метки на основе данных будут меняться при изменении формы и структуры данных, поскольку целевые данные могут быть неизвестны. Насколько они точны, определить невозможно, а это делает машинное обучение с учителем более применимым к реальным проблемам. Это также одна из причин, почему обученные посредством обучения без учителя модели не подходят для развертывания в производственной среде.
Обучение с учителем для обнаружения угроз
Это прямо противоположно подходу с обучением без учителя. Здесь мы позволяем нашей модели учиться через целевую переменную. Это дает нашей модели дополнительную возможность извлекать закономерности из размеченных данных. Мы применяем ту же предварительную обработку данных, что и для моделей обучения без учителя. В данном случаем мы используем для обучения нашей модели методы глубокого обучения.
Структура нашей модели глубокого обучения
K.clear_session()
def create_model():
Input_ = tf.keras.Input(shape=(84,))
model = tf.keras.layers.Dense(128, activation=tf.nn.relu)(Input_)
model = tf.keras.layers.Dropout(0.4)(model)
model = tf.keras.layers.BatchNormalization()(model)
model = tf.keras.layers.Dense(64, activation=tf.nn.relu)(model)
model = tf.keras.layers.Dropout(0.4)(model)
model = tf.keras.layers.BatchNormalization()(model)
model = tf.keras.layers.Dense(8, activation=tf.nn.softmax)(model)
return tf.keras.Model(inputs=Input_, outputs=model)
Так как наша целевая переменная несбалансированна, мы используем метод K-Fold для обучения и кроссвалидации наших данных из каждой выборки. Он балансирует обучение и валидацию для нашей несбалансированной переменной.
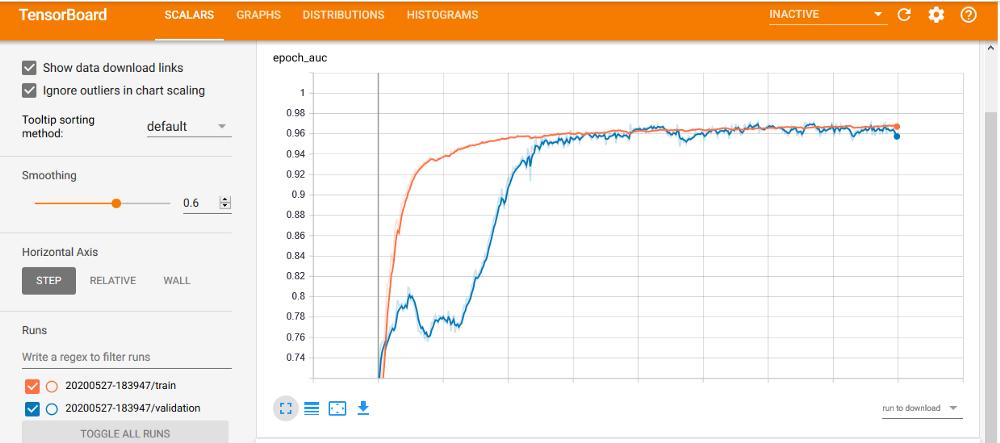
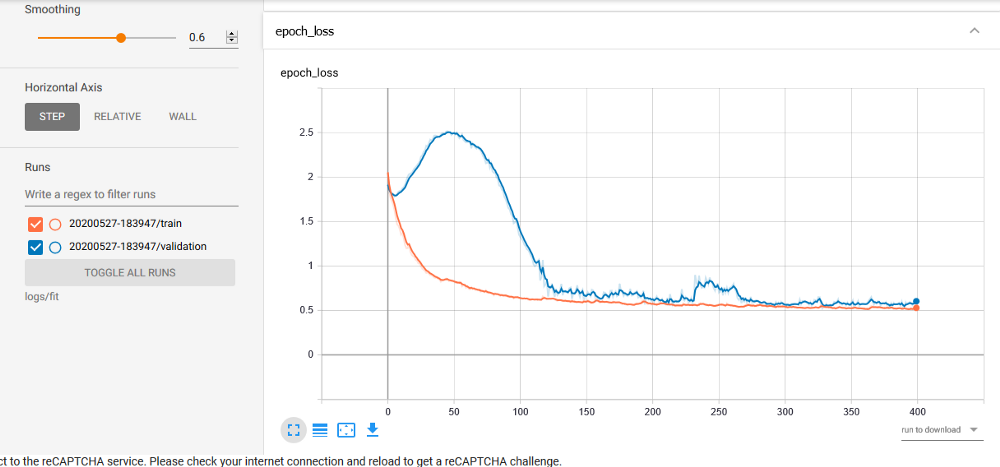
В качестве оптимайзера мы используем Adam, а в качестве метрики оценки качества — ROC_AUC. В данной метрике вычисляется площадь под кривой ошибок.
