
Веб-парсинг на Python – это гораздо больше, чем просто извлечение контента с помощью селекторов CSS. Благодаря приемам и идеям из этой статьи вы сможете более надежно, быстро и эффективно собирать данные.
Начинаем
Сперва установите все необходимые библиотеки, запустив pip install.
pip install requests beautifulsoup4 pandas
Получить HTML-код из URL-адреса мы можем при помощи библиотеки requests. Затем контент передается в BeautifulSoup, после чего можно начать получать данные и делать запросы с помощью селекторов. В детали вдаваться мы не будем, лишь скажем, что селекторы CSS используются для получения отдельных элементов и содержимого страницы. Синтаксис при этом бывает разный, но это мы рассмотрим позже.
import requests
from bs4 import BeautifulSoup
response = requests.get("https://zenrows.com")
soup = BeautifulSoup(response.content, 'html.parser')
print(soup.title.string)
Чтобы не запрашивать HTML каждый раз, мы можем сохранить его в HTML-файле и уже оттуда загружать BeautifulSoup. Чисто для демонстрации давайте сделаем это вручную. Самый простой способ – это просмотреть исходный код страницы, скопировать и вставить его в файл. Важно посетить страницу без входа в систему, как это сделал бы поисковый робот.
Получение HTML-кода может показаться простой задачей, но это далеко не так. Вообще эта тема тянет на отдельную полноценную статью, так что здесь мы затронем ее лишь вскользь. Мы советуем использовать статический подход из примера ниже, поскольку многие сайты после нескольких запросов начнут перенаправлять вас на страницу входа. Некоторые покажут капчу, и в худшем случае ваш IP будет забанен.
with open("test.html") as fp:
soup = BeautifulSoup(fp, "html.parser")
print(soup.title.string) # Web Data Automation Made Easy - ZenRows
После статической загрузки из файла мы сможем делать сколько угодно попыток запросов, не имея проблем проблем с сетью и не опасаясь блокировки.
Изучите сайт перед тем, как начать писать код
Прежде чем начать писать программу, нужно понять содержание и структуру страницы. Это можно сделать довольно просто при помощи браузера. Мы будем использовать DevTools Chrome, но в других браузерах есть аналогичные инструменты.
Например, мы можем открыть любую страницу продукта на Amazon. Беглый просмотр покажет нам название продукта, цену, доступность и многие другие поля. Перед копированием всех этих селекторов мы рекомендуем потратить пару минут на поиск скрытых входных данных, метаданных и сетевых запросов.
Пользуясь Chrome DevTools или аналогичными инструментами, проявляйте осторожность. Контент, который вы увидите, возможно, был изменен в результате работы JavaScript и сетевых запросов. Да, это утомительно, но иногда нужно исследовать исходный HTML, чтобы избежать запуска JavaScript.
Дисклеймер: мы не будем включать URL-запрос в фрагменты кода для каждого примера. Все они похожи на первый. И помните: сохраняйте HTML-файл локально, если собираетесь протестировать его несколько раз.
Скрытые инпуты
Скрытые инпуты позволяют разработчикам включать поля ввода, которые конечные пользователи не могут видеть или изменять. Многие формы используют их для включения внутренних идентификаторов или токенов безопасности.
В продуктах Amazon мы видим, что их довольно много. Некоторые из них будут доступны в других местах или форматах, но иногда они уникальны. В любом случае имена скрытых инпутов обычно более стабильны, чем имена классов.

Метаданные
Хотя некоторый контент отображается через пользовательский интерфейс, его может быть проще извлечь с помощью метаданных. Например, можно получить количество просмотров в числовом формате и дату публикации в формате ГГГГ-ММ-ДД для видео на YouTube. Да, эти данные можно увидеть на сайте, но их можно получить и с помощью всего пары строк кода. Несколько минут на написание кода точно окупятся.
interactionCount = soup.find('meta', itemprop="interactionCount")
print(interactionCount['content']) # 8566042
datePublished = soup.find('meta', itemprop="datePublished")
print(datePublished['content']) # 2014-01-09
XHR-запросы
Некоторые сайты загружают пустой шаблон и вставляют в него все данные через XHR-запросы. В таких случаях проверки исходного HTML будет недостаточно. Нам нужно исследовать сеть, в частности XHR-запросы.
Возьмем, к примеру, Auction. Заполните форму с любым городом и выполните поиск. Вы будете перенаправлены на страницу результатов, которая, пока выполняются запросы для введенного вами города, представляет собой страницу-каркас.
Это вынуждает нас использовать headless-браузер, который может выполнять JavaScript и перехватывать сетевые запросы. Иногда вы можете вызвать конечную точку XHR напрямую, но обычно для этого требуются файлы cookie или другие методы аутентификации. Или вас могут немедленно забанить, поскольку это не обычный путь пользователя. Будьте осторожны.
