
Пакет pandas — это самый важный инструмент из арсенала специалистов по Data Science и аналитиков, работающих на Python. Мощные инструменты машинного обучения и блестящие средства визуализации могут привлекать внимание, но в основе большинства проектов по работе с данными лежит pandas.
Название pandas происходит от термина «панельные данные» (англ. panel data). В эконометрии это многомерные структурированные наборы данных. (Источник — Википедия).
Если вы собираетесь построить карьеру в сфере науки о данных, то одним из первых ваших действий должно стать изучение этой библиотеки. В этой статье мы изложим основные сведения о pandas. Вы узнаете, как установить этот пакет и как его использовать. Кроме того, мы рассмотрим, как pandas работает с другими популярными пакетами для анализа данных Python, такими как matplotlib и scikit-learn.
Содержание
- Для чего нужна библиотека pandas?
- Какое место занимает pandas в наборе инструментов Data Science?
- Когда стоит начать использовать pandas?
- Установка и импорт pandas
- Основные компоненты pandas: Series и DataFrame
- Как считывать данные в DataFrame pandas
- Наиболее важные операции с DataFrame
Для чего нужна библиотека pandas?
У pandas так много применений, так что лучше перечислить не ее возможности, а то, что она не может делать.
По сути, этот инструмент является домом для ваших данных. С помощью pandas вы знакомитесь со своими данными, очищая, преобразуя и анализируя их.
Допустим, вы хотите изучить набор данных, хранящийся в CSV-формате на вашем компьютере. Pandas извлечет данные из этого CSV в DataFrame — по сути, таблицу, — а затем позволит вам сделать следующее:
- Рассчитать статистику и ответить на вопросы о данных, такие как:
- Каково среднее значение, медиана, максимум или минимум для каждого столбца?
- Коррелирует ли столбец A со столбцом B?
- Как выглядит распределение данных в столбце C?
- Очистить данные, например, удалив пропущенные значения или отфильтровав строки или столбцы по каким-либо критериям.
- Визуализировать данные с помощью Matplotlib. Можно построить столбчатые диаграммы, линейные графики, гистограммы.
- Сохранить очищенные, преобразованные данные в CSV и другие форматы файлов или в базе данных.
Прежде чем приступать к моделированию или сложной визуализации, необходимо хорошо понять природу вашего набора данных, и pandas является лучшим средством для этого.
Какое место занимает pandas в наборе инструментов Data Science?
Библиотека pandas не только является центральным компонентом набора инструментов для науки о данных, но и используется в сочетании с другими библиотеками из этого набора.
Pandas построена на основе пакета NumPy, то есть многие структуры NumPy используются или воспроизводятся в pandas. Данные в pandas часто используются для статистического анализа в SciPy, в функциях построения графиков из Matplotlib и в алгоритмах машинного обучения в Scikit-learn.
Jupyter Notebook предлагает хорошую среду для использования pandas для исследования и моделирования данных, но pandas также легко можно использовать в текстовых редакторах.
Jupyter Notebook дает нам возможность выполнять код в конкретной ячейке, а не запускать весь файл. Это экономит много времени при работе с большими наборами данных и сложными преобразованиями. Блокноты также предоставляют простой способ визуализации pandas DataFrame и графиков. Собственно говоря, эта статья была полностью создана в Jupyter Notebook.
Когда стоит начать использовать pandas?
Если у вас нет опыта программирования на Python, то вам лучше пока воздержаться от изучения pandas. Уровень опытного разработчика не обязателен, но вы должны знать основы работы с Python (списки, кортежи, словари, функции, итерации и т. п. вещи). Также желательно сперва познакомиться с NumPy из-за сходства, упомянутого выше.
Тем, кто собирается пройти обучение на курсах по data science, настоятельно рекомендуется начать изучать pandas самостоятельно еще до прохождения курса.
Даже если в программе курса будет обучение pandas, заранее приобретенные навыки позволят вам максимально эффективно использовать время для изучения и освоения более сложного материала.
Установка и импорт pandas
Pandas — это простой в установке пакет. Откройте терминал или командную строку и установите пакет с помощью одной из следующих команд:
conda install pandas
ИЛИ
pip install pandas
Также, если вы просматриваете эту статью в Jupyter Notebook, можно запустить эту ячейку:
!pip install pandas
Восклицательный знак в начале позволяет запускать ячейки так, как если бы вы работали в терминале.
При импорте pandas обычно используется более короткое имя пакета, поскольку набирать его придется очень часто:
import pandas as pd
Переходим к основным компонентам pandas.
Основные компоненты pandas: Series и DataFrame
Двумя основными компонентами pandas являются Series и DataFrame.
Series — это, по сути, столбец, а DataFrame — это многомерная таблица, состоящая из набора Series.
