
Эта статья представляет собой подробное руководство по визуализации данных в Python. Мы расскажем про построение графиков при помощью библиотек Pandas, Seaborn и Plotly, а также наглядно покажем, что счастье именно в деньгах.
В данной статье мы рассмотрим три разных способа построения графиков в Python. А делать это мы будем, используя данные Всемирного доклада о счастье за 2019 год (ежегодно публикуется ООН). Мы также дополнили эти данные информацией с сайта https://www.gapminder.org/ и из Википедии, чтобы исследовать и визуализировать новые зависимости.
Всемирный доклад о счастье пытается ответить на вопрос о том, какие именно факторы влияют на счастье во всем мире.
Данный доклад о счастье сформирован на основе ответов на вопрос, заданный по системе «лестницы Кэндила» (шкала Кэндила). Респондентов спрашивали, как бы они оценили собственную жизнь по шкале от 0 до 10, где 0 является худшей из возможных оценок, а 10 — наилучшей.
Структура статьи

Данная статья задумывалась одновременно и как пособие по написанию кода, и как своего рода небольшой справочник, в котором можно время от времени искать нужный тип графика. Для экономии места мы иногда помещали несколько графиков в одну картинку, но вы всегда можете найти наш код либо здесь, либо в соответствующем ему Jupyter ноутбуке.
Оглавление
- Моя история построения графиков в Python.
- Важность статистических распределений.
- Загрузка данных и импорт библиотек.
- Быстро: простые графики в Pandas.
- Красиво: продвинутые графики в Seaborn.
- Очень красиво: потрясающие интерактивные графики в Plotly.
На каждую секцию мы поставили гиперссылку, так что можете не читать предисловий, а сразу переходить к графикам. Мы не обидимся.
Моя история построения графиков в Python

Более или менее серьезно я начал изучать Python около двух лет назад. Начиная с этого времени, едва ли не каждую неделю я восторгался его простотой и легкостью использования, а также обилием великолепных библиотек с открытым исходным кодом. И чем больше я знакомился с шаблонами и концепциями языка, тем больше все это обретало смысл.
Matplotlib
Но с построением графиков все происходило ровно наоборот. В начале практически каждый мой график, построенный в Matplotlib, напоминал мне какого-то преступника, сбежавшего из 80-х годов. Более того, чтобы построить такую мерзость, мне приходилось проводить целые часы на Stackoverflow. И даже не напоминайте мне про мультидиаграммы. Конечно, результаты выглядят впечатляюще, и ты чувствуешь себя потрясающе, создавая такие вещи программно. Например, строя 50 диаграмм для разных переменных за один раз. Но для этого нужно проделать кучу работы и запомнить множество бесполезных команд.
Seaborn
Знакомство с Seaborn принесло большое облегчение. С помощью этой библиотеки можно несколько абстрагироваться от тонкой настройки. И с точки зрения эстетики получающихся графиков это большой шаг вперед. Но все же Seaborn построена на базе Matplotlib. И зачастую, для нестандартных настроек, приходится переходить к коду Matplotlib.
Bokeh
На короткий момент времени я было подумал, что моим спасением будет Bokeh. Я наткнулся на эту библиотеку, когда работал над геопространственной визуализацией. Но я очень быстро обнаружил, что Bokeh, хоть и отличается от Matplotlib, но построена так же глупо и запутанно.
Plotly
Некоторое время назад, опять-таки работая над визуализацией геопространственных данных, я попробовал plot.ly (далее везде будем называть ее просто plotly). Тогда эта библиотека показалась мне еще более абсурдной, чем все предыдущие. Вам нужно было завести там аккаунт, войти в него на вашем ноутбуке, и только потом plotly начинает строить графики в онлайн режиме. А затем вам нужно еще загрузить эти графики. Я очень быстро отбросил эту библиотеку. Но недавно я наткнулся на YouTube-видео про библиотеки plotly express и plotly 4.0, в котором в том числе говорилось, что они избавились от этой онлайн-чепухи. Я начал играться с этой библиотекой и в результате появилась эта статья. Как говорится, лучше поздно, чем никогда.
Kepler.gl
Не будучи никоим образом библиотекой Python, Kepler.gl, тем не менее, является отличным инструментом для визуализации геопространственных данных. Все что вам нужно, это CSV-файл, который вы легко можете создать при помощи Python.
Мои текущие предпочтения
В конце концов я остановился на библиотеке Pandas для построения графиков на скорую руку, и на Seaborn для презентаций и отчетов (когда визуализация очень важна).
Важность статистических распределений
Я начал изучать статистику (курс Stats 119), учась в Сан-Диего. Этот курс является вводным и включает в себя самые основы статистики, как например, агрегацию данных (визуальную и количественную), концепцию шансов и вероятностей, регрессию, выборки и, самое главное, статистические распределения. В это время мое понимание тех или иных количественных феноменов практически полностью сдвинулось в сторону представления их в виде статистических распределений (как правило, гауссовых).
И по сей день я нахожу потрясающим, как всего две величины, математическое ожидание и дисперсия, могут помочь вам постичь суть явления. Просто зная эти два числа, легко сделать вывод, насколько вероятен тот или иной результат. Мы сразу знаем, в какой области будут основные результаты. Это дает нам возможность быстро выделять статистически значимые явления, не производя при этом сложных вычислений.
В общем, теперь при работе с любыми новыми данными моим первым шагом всегда является попытка визуализировать их статистическое распределение.
Загрузка данных и импорт библиотек

Для начала давайте загрузим данные, которые мы будем использовать в этой статье. Я также произвел предобработку данных (интерполяцию и экстраполяцию — там, где это было уместно).