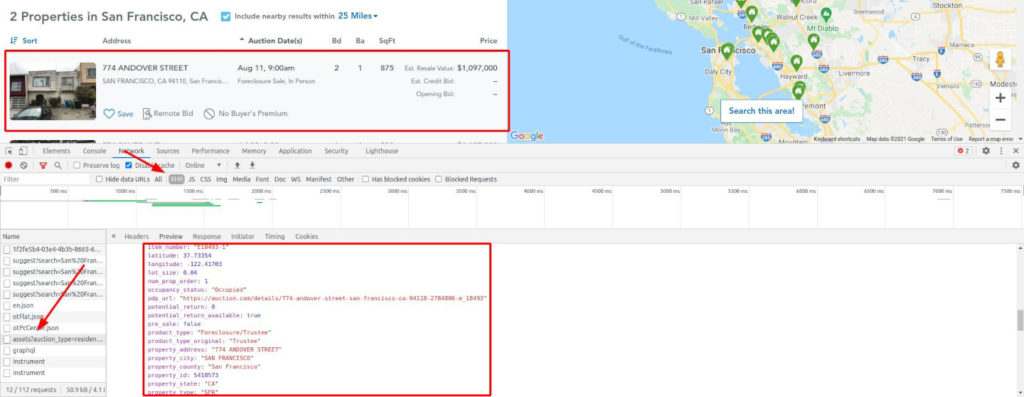
Мы наткнулись на золотую жилу! Взгляните еще раз на изображение.
Все возможные данные, уже очищенные и отформатированные, готовы к извлечению. А также геолокация, внутренние идентификаторы, цена в числовом виде без форматирования, год постройки и т. д.
Рецепты и хитрости для извлечения надежного контента
Уймите свой пыл ненадолго. Получить все с помощью селекторов CSS – это вариант, но есть еще множество других опций. Давайте рассмотрим больше инструментов и идей. Тогда вы сможете самостоятельно принимать решения, зная обо всех альтернативах.
Получение внутренних ссылок
Теперь мы начнем использовать BeautifulSoup для получения значимого контента. Эта библиотека позволяет нам получать контент по идентификаторам, классам, псевдоселекторам и т.д. Мы рассмотрим лишь небольшую часть ее возможностей.
В этом примере со страницы будут извлечены все внутренние ссылки. Упростим себе задачу и будем считать внутренними только ссылки, начинающиеся с косой черты. В более полном варианте следует проверить домен и поддомены.
internalLinks = [
a.get('href') for a in soup.find_all('a')
if a.get('href') and a.get('href').startswith('/')]
print(internalLinks)
Получив все эти ссылки, мы можем убрать дубликаты и поставить их в очередь для последующего парсинга. Поступая таким образом, мы могли бы создать поискового робота для всего сайта, а не только для одной страницы. Однако это уже совсем другая тема, ведь количество страниц для сканирования может увеличиваться, как снежный ком.
[python_ad_block]Будьте осторожны, выполняя это автоматически. Вы можете получить сотни ссылок за несколько секунд, что приведет к слишком большому количеству запросов к одному и тому же сайту. При неосторожном обращении можно нарваться на капчу или бан.
Извлечение ссылок на социальные сети и электронную почту
Другой распространенной задачей парсинга является извлечение ссылок на соцсети и email-адресов. Точного определения для «ссылок на соцсети» нет, поэтому мы будем получать их, основываясь на домене. Что касается email-адресов, то здесь есть два варианта: ссылки «mailto» и проверка всего текста.
Для примера мы будем использовать тестовый сайт.
Для начала получим все ссылки, как в предыдущем примере. Затем переберем их, проверяя, есть ли среди них домены соцсетей или «mailto». Если да, добавим такие URL-адреса в список и выведем конечный список на экран.
links = [a.get('href') for a in soup.find_all('a')]
to_extract = ["facebook.com", "twitter.com", "mailto:"]
social_links = []
for link in links:
for social in to_extract:
if link and social in link:
social_links.append(link)
print(social_links)
# ['mailto:****@webscraper.io',
# 'https://www.facebook.com/webscraperio/',
# 'https://twitter.com/webscraperio']
Эту задачу можно решить и с помощью регулярных выражений. Конечно, если вы не дружите с regexp, это немного сложнее. Основная идея в том, что мы ищем совпадение текста с заданным паттерном.
В нашем случае паттерн — некоторое количество символов (в основном, букв и цифр), за которым идет знак @, а затем опять символы (домен), точка и еще от двух до четырех символов (домен верхнего уровня. Этому паттерну будет соответствовать, например, test@example.com.