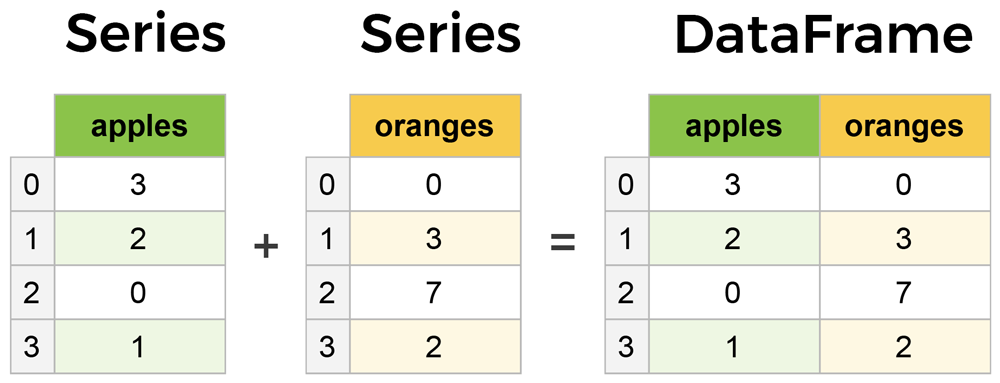
DataFrame и Series очень похожи, поскольку многие операции, которые вы можете выполнять с одним из них, можно выполнять и с другим, например, заполнение нулевых значений и вычисление среднего значения.
Вы увидите эти компоненты в действии, когда мы начнем работать с данными.
Создание DataFrame pandas с нуля
Умение создавать DataFrame непосредственно на Python — полезный навык. Он пригодится вам при тестировании новых методов и функций, найденных в документации pandas.
Существует множество способов создания DataFrame с нуля, но отличным вариантом является использование простого словаря.
Допустим, у нас есть фруктовый киоск, где продаются яблоки и апельсины. Мы хотим иметь столбец для каждого фрукта и строку для каждой покупки клиента. Чтобы организовать это в виде словаря для pandas, мы можем сделать так:
data = {
'apples': [3, 2, 0, 1],
'oranges': [0, 3, 7, 2]
}
И затем передать data в конструктор DataFrame:
purchases = pd.DataFrame(data) purchases
| apples | oranges | |
| 0 | 3 | 0 |
| 1 | 2 | 3 |
| 2 | 0 | 7 |
| 3 | 1 | 2 |
Как это работает?
Каждый элемент ключ-значение в данных соответствует столбцу в полученном DataFrame.
Индекс этого DataFrame был задан при создании самого DataFrame в виде чисел 0-3. Но индекс также можно создать самостоятельно при инициализации DataFrame.
Пусть в качестве индекса будут имена клиентов:
purchases = pd.DataFrame(data, index=['June', 'Robert', 'Lily', 'David']) purchases
| apples | oranges | |
| June | 3 | 0 |
| Robert | 2 | 3 |
| Lily | 0 | 7 |
| David | 1 | 2 |
Теперь мы можем найти заказ клиента по его имени.
purchases.loc['June']
Примечание переводчика: loc — сокращение от locate, что в переводе с английского означает «определять местонахождение».
Результат:
apples 3 oranges 0 Name: June, dtype: int64
Более подробно о поиске и извлечении данных из DataFrame мы поговорим позже. Сейчас сосредоточимся на создании DataFrame с любыми произвольными данными. Давайте перейдем к быстрым методам создания DataFrame из различных источников.
Как считывать данные в DataFrame pandas
Загрузить данные в DataFrame из файлов различных форматов довольно просто. В следующих примерах мы будем продолжать использовать данные о яблоках и апельсинах, но на этот раз они будут поступать из файлов.
Чтение данных из CSV-файлов
Для загрузки данных из CSV-файлов достаточно одной строки:
df = pd.read_csv('purchases.csv')
df
| Unnamed: 0 | apples | oranges | |
| 0 | June | 3 | 0 |
| 1 | Robert | 2 | 3 |
| 2 | Lily | 0 | 7 |
| 3 | David | 1 | 2 |
CSV не имеют индексов, как наши DataFrames, поэтому все, что нам нужно сделать, это просто определить index_col при чтении:
df = pd.read_csv('purchases.csv', index_col=0)
df
| apples | oranges | |
| June | 3 | 0 |
| Robert | 2 | 3 |
| Lily | 0 | 7 |
| David | 1 | 2 |
Здесь мы устанавливаем, что индексом будет нулевой столбец.
Большинство CSV не имеют индексного столбца, поэтому обычно вам не нужно беспокоиться об этом шаге.
Чтение данных из JSON
Если у вас есть файл JSON, который по сути является хранимым словарем Python, pandas может прочитать его так же легко:
df = pd.read_json('purchases.json')
df
| apples | oranges | |
| David | 1 | 2 |
| June | 3 | 0 |
| Lily | 0 | 7 |
| Robert | 2 | 3 |
Обратите внимание, что на этот раз мы получили правильный индекс, поскольку использование JSON позволяет индексам работать через вложенность. Попробуйте открыть файл data_file.json в блокноте, чтобы посмотреть, как он работает.
Pandas пытается понять, как создать DataFrame, анализируя структуру вашего JSON, и иногда у него это не получается. Вам часто придется задавать именованный аргумент orient, зависящий от формата строки JSON. Почитать об этом аргументе можно в документации read_json.
От редакции Pythonist: также предлагаем почитать статью «Работа с большими данными в Python при помощи Pandas и JSON».