# загружаем данные
data = pd.read_csv('https://raw.githubusercontent.com/FBosler/AdvancedPlotting/master/combined_set.csv')
# присваиваем метки каждому году
data['Mean Log GDP per capita'] = data.groupby('Year')['Log GDP per capita'].transform(
pd.qcut,
q=5,
labels=(['Lowest','Low','Medium','High','Highest'])
)
Загруженный датасет содержит данные в следующих колонках:
- Year (год): год, в котором производились измерения (с 2007 по 2018).
- Life Ladder («лестница жизни»): респондент измеряет качество свой жизни по шкале от 0 до 10 (наилучшая оценка). Это так называемая лестница или шкала Кэнтрила.
- Log GDP per capita (логарифм ВВП на душу населения): ВВП на душу населения, подсчитанный по паритету покупательной способности доллара в 2011 году. Взято из индикаторов мирового развития (WDI — World Development Indicators), опубликованных Всемирным Банком 14 ноября 2018 года.
- Social support (социальная поддержка): Ответ на вопрос: «Если бы вы были в беде, то могли бы рассчитывать на помощь друзей или родственников или нет?»
- Healthy life expectancy at birth (ожидаемая продолжительность здоровой жизни): ожидаемое количество лет, в течение которых человек сможет вести активный образ жизни без всяких ограничений по здоровью. Показатели — на основе данных Всемирной организации здравоохранения (WHO — World Health Organization) за 2005, 2010, 2015 и 2016 годы.
- Freedom to make life choices (свобода делать жизненный выбор): Ответ на вопрос: «Удовлетворены ли вы вашим уровнем свободы выбирать, что делать со своей жизнью?»
- Generosity (щедрость): Ответ на вопрос: «Жертвовали ли вы деньги на благотворительность в прошлом месяце?» (в привязке к ВВП на душу населения).
- Perceptions of corruption (восприятие коррупции): Ответы на вопросы: «Широко ли распространена коррупция в правительственных кругах?» и «Широко ли распространена коррупция в бизнесе?»
- Positive affect (положительный аффект): включает в себя среднюю частоту счастья, смеха и радости в предыдущий день.
- Negative affect (отрицательный аффект): включает в себя среднюю частоту беспокойства, грусти и гнева в предыдущий день.
- Confidence in national government (доверие собственному правительству): не нуждается в пояснениях.
- Democratic Quality (качество демократии): насколько демократична страна.
- Delivery Quality (качество управления): насколько хорошо страна управляется.
- Gapminder Life Expectancy (продолжительность жизни от Gapminder): данные о продолжительности жизни от Gapminder.
- Gapminder Population (население страны от Gapminder): население страны.
Импортирование
import plotly
import pandas as pd
import numpy as np
import seaborn as sns
import plotly.express as pximport matplotlib%matplotlib inlineassert matplotlib.__version__ == "3.1.0","""
Please install matplotlib version 3.1.0 by running:
1) !pip uninstall matplotlib
2) !pip install matplotlib==3.1.0
"""
Быстро: простые графики в Pandas

Pandas имеет встроенные функции построения графиков, которые можно вызывать непосредственно из Series и DataFrame. За что я обожаю эти функции, это за их краткость, за разумные значения по умолчанию и за то, что с их помощью можно быстро понять, что происходит с данными.
Для создания графика просто вызовите метод .plot(kind=<TYPE OF PLOT>) следующим образом:
np.exp(data[data['Year']==2018]['Log GDP per capita']).plot(
kind='hist'
)
В результате выполнения этой команды получится следующий график:
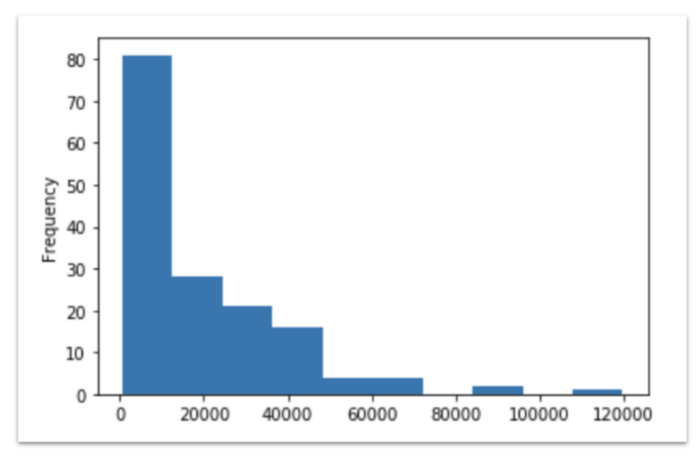
При построении графиков в Pandas я использую пять основных параметров:
kind: Pandas должна знать, какого типа график вы хотите строить. Возможны следующие варианты:hist, bar, barh, scatter, area, kde, line, box, hexbin, pie.figsize: Позволяет переопределить значение размера, заданное по умолчанию (6 дюймов в ширину и 4 дюйма в высоту). Данный параметр принимает на вход кортеж, напримерfigsize=(12,8), что я часто использую.title: Добавляет к графику заголовок. Как правило, я его использую, чтобы кратко описать, что происходит на графике, дабы потом это можно было быстро понять. Данный параметр принимает на вход строку.bins: Позволяет переопределить ширину областей гистограммы. Данный параметр принимает на вход список или подобную ему последовательность, напримерbins=np.arange(2,8,0.25).xlim/ylim: Позволяет переопределить максимальные и минимальные значения осейxиy. Оба параметра принимают на вход кортежи, напримерxlim=(0,5).
Давайте быстро пробежимся по некоторым типам таких графиков.