Обратите внимание, что этот паттерн несовершенен: он не учитывает составные домены верхнего уровня, такие как co.uk.
Наше регулярное выражение можно запустить для всего контента (HTML) или только для текста. Мы используем HTML, хотя при этом полученные email-адреса будут дублироваться (они есть и в тексте, и в href).
emails = re.findall(
r"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}",
str(soup))
print(emails) # ['****@webscraper.io', '****@webscraper.io']
Автоматический парсинг таблиц
HTML-таблицы все еще широко применяются на сайтах. Мы можем воспользоваться этим, поскольку они обычно структурированы и хорошо отформатированы.
Используя в качестве примера список самых продаваемых альбомов из Википедии, мы извлечем все значения в датафрейм pandas. Это простой пример, но со всеми данными нужно обращаться так, как если бы они были получены из набора данных.
Мы начинаем с поиска таблицы и перебора всех строк tr. Для каждой из них мы ищем ячейки td или th. Дальше удаляем заметки и сворачиваемое содержимое из таблиц (необязательный шаг). Затем добавляем вырезанный текст ячейки в строку и строку — в окончательный вывод.
table = soup.find("table", class_="sortable")
output = []
for row in table.findAll("tr"):
new_row = []
for cell in row.findAll(["td", "th"]):
for sup in cell.findAll('sup'):
sup.extract()
for collapsible in cell.findAll(
class_="mw-collapsible-content"):
collapsible.extract()
new_row.append(cell.get_text().strip())
output.append(new_row)
print(output)
# [
# ['Artist', 'Album', 'Released', ...],
# ['Michael Jackson', 'Thriller', '1982', ...]
# ]
Другой способ – использовать pandas и напрямую импортировать HTML, как показано ниже. При таком подходе все будет сделано за нас: первая строка будет соответствовать заголовкам, а остальные будут вставлены как контент с правильным типом. read_html() возвращает массив, поэтому мы берем первый элемент, а затем удаляем столбец, у которого нет содержимого.
Попав в датафрейм, мы можем выполнить любую операцию. Например — упорядочить по продажам, поскольку pandas преобразовала некоторые столбцы в числа. Или вывести сумму продаж. Здесь это не очень полезно, но идея понятна.
import pandas as pd
table_df = pd.read_html(str(table))[0]
table_df = table_df.drop('Ref(s)', 1)
print(table_df.columns) # ['Artist', 'Album', 'Released' ...
print(table_df.dtypes) # ... Released int64 ...
print(table_df['Claimed sales*'].sum()) # 422
print(table_df.loc[3])
# Artist Pink Floyd
# Album The Dark Side of the Moon
# Released 1973
# Genre Progressive rock
# Total certified copies... 24.4
# Claimed sales* 45
Извлечение информации не из HTML, а из метаданных
Как было замечено ранее, есть способы получить важные данные, не полагаясь на визуальный контент. Давайте рассмотрим пример с «Ведьмаком» от Netflix. Мы попробуем получить список актеров. Легко, правда?
actors = soup.find(class_="item-starring").find(
class_="title-data-info-item-list")
print(actors.text.split(','))
# ['Henry Cavill', 'Anya Chalotra', 'Freya Allan']
Что, если бы мы сказали вам, что актеров и актрис четырнадцать? Вы попытаетесь получить все имена? Не прокручивайте дальше, если хотите попробовать самостоятельно.
Помните: актеров больше, чем кажется на первый взгляд. Вы знаете троих – поищите их в исходном HTML. Честно говоря, внизу есть еще одно место, где показан весь состав, но постарайтесь его избегать.
Netflix включает фрагмент Schema.org со списком актеров и актрис и многими другими данными. Как и в примере с YouTube, иногда удобнее использовать этот подход. Например, даты обычно отображаются в «машинном» формате, который более удобен при парсинге.
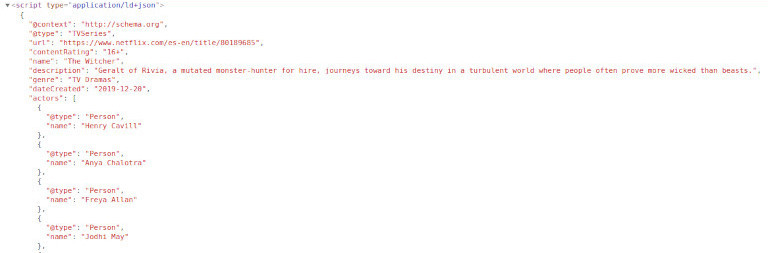
import json
ldJson = soup.find("script", type="application/ld+json")
parsedJson = json.loads(ldJson.contents[0])
print([actor['name'] for actor in parsedJson['actors']])
# [... 'Jodhi May', 'MyAnna Buring', 'Joey Batey' ...]
Разберем следующий пример, используя Instagram-профиль Билли Айлиш. После посещения нескольких страниц вы будете перенаправлены на страницу входа. Будьте осторожны при парсинге Instagram и используйте для тестирования локальный HTML-код.