Чтение данных из базы данных SQL
Если вы работаете с данными из базы данных SQL, вам нужно сначала установить соединение с помощью соответствующей библиотеки Python, а затем передать запрос в pandas. Для демонстрации мы будем использовать SQLite.
Для начала нужно установить pysqlite3. Выполните следующую команду в терминале:
pip install pysqlite3
Или запустите эту ячейку, если находитесь в Jupyter Notebook:
!pip install pysqlite3
sqlite3 используется для соединения с базой данных, которую мы затем можем использовать для создания DataFrame с помощью запроса SELECT.
Итак, сначала мы создадим соединение с файлом базы данных SQLite:
import sqlite3
con = sqlite3.connect("database.db")
Совет относительно SQL
Если у вас данные хранятся на PostgreSQL, MySQL или другом SQL-сервере, вам нужно использовать правильную библиотеку Python для установки соединения. Например, для соединения с PostgreSQL часто используется psycopg2. Кроме того, вы можете соединяться с URI базы данных, а не с файлом, как в нашем примере с SQLite.
В этой базе данных SQLite у нас есть таблица под названием purchases, а наш индекс — столбец index.
Передав запрос SELECT и наш con, мы можем читать из таблицы purchases:
df = pd.read_sql_query("SELECT * FROM purchases", con)
df
| apples | oranges | ||
| 0 | June | 3 | 0 |
| 1 | Robert | 2 | 3 |
| 2 | Lily | 0 | 7 |
| 3 | David | 1 | 2 |
Как и в случае с CSV, мы можем передать index_col='index', но мы также можем установить индекс постфактум:
df = df.set_index('index')
df
| apples | oranges | |
| index | ||
| June | 3 | 0 |
| Robert | 2 | 3 |
| Lily | 0 | 7 |
| David | 1 | 2 |
Фактически, мы в любое время можем использовать set_index() для любого DataFrame, используя любой столбец. Индексирование Series и DataFrame — очень распространенная задача, и стоит помнить о различных способах ее выполнения.
Преобразование данных обратно в CSV, JSON или SQL
Итак, после длительной работы по очистке данных вы готовы сохранить их в файл. Pandas предоставляет интуитивно понятные команды не только для чтения, но и для сохранения данных:
df.to_csv('new_purchases.csv')
df.to_json('new_purchases.json')
df.to_sql('new_purchases', con)
От редакции Pythonist: также предлагаем почитать статью «Как очистить данные при помощи Pandas».
Когда мы сохраняем файлы JSON и CSV, все, что нам нужно передать в эти функции, — это желаемое имя файла с соответствующим расширением. При использовании SQL мы не создаем новый файл, а вставляем новую таблицу в базу данных, используя нашу переменную con.
А теперь давайте перейдем к импорту реальных данных и подробно рассмотрим несколько операций, которые вы будете часто использовать.
Наиболее важные операции с DataFrame
Для DataFrame есть сотни методов и других операций, имеющих решающее значение для любого анализа. Как новичок вы должны знать операции для простого преобразования ваших данных и для базового статистический анализ.
Для начала загрузим набор данных, касающихся фильмов IMDB:
movies_df = pd.read_csv("IMDB-Movie-Data.csv", index_col="Title")
Мы загружаем этот набор данных из CSV и определяем названия фильмов нашим индексом.
Просмотр данных
Первое, что нужно сделать при открытии нового набора данных, — распечатать несколько строк, чтобы сохранить их в качестве визуальной ссылки. Для этого мы используем функцию .head():
movies_df.head()
| Rank | Genre | Description | Director | Actors | Year | Runtime (Minutes) | Rating | Votes | Revenue (Millions) | Metascore | |
| Title | |||||||||||
| Guardians of the Galaxy | 1 | Action,Adventure,Sci-Fi | A group of intergalactic criminals are forced … | James Gunn | Chris Pratt, Vin Diesel, Bradley Cooper, Zoe S… | 2014 | 121 | 8.1 | 757074 | 333.13 | 76.0 |
| Prometheus | 2 | Adventure,Mystery,Sci-Fi | Following clues to the origin of mankind, a te… | Ridley Scott | Noomi Rapace, Logan Marshall-Green, Michael Fa… | 2012 | 124 | 7.0 | 485820 | 126.46 | 65.0 |
| Split | 3 | Horror,Thriller | Three girls are kidnapped by a man with a diag… | M. Night Shyamalan | James McAvoy, Anya Taylor-Joy, Haley Lu Richar… | 2016 | 117 | 7.3 | 157606 | 138.12 | 62.0 |
| Sing | 4 | Animation,Comedy,Family | In a city of humanoid animals, a hustling thea… | Christophe Lourdelet | Matthew McConaughey,Reese Witherspoon, Seth Ma… | 2016 | 108 | 7.2 | 60545 | 270.32 | 59.0 |
| Suicide Squad | 5 | Action,Adventure,Fantasy | A secret government agency recruits some of th… | David Ayer | Will Smith, Jared Leto, Margot Robbie, Viola D… | 2016 | 123 | 6.2 | 393727 | 325.02 | 40.0 |
.head() по умолчанию выводит первые пять строк вашего DataFrame, но можно передать и необходимое число: например, movies_df.head(10) выведет десять верхних строк.