Мы обучили и проверили нашу модель на более чем 10 выборках. При этом мы достигли показателя ROC_AUC 96% и более по сравнению со средним значением для обнаружения угроз и достигли наивысшей точности 97% и более.
def auc(y_true, y_pred):
def fallback_auc(y_true, y_pred):
return metrics.roc_auc_score(y_true, y_pred)
return tf.py_function(fallback_auc, (y_true, y_pred), tf.double)
oof_preds = np.zeros((len(X_)))
acc_ = []
i=0
skf = StratifiedKFold(n_splits=10)
for train_index, test_index in skf.split(X_, y_):
i=i+1
X_train, X_test = X_.iloc[train_index, :], X_.iloc[test_index, :]
X_train = X_train.reset_index(drop=True)
X_test = X_test.reset_index(drop=True)
y_train, y_test = y_.iloc[train_index], y_.iloc[test_index]
y_train = y_train.reset_index(drop=True)
y_test = y_test.reset_index(drop=True)
model = create_model()
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=[auc])
if i%3 == 0:
model.fit(x=X_train,
y=utils.to_categorical(y_train),
epochs=400,
batch_size=1024,
verbose=0,
validation_data=(X_test, utils.to_categorical(y_test)),
callbacks=[tensorboard_callback],
)
else:
model.fit(x=X_train,
y=utils.to_categorical(y_train),
epochs=400,
batch_size=1024,
verbose=0,
validation_data=(X_test, utils.to_categorical(y_test)),
)
valid_fold_preds = model.predict(X_test)
#print(valid_fold_preds.shape,y_test.shape)
print("ROC accuracy: ")
#oof_preds[test_index] = valid_fold_preds.ravel()
acc = metrics.roc_auc_score(utils.to_categorical(y_test), valid_fold_preds,multi_class="ovr")
acc_.append(acc)
print(acc)
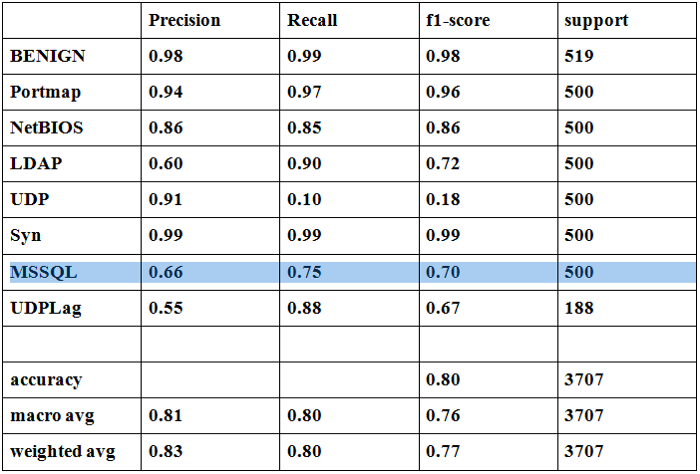
print(classification_report(y_test, np.argmax(valid_fold_preds,axis=1)))
cm = confusion_matrix(y_test, np.argmax(valid_fold_preds,axis=1))
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
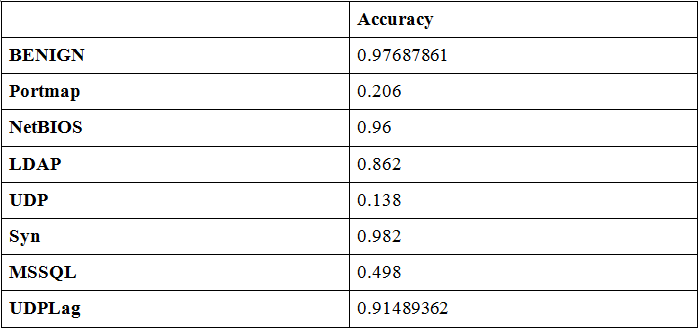
print(cm.diagonal())
K.clear_session()
Отчет о классификации в одной из 10 выборок
Точность определения каждого класса в одной из 10 выборок
Выводы
Даже если у вас недостаточно размеченных данных и их намного меньше, чем неразмеченных, существуют методы машинного обучения с частичным привлечением учителя, которые позволяют получить отличные результаты.
В библиотеке TensorFlow есть индикаторы справедливости, с помощью которых можно оценить точность и производительность моделей машинного обучения.
Используемые инструменты и наборы данных
Данные были предоставлены Университетом Нью-Брансуика.
Для проведения исследований использовались библиотеки TensorFlow, Scikit Learn, Matplotlib, Seaborn.