Вертикальная гистограмма
data[
data['Year'] == 2018
].set_index('Country name')['Life Ladder'].nlargest(15).plot(
kind='bar',
figsize=(12,8)
)
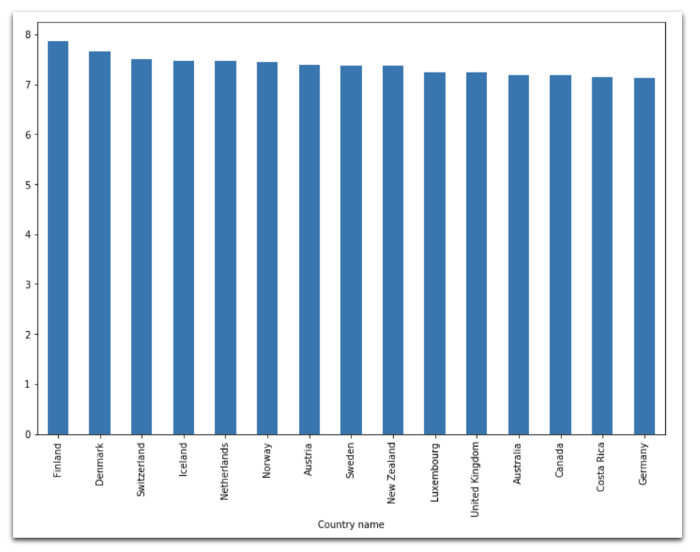
Горизонтальная гистограмма
np.exp(data[
data['Year'] == 2018
].groupby('Continent')['Log GDP per capita']\
.mean()).sort_values().plot(
kind='barh',
figsize=(12,8)
)
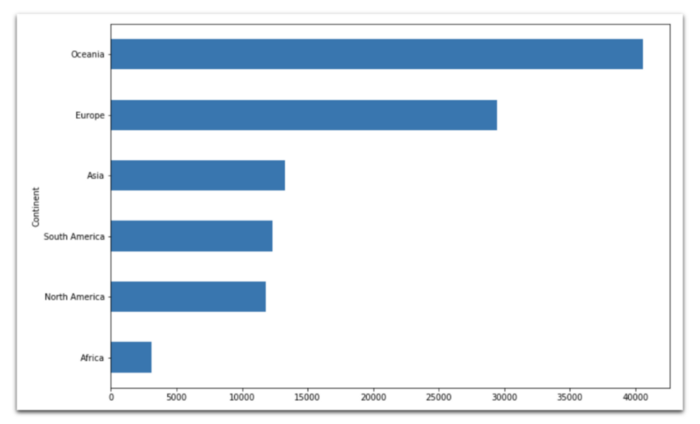
Ящик с усами (Box plot)
data['Life Ladder'].plot(
kind='box',
figsize=(12,8)
)
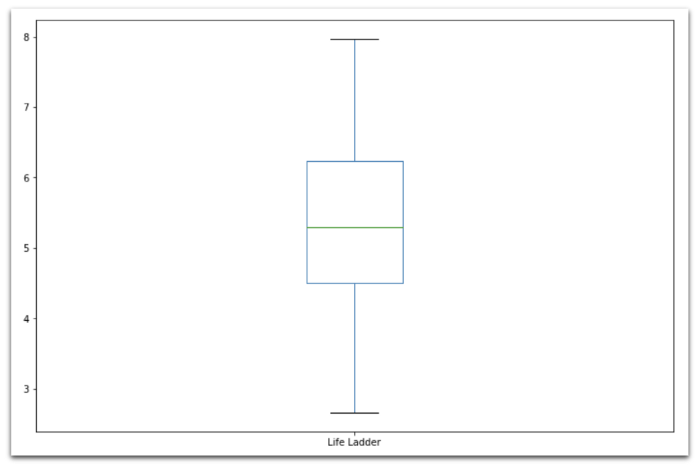
Точечный график (диаграмма рассеяния)
data[['Healthy life expectancy at birth','Gapminder Life Expectancy']].plot(
kind='scatter',
x='Healthy life expectancy at birth',
y='Gapminder Life Expectancy',
figsize=(12,8)
)
Гексбиновая диаграмма
data[data['Year'] == 2018].plot(
kind='hexbin',
x='Healthy life expectancy at birth',
y='Generosity',
C='Life Ladder',
gridsize=20,
figsize=(12,8),
cmap="Blues", # по умолчанию зеленый
sharex=False # необходимо, чтобы не допустить ошибок
)
Круговая диаграмма
data[data['Year'] == 2018].groupby(
['Continent']
)['Gapminder Population'].sum().plot(
kind='pie',
figsize=(12,8),
cmap="Blues_r", # по умолчанию оранжевый
)
Диаграмма с накоплением
data.groupby(
['Year','Continent']
)['Gapminder Population'].sum().unstack().plot(
kind='area',
figsize=(12,8),
cmap="Blues", # по умолчанию оранжевый
)
Линейный график
data[
data['Country name'] == 'Germany'
].set_index('Year')['Life Ladder'].plot(
kind='line',
figsize=(12,8)
)
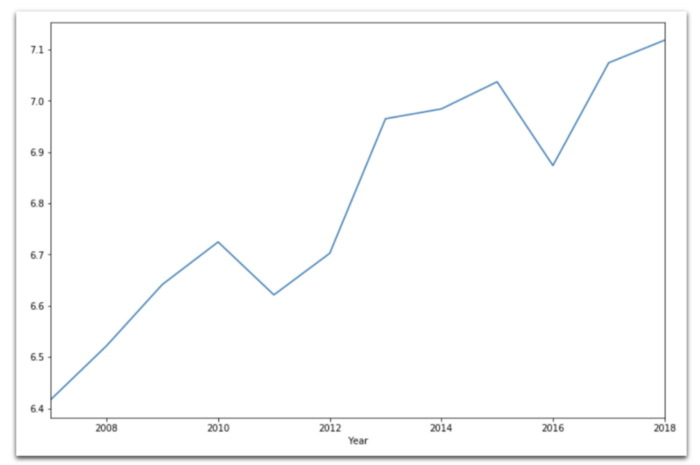
Выводы
Строить графики в библиотеке pandas удобно, просто и быстро. Правда, они выходят слегка корявыми. Но это нормально, так как для создания более эстетичных графиков у нас есть другие инструменты. Переходим к библиотеке seaborn.