Чтобы увидеть последние пять строк, используйте .tail(). tail() также принимает число, и в этом случае мы выводим две нижние строки:
movies_df.tail(2)
| Rank | Genre | Description | Director | Actors | Year | Runtime (Minutes) | Rating | Votes | Revenue (Millions) | Metascore | |
| Title | |||||||||||
| Search Party | 999 | Adventure,Comedy | A pair of friends embark on a mission to reuni… | Scot Armstrong | Adam Pally, T.J. Miller, Thomas Middleditch,Sh… | 2014 | 93 | 5.6 | 4881 | NaN | 22.0 |
| Nine Lives | 1000 | Comedy,Family,Fantasy | A stuffy businessman finds himself trapped ins… | Barry Sonnenfeld | Kevin Spacey, Jennifer Garner, Robbie Amell,Ch… | 2016 | 87 | 5.3 | 12435 | 19.64 | 11.0 |
Обычно при загрузке набора данных мы просматриваем первые пять или около того строк, чтобы увидеть, что находится под капотом. Так мы видим названия каждого столбца, индекс и примеры значений в каждой строке.
Индекс в нашем DataFrame — это столбец Title. Это видно по тому, что слово Title расположено немного ниже, чем остальные столбцы.
Получение информации о ваших данных
Одной из первых команд, которые выполняются после загрузки данных, является .info():
movies_df.info()
Результат:
<class 'pandas.core.frame.DataFrame'> Index: 1000 entries, Guardians of the Galaxy to Nine Lives Data columns (total 11 columns): Rank 1000 non-null int64 Genre 1000 non-null object Description 1000 non-null object Director 1000 non-null object Actors 1000 non-null object Year 1000 non-null int64 Runtime (Minutes) 1000 non-null int64 Rating 1000 non-null float64 Votes 1000 non-null int64 Revenue (Millions) 872 non-null float64 Metascore 936 non-null float64 dtypes: float64(3), int64(4), object(4) memory usage: 93.8+ KB
.info() предоставляет основные сведения о вашем наборе данных, такие как количество строк и столбцов, количество ненулевых значений, тип данных в каждом столбце и объем памяти, используемый вашим DataFrame.
Обратите внимание, что в нашем наборе данных фильмов явно есть несколько отсутствующих значений в столбцах Revenue и Metascore. Мы рассмотрим, как их обработать.
Быстрый просмотр типа данных очень полезен. Представьте, что вы только что импортировали JSON, и целые числа были записаны как строки. Вы собираетесь произвести некоторые арифметические действия и натыкаетесь на исключение «unsupported operand», потому что производить математические операции со строками нельзя. Вызов .info() быстро покажет, что столбец, который вы считали целыми числами, на самом деле является строковым объектом.
Еще один быстрый и полезный атрибут — .shape. Он выводит просто кортеж (строки, столбцы):
movies_df.shape # Результат: # (1000, 11)
Итак, в нашем DataFrame movies есть 1000 строк и 11 столбцов. Обратите внимание, что .shape не имеет круглых скобок и является простым кортежем в формате (строки, столбцы).
Вы будете часто обращаться к .shape при очистке и преобразовании данных. Например, с его помощью можно отфильтровать некоторые строки по каким-либо критериям, а затем быстро узнать, сколько строк было удалено.
Обработка дубликатов
В этом наборе данных нет повторов, но всегда важно убедиться, что вы не агрегируете дубликаты строк.
Чтобы продемонстрировать это, давайте просто удвоим наш DataFrame movies, добавив его к самому себе:
temp_df = movies_df.append(movies_df) temp_df.shape # Результат: # (2000, 11)
Использование append() вернет копию, не затрагивая исходный DataFrame. Мы захватываем эту копию в temp, так что не будем работать с реальными данными.
Вызов .shape быстро доказывает, что строки нашего DataFrame удвоились.
Теперь мы можем попробовать отбросить дубликаты:
temp_df = temp_df.drop_duplicates() temp_df.shape # Результат: # (1000, 11)
Как и append(), метод drop_duplicates() также вернет копию вашего DataFrame, но на этот раз с удаленными дубликатами. Вызов .shape подтверждает, что мы вернулись к 1000 строкам нашего исходного набора данных.
Продолжать присваивать DataFrame одной и той же переменной, как в этом примере, немного многословно. Поэтому у pandas есть ключевое слово inplace во многих методах. Использование inplace=True изменит исходный объект DataFrame:
temp_df.drop_duplicates(inplace=True)
Теперь наш temp_df будет автоматически содержать преобразованные данные.
Еще один важный аргумент drop_duplicates() — keep, который имеет три возможных опции:
first: Отбросить дубликаты, кроме первого вхождения (опция по умолчанию).last: Отбросить дубликаты, кроме последнего вхождения.False: Отбросить все дубликаты.