Обычным подходом будет поиск класса, в нашем случае — Y8-fY. Мы не рекомендуем использовать эти классы, поскольку они, вероятно, изменятся. Судя по виду, они созданы автоматически. Многие современные веб-сайты используют подобный CSS, который генерируется при каждом изменении. Для нас это означает, что мы не можем полагаться на эти классы.
План Б: header ul > li, верно? Это сработает. Но для этого нам нужен рендеринг JavaScript, поскольку он отсутствует при первой загрузке. А как было сказано ранее, этого следует избегать.
Взгляните на исходный HTML. Заголовок и описание включают подписчиков, подписки и количество постов. Это может быть проблемой, поскольку они имеют строковый формат, но мы можем с этим справиться. Если мы хотим только эти данные, нам не понадобится headless-браузер. Отлично!
metaDescription = soup.find("meta", {'name': 'description'})
print(metaDescription['content'])
# 87.9m Followers, 0 Following, 493 Posts ...
Скрытая информация о продукте в онлайн-магазине
Комбинируя некоторые из уже рассмотренных методов, мы хотим извлечь невидимую информацию о продукте. Наш первый пример — это eCommerce-магазин Shopify – Spigen.
Мы сможем извлечь требуемые данные наверняка: не из имени продукта и не из «хлебных крошек», поскольку мы не можем быть уверены в их надежности.

В данном случае они используют itemprop и включают Product и Offer со schema.org. Вероятно, мы могли бы определить, есть ли товар на складе, просмотрев форму или кнопку «Add to cart». Но в этом нет необходимости, мы можем доверять itemprop = "availability". Что касается бренда, то мы можем использовать тот же сниппет кода, что и для YouTube, но с изменением имени свойства на «brand».
brand = soup.find('meta', itemprop="brand")
print(brand['content']) # Tesla
Другой пример со Shopify: nomz. Мы хотим извлечь количество оценок и среднее значение, доступные в HTML. Однако средняя оценка скрыта от просмотра с помощью CSS.
Здесь есть тег, поставленный исключительно для скринридеров, рядом с которым расположены средняя оценка и счетчик. Последние включают текст, что не является проблемой. Но мы можем добиться большего.
Это несложно, если вы изучите исходный код. Схема продукта будет первым, что вы увидите. Применяя то, чему вы научились на примере с Netflix, получите первый блок «ld + json», проанализируйте JSON, и весь контент будет доступен!
import json
ldJson = soup.find("script", type="application/ld+json")
parsedJson = json.loads(ldJson.contents[0])
print(parsedJson["aggregateRating"]["ratingValue"]) # 4.9
print(parsedJson["aggregateRating"]["reviewCount"]) # 57
print(parsedJson["weight"]) # 0.492kg -> extra, not visible in UI
И последнее. Мы воспользуемся атрибутами данных, которые также распространены в eCommerce. Просматривая страницу с бейсбольными битами онлайн-магазина Marucci Sports, мы видим, что у каждого продукта есть несколько полезных точек данных. Цена в числовом формате, идентификатор, название продукта и категория. У нас есть все данные, которые нам могут понадобиться.
products = []
cards = soup.find_all(class_="card")
for card in cards:
products.append({
'id': card.get('data-entity-id'),
'name': card.get('data-name'),
'category': card.get('data-product-category'),
'price': card.get('data-product-price')
})
print(products)
# [
# {
# "category": "Wood Bats, Wood Bats/Professional Cuts",
# "id": "1945",
# "name": "6 Bat USA Professional Cut Bundle",
# "price": "579.99"
# },
# {
# "category": "Wood Bats, Wood Bats/Pro Model",
# "id": "1804",
# "name": "M-71 Pro Model",
# "price": "159.99"
# },
# ...
# ]
Отлично! Мы получили все данные с этой страницы. Теперь нужно проделать это со второй, а затем с третьей. Действуя постепенно, мы с большей вероятностью не нарвемся на бан.
Не забудьте преобразовать эти данные и сохранить их в CSV-файлах или в базе данных. Вложенные поля непросто экспортировать ни в один из этих форматов.
Итоги
Сегодня мы поговорили о веб-парсинге на Python. Нам бы хотелось, чтобы вы усвоили три урока:
- Селекторы CSS хороши для парсинга, но есть и другие варианты.
- Часть контента может быть скрыта или отсутствовать, но при этом быть доступной через метаданные.
- Старайтесь избегать загрузки JavaScript, чтобы повысить производительность.