Красиво: продвинутые графики в Seaborn

Seaborn использует параметры вывода по умолчанию. Чтобы убедиться, что ваши результаты совпадают с моими, выполните следующий код.
sns.reset_defaults()
sns.set(
rc={'figure.figsize':(7,5)},
style="white" # nicer layout
)
Построение одномерных распределений
Как уже говорилось ранее, я большой фанат статистических распределений. Гистограммы и распределения плотности вероятности являются мощными способами визуализации критических характеристик конкретной переменной. Давайте посмотрим, как мы строим распределения для одной переменной и как строим распределения нескольких переменных в одной диаграмме.
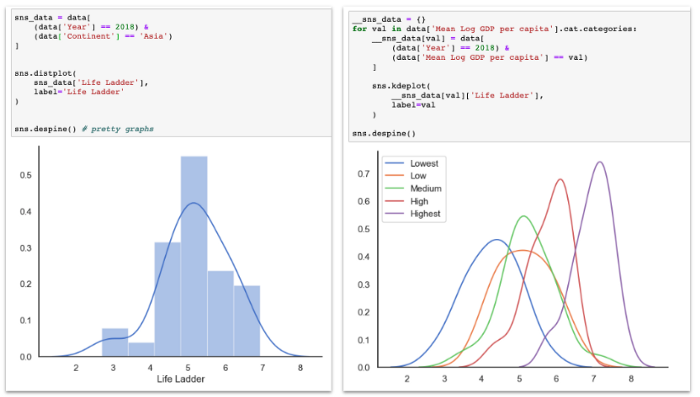
Построение двумерных распределений
Всякий раз, когда я хочу визуально исследовать взаимосвязь между двумя и более переменными, это обычно сводится к некоторой форме диаграммы рассеяния и оценке распределений. Существует три варианта концептуально одного и того же графика. В каждом из них график, расположенный в центре, помогает понять совместное распределение частот между двумя переменными. Вдобавок, на правой и верхней границе этого центрального графика изображено предельное одномерное распределение соответствующей переменной (в виде ядерной оценки плотности вероятности или гистограммы).
sns.jointplot(
x='Log GDP per capita',
y='Life Ladder',
data=data,
kind='scatter' # or 'kde' or 'hex'
)
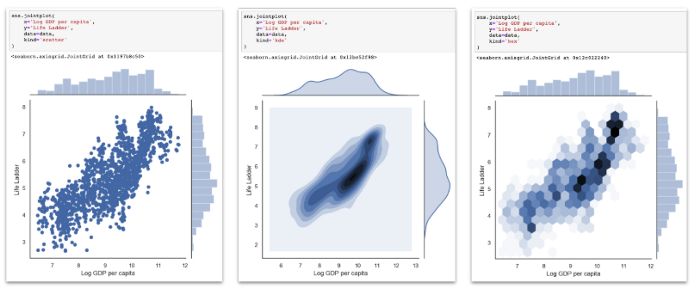
Точечная диаграмма
Точечная диаграмма — это отличный способ визуализации совместной плотности распределения двух случайных величин. Мы можем добавить третью переменную, выражая ее при помощи оттенка цвета, а также и четвертую, визуализируя ее при помощи размера точки.
sns.scatterplot(
x='Log GDP per capita',
y='Life Ladder',
data=data[data['Year'] == 2018],
hue='Continent',
size='Gapminder Population'
)
# параметры hue и size не обязательны
sns.despine()
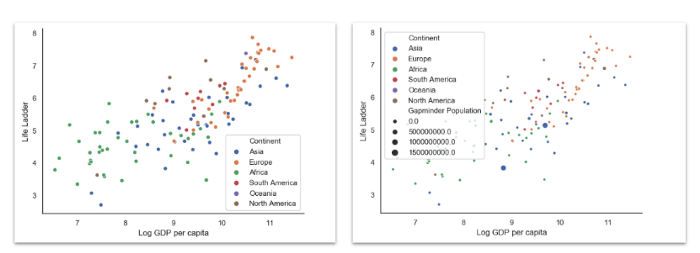
Скрипичный график (Violin plot)
Скрипичный график — это фактически комбинация двух других графиков, ящика с усами (box plot) и графика ядерной оценки плотности вероятности. Он показывает плотность распределения количественной переменной в зависимости от значений категориальной переменной так, чтобы их можно было сравнить между собой.
sns.set(
rc={'figure.figsize':(18,6)},
style="white"
)
sns.violinplot(
x='Continent',
y='Life Ladder',
hue='Mean Log GDP per capita',
data=data
)
sns.despine()
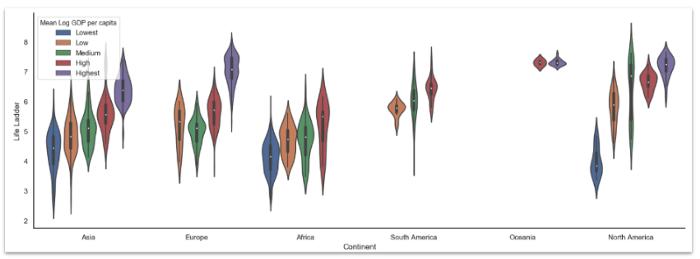
Матричная диаграмма рассеяния
Матричная диаграмма рассеяния представляет собой все возможные попарные диаграммы рассеяния, представленные в виде большой квадратной матрицы. Я обычно нахожу этот вид графика несколько информационно перегруженным, но как бы то ни было, он может помочь найти закономерности.