Поскольку в предыдущем примере мы не определили аргумент keep, он был задан по умолчанию как first. Это означает, что если две строки одинаковы, pandas отбросит вторую и сохранит первую. Использование last имеет противоположный эффект: отбрасывается первая строка.
А вот keep=False отбрасывает все дубликаты. Если две строки одинаковы, то обе будут отброшены. Посмотрите, что произойдет с temp_df:
temp_df = movies_df.append(movies_df) # make a new copy temp_df.drop_duplicates(inplace=True, keep=False) temp_df.shape # Результат: # (0, 11)
Поскольку все строки были дубликатами, keep=False отбрасывает их все, в результате чего остается ноль строк. Если вы задаетесь вопросом, зачем это нужно, то одна из причин заключается в том, что это позволяет найти все дубликаты в наборе данных.
Очистка столбцов
Во многих случаях наборы данных содержат многословные названия столбцов с символами, словами в верхнем и нижнем регистре, пробелами и опечатками. Чтобы упростить выборку данных по имени столбца, мы можем потратить немного времени на очистку их имен.
Вот как вывести имена столбцов нашего набора данных:
movies_df.columns
Результат:
Index(['Rank', 'Genre', 'Description', 'Director', 'Actors', 'Year',
'Runtime (Minutes)', 'Rating', 'Votes', 'Revenue (Millions)',
'Metascore'],
dtype='object')
Функция .columns пригодится не только для переименования столбцов, но и в том случае, если вам нужно понять, почему вы получаете ошибку Key Error при выборе данных по столбцам.
Мы можем использовать метод .rename() для переименования определенных или всех столбцов с помощью словаря. Нам не нужны круглые скобки, поэтому давайте избавимся от них:
movies_df.rename(columns={
'Runtime (Minutes)': 'Runtime',
'Revenue (Millions)': 'Revenue_millions'
}, inplace=True)
movies_df.columns
Результат:
Index(['Rank', 'Genre', 'Description', 'Director', 'Actors', 'Year', 'Runtime',
'Rating', 'Votes', 'Revenue_millions', 'Metascore'],
dtype='object')
Отлично. Но что, если мы хотим перевести все названия в нижний регистр? Вместо того чтобы использовать .rename(), мы могли бы задать список названий столбцов, например, так:
movies_df.columns = ['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime',
'rating', 'votes', 'revenue_millions', 'metascore']
movies_df.columns
Результат:
Index(['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime',
'rating', 'votes', 'revenue_millions', 'metascore'],
dtype='object')
Но это слишком трудоемко. Вместо того чтобы просто переименовывать каждый столбец вручную, мы можем использовать list comprehension:
movies_df.columns = [col.lower() for col in movies_df] movies_df.columns
Результат:
Index(['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime',
'rating', 'votes', 'revenue_millions', 'metascore'],
dtype='object')
Представления списков и словарей вообще часто пригождаются при работе с pandas и данными в целом.
Если вы будете работать с набором данных в течение некоторого времени, рекомендуется использовать нижний регистр, удалить специальные символы и заменить пробелы символами подчеркивания.
Обработка отсутствующих значений
При исследовании данных вы, скорее всего, столкнетесь с отсутствующими значениями или null, которые, по сути, являются заглушками для несуществующих значений. Чаще всего вы увидите None в Python или np.nan в NumPy.
Есть два варианта работы с null:
- Избавиться от строк или столбцов с нулевыми значениями
- Заменить нулевые значения на ненулевые — метод, известный как импутация.
Давайте подсчитаем общее количество null в каждом столбце нашего набора данных. Первым шагом будет проверка того, какие ячейки в нашем DataFrame являются нулевыми:
movies_df.isnull()
| rank | genre | description | director | actors | year | runtime | rating | votes | revenue_millions | metascore | |
| Title | |||||||||||
| Guardians of the Galaxy | False | False | False | False | False | False | False | False | False | False | False |
| Prometheus | False | False | False | False | False | False | False | False | False | False | False |
| Split | False | False | False | False | False | False | False | False | False | False | False |
| Sing | False | False | False | False | False | False | False | False | False | False | False |
| Suicide Squad | False | False | False | False | False | False | False | False | False | False | False |
Обратите внимание, что isnull() возвращает DataFrame, в котором каждая ячейка либо True, либо False, в зависимости от null-статуса этой ячейки.
Чтобы посчитать количества null в каждом столбце, мы используем агрегатную функцию для суммирования:
movies_df.isnull().sum()
Результат:
rank 0 genre 0 description 0 director 0 actors 0 year 0 runtime 0 rating 0 votes 0 revenue_millions 128 metascore 64 dtype: int64
.isnull() сама по себе не очень полезна и обычно используется в сочетании с другими методами, например sum().
Теперь мы знаем, что наши данные имеют 128 отсутствующих значений для revenue_millions и 64 отсутствующих значения для metascore.
Удаление нулевых значений
Специалистам по Data Science и аналитикам регулярно приходится выбирать, стоит ли удалить или импутировать значения null. Подобное решение требует глубокого знания ваших данных и их контекста. В целом, удаление нулевых данных рекомендуется только в том случае, если у вас небольшой объем отсутствующих данных.
Удалить значения null довольно просто:
movies_df.dropna()
Эта операция удалит любую строку, содержащую хотя бы одно нулевое значение, но вернет новый DataFrame без изменения исходного. В этом методе также можно указать inplace=True.
Таким образом, в случае с нашим набором данных эта операция удалит 128 строк, где revenue_millions равно null, и 64 строки, где metascore равно null. Очевидно, что это расточительство, поскольку в других столбцах этих удаленных строк есть совершенно хорошие данные. Поэтому далее мы рассмотрим импутацию.
Помимо отбрасывания строк, вы также можете отбросить столбцы с нулевыми значениями, задав axis=1:
movies_df.dropna(axis=1)
В нашем наборе данных эта операция отбросит столбцы revenue_millions и metascore.
Зачем нужен параметр axis=1?
Не сразу понятно, откуда взялся axis и почему для того, чтобы он влиял на столбцы, нужно, чтобы он был равен 1. Чтобы разобраться просто посмотрите на вывод .shape:
movies_df.shape # Результат: # (1000, 11)
Как мы уже говорили, это кортеж, который представляет форму DataFrame, т.е. 1000 строк и 11 столбцов. Обратите внимание, что строки находятся под индексом 0 этого кортежа, а столбцы — под индексом 1. Вот почему axis=1 влияет на столбцы. Это берет свое начало в NumPy, и это отличный пример того, почему изучение NumPy стоит вашего времени.
Импутация
Импутация — это обычная техника построения признаков, используемая для сохранения ценных данных, имеющих нулевые значения.
Бывают случаи, когда отбрасывание всех строк с нулевыми значениями удаляет слишком большой кусок из вашего набора данных. В таких случаях можно заменить null другим значением, обычно средним или медианным значением этого столбца.
Давайте рассмотрим импутацию недостающих значений в столбце revenue_millions. Сначала мы выделим этот столбец в отдельную переменную:
revenue = movies_df['revenue_millions']
Использование квадратных скобок — это общий способ выборки столбцов в DataFrame.
Если вы помните, когда мы создавали DataFrame с нуля, ключи словаря стали названиями столбцов. Теперь, когда мы выбираем столбцы DataFrame, мы используем скобки точно так же, как если бы мы обращались к словарю Python.
revenue теперь содержит Series:
revenue.head()
Результат:
Title Guardians of the Galaxy 333.13 Prometheus 126.46 Split 138.12 Sing 270.32 Suicide Squad 325.02 Name: revenue_millions, dtype: float64
Немного другое форматирование, чем в DataFrame, но у нас все равно есть индекс Title.
Мы будем вводить недостающие значения выручки (revenue), используя среднее значение. Получаем его:
revenue_mean = revenue.mean() revenue_mean # Результат: # 82.95637614678897
Получив среднее значение, заполним нули с помощью функции fillna():
revenue.fillna(revenue_mean, inplace=True)
Теперь мы заменили все нули в revenue средним значением столбца. Обратите внимание, что, используя inplace=True, мы изменили исходный movies_df:
movies_df.isnull().sum()
rank 0 genre 0 description 0 director 0 actors 0 year 0 runtime 0 rating 0 votes 0 revenue_millions 0 metascore 64 dtype: int64
Замена всего столбца одним и тем же значением — это базовый пример. Было бы лучше попробовать импутацию с привязкой к жанру или режиссеру.
Например, можно найти среднее значение дохода, полученного в каждом жанре по отдельности, и импутировать нули в каждом жанре средним значением этого жанра.
Теперь давайте рассмотрим другие способы изучения набора данных.
Понимание ваших переменных
Используя describe() для всего DataFrame, мы можем получить сводку распределения непрерывных переменных:
movies_df.describe()
| rank | year | runtime | rating | votes | revenue_millions | metascore | |
| count | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1.000000e+03 | 1000.000000 | 936.000000 |
| mean | 500.500000 | 2012.783000 | 113.172000 | 6.723200 | 1.698083e+05 | 82.956376 | 58.985043 |
| std | 288.819436 | 3.205962 | 18.810908 | 0.945429 | 1.887626e+05 | 96.412043 | 17.194757 |
| min | 1.000000 | 2006.000000 | 66.000000 | 1.900000 | 6.100000e+01 | 0.000000 | 11.000000 |
| 25% | 250.750000 | 2010.000000 | 100.000000 | 6.200000 | 3.630900e+04 | 17.442500 | 47.000000 |
| 50% | 500.500000 | 2014.000000 | 111.000000 | 6.800000 | 1.107990e+05 | 60.375000 | 59.500000 |
| 75% | 750.250000 | 2016.000000 | 123.000000 | 7.400000 | 2.399098e+05 | 99.177500 | 72.000000 |
| max | 1000.000000 | 2016.000000 | 191.000000 | 9.000000 | 1.791916e+06 | 936.630000 | 100.000000 |
Понимание того, какие числа являются непрерывными, также пригодится при выборе типа графика для визуального представления данных.