sns.set(
style="white",
palette="muted",
color_codes=True
)
sns.pairplot(
data[data.Year == 2018][[
'Life Ladder','Log GDP per capita',
'Social support','Healthy life expectancy at birth',
'Freedom to make life choices','Generosity',
'Perceptions of corruption', 'Positive affect',
'Negative affect','Confidence in national government',
'Mean Log GDP per capita'
]].dropna(),
hue='Mean Log GDP per capita'
)
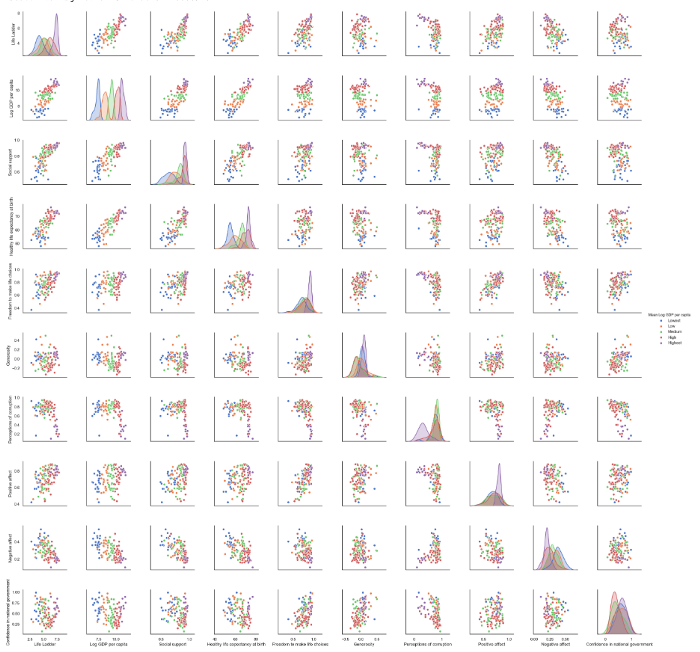
Фасетные сетки (Facet Grid)
Фасетные сетки в Seaborn — это для меня один из основных аргументов в пользу использования данной библиотеки. С ее помощью можно строить мультиграфики на одном дыхании! Рассматривая матричную диаграмму рассеяния, мы уже видели один из примеров фасетной сетки (функция FacetGrid в Seaborn). Данная функция позволяет создавать множество графиков, сегментированных по переменным. Например, в строках матрицы может быть одна переменная (подушевой ВВП, разбитый на пять категорий), а в колонках другая (континенты).
Для написания кода здесь требуется несколько больше кастомизации (а значит — использования Matplotlib), чем мне бы хотелось, но ничего не поделаешь.
g = sns.FacetGrid(
data.groupby(['Mean Log GDP per capita','Year','Continent'])['Life Ladder'].mean().reset_index(),
row='Mean Log GDP per capita',
col='Continent',
margin_titles=True
)
g = (g.map(plt.plot, 'Year','Life Ladder'))
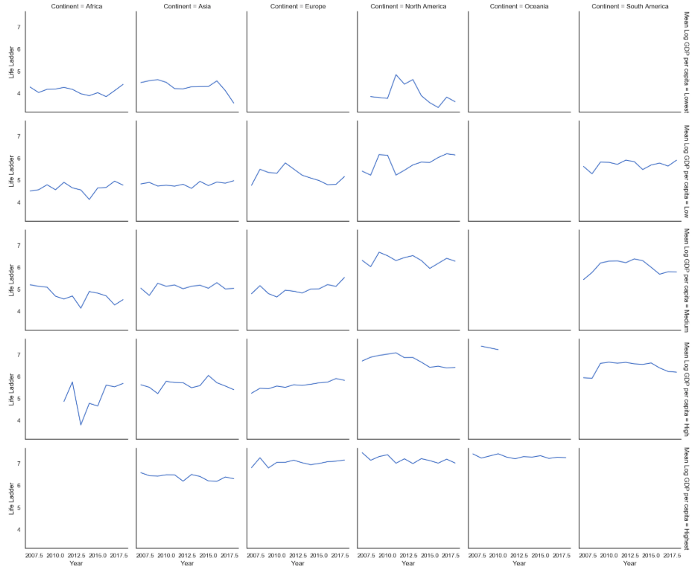
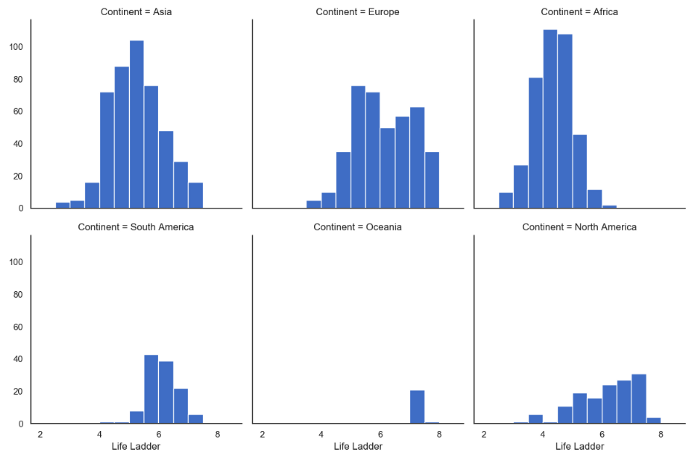
FacetGrid — гистограммы
g = sns.FacetGrid(data, col="Continent", col_wrap=3,height=4) g = (g.map(plt.hist, "Life Ladder",bins=np.arange(2,9,0.5)))
FacetGrid — графики ядерной оценки плотности вероятности с аннотацией
Также возможно добавить в каждый график, находящийся в фасетной сетке, свою специфичную аннотацию. В следующем примере мы добавляем математическое ожидание и дисперсию, а также вертикальную пунктирную линию, проходящую через значение математического ожидания.