.describe() также можно использовать для категориальной переменной, чтобы получить количество строк, количество уникальных категорий, топовую категорию и ее частоту:
movies_df['genre'].describe()
count 1000 unique 207 top Action,Adventure,Sci-Fi freq 50 Name: genre, dtype: object
Это говорит нам о том, что столбец genre имеет 207 уникальных значений, а топовое значение — Action/Adventure/Sci-Fi, которое встречается 50 раз (freq).
Функция .value_counts() позволяет определить частотность всех значений в столбце:
movies_df['genre'].value_counts().head(10)
Action,Adventure,Sci-Fi 50 Drama 48 Comedy,Drama,Romance 35 Comedy 32 Drama,Romance 31 Action,Adventure,Fantasy 27 Comedy,Drama 27 Animation,Adventure,Comedy 27 Comedy,Romance 26 Crime,Drama,Thriller 24 Name: genre, dtype: int64
Отношения между непрерывными переменными
Используя метод корреляции .corr(), мы можем сгенерировать отношения между непрерывными переменными:
movies_df.corr()
| rank | year | runtime | rating | votes | revenue_millions | metascore | |
| rank | 1.000000 | -0.261605 | -0.221739 | -0.219555 | -0.283876 | -0.252996 | -0.191869 |
| year | -0.261605 | 1.000000 | -0.164900 | -0.211219 | -0.411904 | -0.117562 | -0.079305 |
| runtime | -0.221739 | -0.164900 | 1.000000 | 0.392214 | 0.407062 | 0.247834 | 0.211978 |
| rating | -0.219555 | -0.211219 | 0.392214 | 1.000000 | 0.511537 | 0.189527 | 0.631897 |
| votes | -0.283876 | -0.411904 | 0.407062 | 0.511537 | 1.000000 | 0.607941 | 0.325684 |
| revenue_millions | -0.252996 | -0.117562 | 0.247834 | 0.189527 | 0.607941 | 1.000000 | 0.133328 |
| metascore | -0.191869 | -0.079305 | 0.211978 | 0.631897 | 0.325684 | 0.133328 | 1.000000 |
Корреляционные таблицы — это числовое представление бивариантных отношений в наборе данных.
Положительные числа указывают на положительную корреляцию: одно увеличивается — и другое увеличивается. А отрицательные числа представляют обратную корреляцию: одно увеличивается — другое уменьшается. 1.0 означает идеальную корреляцию.
Итак, глядя на первую строку, первый столбец, мы видим, что rank имеет идеальную корреляцию с самим собой, что очевидно. С другой стороны, корреляция между votes и revenue_millions составляет 0.6. Уже немного интереснее.
Изучение бивариантных отношений пригождается, когда у вас есть результат или зависимая переменная, и вы хотите увидеть характеристики, которые больше всего коррелируют с увеличением или уменьшением результата. Бивариантные зависимости можно визуально представить с помощью диаграмм рассеяния.
Теперь давайте подробнее рассмотрим манипулирование DataFrames.
Срезы, выборка, извлечение DataFrame
До сих пор мы концентрировались на некоторых базовых обобщениях наших данных. Мы научились извлекать столбцы с помощью одинарных квадратных скобок и импутировать нулевые значения в столбце с помощью функции fillna(). Ниже приведены другие методы срезов, выборки и извлечения, которые вам придется использовать постоянно.
Важно отметить, что, хотя многие методы DataFrame и Series одинаковы, они имеют разные атрибуты. Поэтому вам необходимо знать, с каким типом вы работаете, иначе получите ошибки атрибутов.
Давайте сначала рассмотрим работу со столбцами.
Получение данных по столбцам
Вы уже видели, как извлечь столбец с помощью квадратных скобок. Например:
genre_col = movies_df['genre'] type(genre_col) # Результат: # pandas.core.series.Series
В результате возвращается Series. Чтобы извлечь столбец в виде DataFrame, необходимо передать список имен столбцов. В нашем случае это всего лишь один столбец:
genre_col = movies_df[['genre']] type(genre_col) # Результат: # pandas.core.frame.DataFrame
Поскольку это просто список, добавить еще одно имя столбца очень просто:
subset = movies_df[['genre', 'rating']] subset.head()
| genre | rating | |
| Title | ||
| Guardians of the Galaxy | Action,Adventure,Sci-Fi | 8.1 |
| Prometheus | Adventure,Mystery,Sci-Fi | 7.0 |
| Split | Horror,Thriller | 7.3 |
| Sing | Animation,Comedy,Family | 7.2 |
| Suicide Squad | Action,Adventure,Fantasy | 6.2 |
Теперь давайте рассмотрим получение данных по строкам.
Получение данных по строкам
Для строк у нас есть два варианта:
.loc— определяет местоположение по имени.iloc— определяет местоположение по числовому индексу.
Помните, что наш индекс — Title, поэтому для использования .loc мы передаем ему название фильма:
prom = movies_df.loc["Prometheus"] prom
rank 2 genre Adventure,Mystery,Sci-Fi description Following clues to the origin of mankind, a te... director Ridley Scott actors Noomi Rapace, Logan Marshall-Green, Michael Fa... year 2012 runtime 124 rating 7 votes 485820 revenue_millions 126.46 metascore 65 Name: Prometheus, dtype: object
С другой стороны, используя iloc, мы передаем ему числовой индекс «Prometheus»:
prom = movies_df.iloc[1]
loc и iloc можно рассматривать как аналог среза списка в Python. Чтобы это подчеркнуть, давайте сделаем выборку из несколько строк.