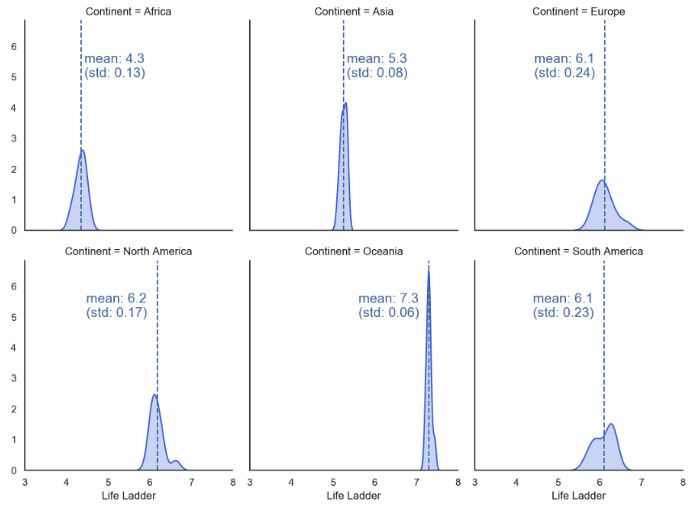
def vertical_mean_line(x, **kwargs):
plt.axvline(x.mean(), linestyle ="--",
color = kwargs.get("color", "r"))
txkw = dict(size=15, color = kwargs.get("color", "r"))
label_x_pos_adjustment = 0.08 # в зависимости от ваших данных может потребоваться кастомизация
label_y_pos_adjustment = 5 # в зависимости от ваших данных может потребоваться кастомизация
if x.mean() < 6: # this needs customization based on your data
tx = "mean: {:.2f}\n(std: {:.2f})".format(x.mean(),x.std())
plt.text(x.mean() + label_x_pos_adjustment, label_y_pos_adjustment, tx, **txkw)
else:
tx = "mean: {:.2f}\n (std: {:.2f})".format(x.mean(),x.std())
plt.text(x.mean() -1.4, label_y_pos_adjustment, tx, **txkw)
_ = data.groupby(['Continent','Year'])['Life Ladder'].mean().reset_index()
g = sns.FacetGrid(_, col="Continent", height=4, aspect=0.9, col_wrap=3, margin_titles=True)
g.map(sns.kdeplot, "Life Ladder", shade=True, color='royalblue')
g.map(vertical_mean_line, "Life Ladder")
FacetGrid — температурные карты
Один из моих любимых графиков — это температурные карты, упакованные в фасетные сетки. Этот тип графика очень полезен, когда нужно визуализировать четыре различные переменные в одной картинке. Код выглядит несколько громоздким, но он может быть легко приспособлен под ваши нужды. Также важно заметить, что подобный тип графиков требует сравнительно большого объема данных и хорошей сегментации. Пропуски в данных здесь обрабатываются плохо.
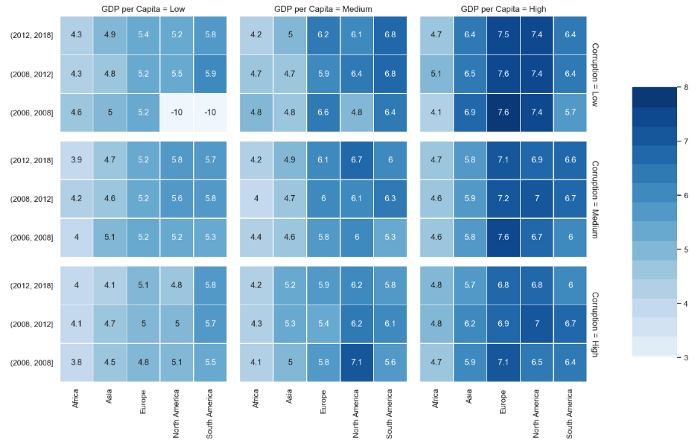
def draw_heatmap(data,inner_row, inner_col, outer_row, outer_col, values, vmin,vmax):
sns.set(font_scale=1)
fg = sns.FacetGrid(
data,
row=outer_row,
col=outer_col,
margin_titles=True
)
position = left, bottom, width, height = 1.4, .2, .1, .6
cbar_ax = fg.fig.add_axes(position)
fg.map_dataframe(
draw_heatmap_facet,
x_col=inner_col,
y_col=inner_row,
values=values,
cbar_ax=cbar_ax,
vmin=vmin,
vmax=vmax
)
fg.fig.subplots_adjust(right=1.3)
plt.show()
def draw_heatmap_facet(*args, **kwargs):
data = kwargs.pop('data')
x_col = kwargs.pop('x_col')
y_col = kwargs.pop('y_col')
values = kwargs.pop('values')
d = data.pivot(index=y_col, columns=x_col, values=values)
annot = round(d,4).values
cmap = sns.color_palette("Blues",30) + sns.color_palette("Blues",30)[0::2]
#cmap = sns.color_palette("Blues",30)
sns.heatmap(
d,
**kwargs,
annot=annot,
center=0,
cmap=cmap,
linewidth=.5
)
# Data preparation
_ = data.copy()
_['Year'] = pd.cut(_['Year'],bins=[2006,2008,2012,2018])
_['GDP per Capita'] = _.groupby(['Continent','Year'])['Log GDP per capita'].transform(
pd.qcut,
q=3,
labels=(['Low','Medium','High'])
).fillna('Low')
_['Corruption'] = _.groupby(['Continent','GDP per Capita'])['Perceptions of corruption'].transform(
pd.qcut,
q=3,
labels=(['Low','Medium','High'])
)
_ = _[_['Continent'] != 'Oceania'].groupby(['Year','Continent','GDP per Capita','Corruption'])['Life Ladder'].mean().reset_index()
_['Life Ladder'] = _['Life Ladder'].fillna(-10)
draw_heatmap(
data=_,
outer_row='Corruption',
outer_col='GDP per Capita',
inner_row='Year',
inner_col='Continent',
values='Life Ladder',
vmin=3,
vmax=8,
)
Очень красиво: потрясающие интерактивные графики в Plotly

И наконец-то, больше никакой Matplotlib! У библиотеки Plotly есть три важных свойства:
- «Зависание»: когда курсор «зависает» над графиком, всплывает окно с аннотацией.
- Интерактивность: графики легко могут быть сделаны интерактивными (то есть меняющимися во времени в зависимости от ваших действий) без каких-либо дополнительных настроек.
- Прекрасные геопространственные карты: в Plotly есть свои базовые инструменты для построения карт, однако для совершенного результата всегда можно воспользоваться интеграцией с Mapbox.
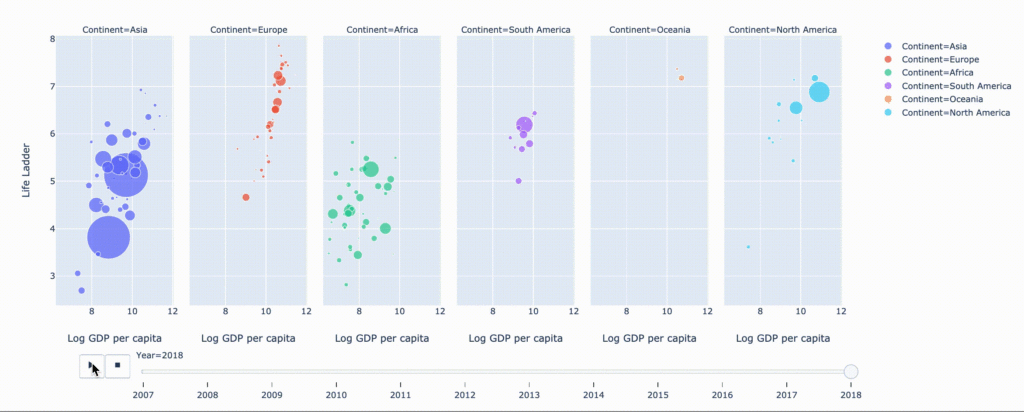
Точечный график (диаграмма рассеяния)
С помощью библиотеки Plotly графики строятся следующим образом. Создаем переменную fig = x.<PLOT TYPE>(PARAMS), а затем запускаем функцию fig.show().
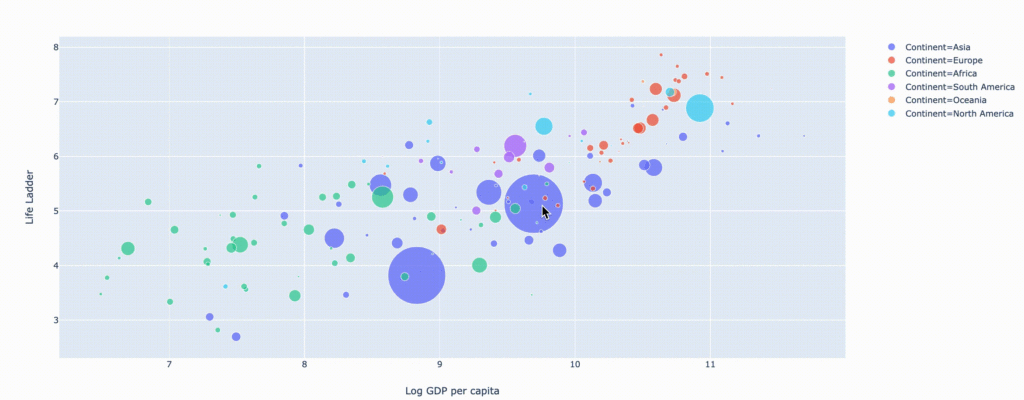
Точечный график (диаграмма рассеяния) — путешествие во времени
fig = px.scatter(
data_frame=data,
x="Log GDP per capita",
y="Life Ladder",
animation_frame="Year",
animation_group="Country name",
size="Gapminder Population",
color="Continent",
hover_name="Country name",
facet_col="Continent",
size_max=45,
category_orders={'Year':list(range(2007,2019))}
)
fig.show()
Параллельные категории — прикольный способ визуализировать категоральные переменные
def q_bin_in_3(col):
return pd.qcut(
col,
q=3,
labels=['Low','Medium','High']
)
_ = data.copy()
_['Social support'] = _.groupby('Year')['Social support'].transform(q_bin_in_3)
_['Life Expectancy'] = _.groupby('Year')['Healthy life expectancy at birth'].transform(q_bin_in_3)
_['Generosity'] = _.groupby('Year')['Generosity'].transform(q_bin_in_3)
_['Perceptions of corruption'] = _.groupby('Year')['Perceptions of corruption'].transform(q_bin_in_3)
_ = _.groupby(['Social support','Life Expectancy','Generosity','Perceptions of corruption'])['Life Ladder'].mean().reset_index()
fig = px.parallel_categories(_, color="Life Ladder", color_continuous_scale=px.colors.sequential.Inferno)
fig.show()
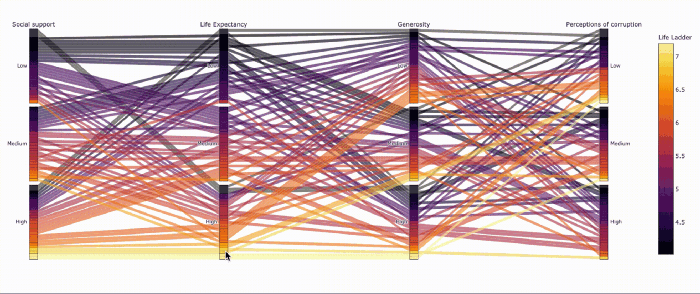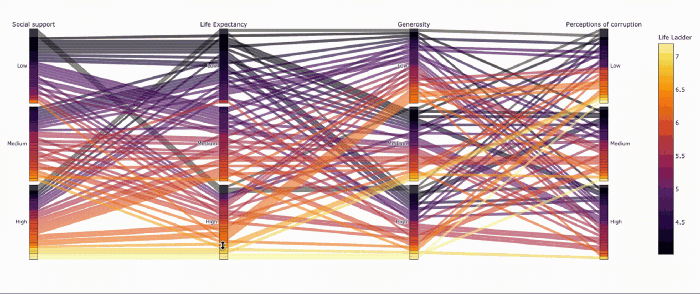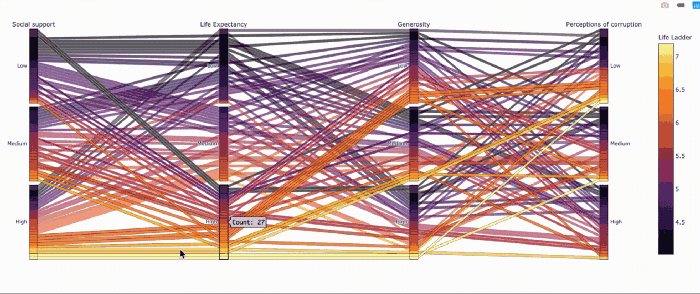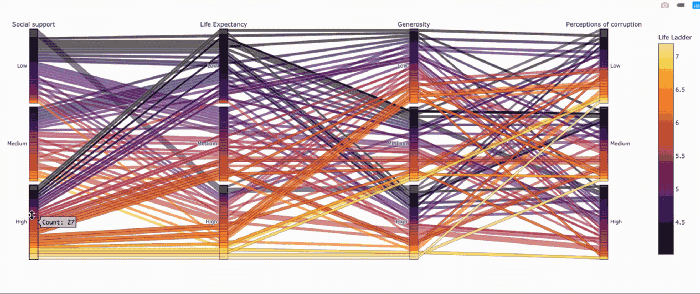
Столбчатые диаграммы — пример интерактивных фильтров
fig = px.bar(
data,
x="Continent",
y="Gapminder Population",
color="Mean Log GDP per capita",
barmode="stack",
facet_col="Year",
category_orders={"Year": range(2007,2019)},
hover_name='Country name',
hover_data=[
"Mean Log GDP per capita",
"Gapminder Population",
"Life Ladder"
]
)
fig.show()
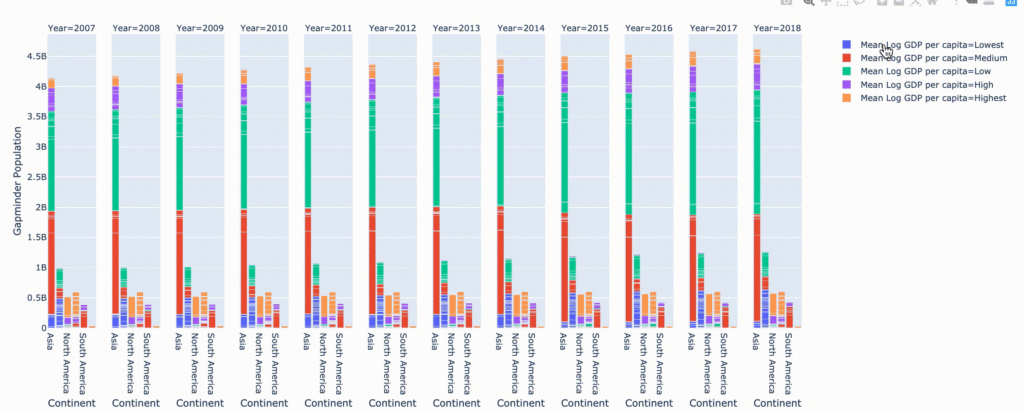
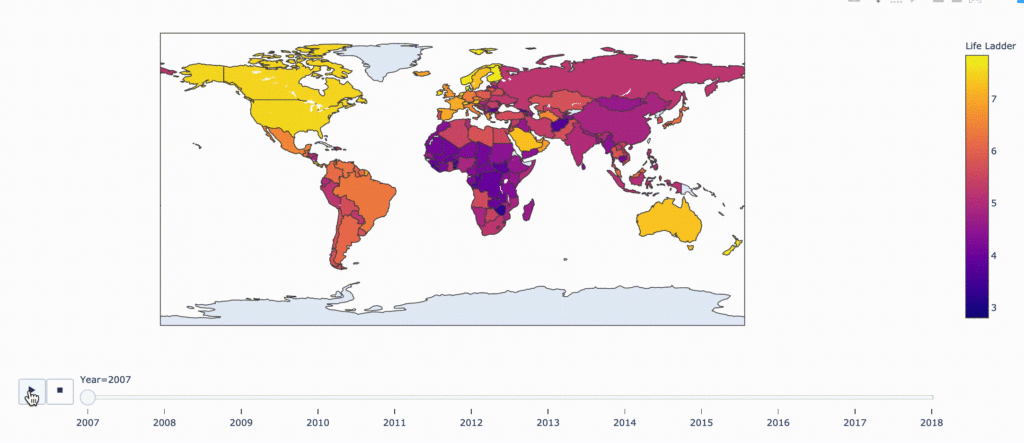
Сюжетный график — как уровень счастья меняется со временем
fig = px.choropleth(
data,
locations="ISO3",
color="Life Ladder",
hover_name="Country name",
animation_frame="Year")
fig.show()
Выводы и заключение
На сегодня пока все. Из данной статьи вы узнали, как стать настоящим Python-ниндзя в визуализации данных. Еще вы узнали, как можно молучить быстрый результат более эффективно, а также — как создавать очень красивые диаграммы, когда опять надвигается проклятое заседание правления.Кроме того, вы узнали, как создавать интерактивные диаграммы, которые особенно полезны при визуализации геопространственных данных.