Как бы вы сделали это со списком? В Python мы указываем индексы начала и конца среза в квадратных скобках, например example_list[1:4]. В pandas это работает точно так же:
movie_subset = movies_df.loc['Prometheus':'Sing'] movie_subset = movies_df.iloc[1:4] movie_subset
| rank | genre | description | director | actors | year | runtime | rating | votes | revenue_millions | metascore | |
| Title | |||||||||||
| Prometheus | 2 | Adventure,Mystery,Sci-Fi | Following clues to the origin of mankind, a te… | Ridley Scott | Noomi Rapace, Logan Marshall-Green, Michael Fa… | 2012 | 124 | 7.0 | 485820 | 126.46 | 65.0 |
| Split | 3 | Horror,Thriller | Three girls are kidnapped by a man with a diag… | M. Night Shyamalan | James McAvoy, Anya Taylor-Joy, Haley Lu Richar… | 2016 | 117 | 7.3 | 157606 | 138.12 | 62.0 |
| Sing | 4 | Animation,Comedy,Family | In a city of humanoid animals, a hustling thea… | Christophe Lourdelet | Matthew McConaughey,Reese Witherspoon, Seth Ma… | 2016 | 108 | 7.2 | 60545 | 270.32 | 59.0 |
Одно важное различие между использованием .loc и .iloc для выбора нескольких строк заключается в том, что movies_df.loc['Prometheus':'Sing'] включает фильм Sing в результат, а при использовании movies_df.iloc[1:4] фильм с индексом 4 («Suicide Squad») в результат не включен.
Срез, сделанный с помощью .iloc, подчиняется тем же правилам, что и срезы списков: элемент с индексом, указанным как конечный, не включается.
Выборка по условиям
Мы рассмотрели, как выбирать столбцы и строки, но что, если мы хотим сделать выборку по какому-нибудь условию?
Допустим, мы хотим отфильтровать наш DataFrame movies, чтобы показать только фильмы режиссера Ридли Скотта или фильмы с рейтингом больше или равным 8.0.
Для этого мы берем столбец из DataFrame и применяем к нему булево условие. Вот пример булева условия:
condition = (movies_df['director'] == "Ridley Scott") condition.head()
Title Guardians of the Galaxy False Prometheus True Split False Sing False Suicide Squad False Name: director, dtype: bool
Подобно isnull(), это возвращает Series из значений True и False. True — для фильмов, режиссером которых является Ридли Скотт, и False для остальных.
Мы хотим отфильтровать все фильмы, режиссером которых не был Ридли Скотт, т.е., нам не нужны «False-фильмы». Чтобы вернуть строки, в которых это условие равно True, мы должны передать эту операцию в DataFrame:
movies_df[movies_df['director'] == "Ridley Scott"]
| rank | genre | description | director | actors | year | runtime | rating | votes | revenue_millions | metascore | rating_category | |
| Title | ||||||||||||
| Prometheus | 2 | Adventure,Mystery,Sci-Fi | Following clues to the origin of mankind, a te… | Ridley Scott | Noomi Rapace, Logan Marshall-Green, Michael Fa… | 2012 | 124 | 7.0 | 485820 | 126.46 | 65.0 | bad |
| The Martian | 103 | Adventure,Drama,Sci-Fi | An astronaut becomes stranded on Mars after hi… | Ridley Scott | Matt Damon, Jessica Chastain, Kristen Wiig, Ka… | 2015 | 144 | 8.0 | 556097 | 228.43 | 80.0 | good |
| Robin Hood | 388 | Action,Adventure,Drama | In 12th century England, Robin and his band of… | Ridley Scott | Russell Crowe, Cate Blanchett, Matthew Macfady… | 2010 | 140 | 6.7 | 221117 | 105.22 | 53.0 | bad |
| American Gangster | 471 | Biography,Crime,Drama | In 1970s America, a detective works to bring d… | Ridley Scott | Denzel Washington, Russell Crowe, Chiwetel Eji… | 2007 | 157 | 7.8 | 337835 | 130.13 | 76.0 | bad |
| Exodus: Gods and Kings | 517 | Action,Adventure,Drama | The defiant leader Moses rises up against the … | Ridley Scott | Christian Bale, Joel Edgerton, Ben Kingsley, S… | 2014 | 150 | 6.0 | 137299 | 65.01 | 52.0 | bad |
Вы можете привыкнуть к этим условиям, читая их как:
Select movies_df where movies_df director equals Ridley Scott.
Давайте посмотрим на условную выборку с использованием числовых значений, отфильтровав DataFrame по рейтингам:
movies_df[movies_df['rating'] >= 8.6].head(3)
| rank | genre | description | director | actors | year | runtime | rating | votes | revenue_millions | metascore | |
| Title | |||||||||||
| Interstellar | 37 | Adventure,Drama,Sci-Fi | A team of explorers travel through a wormhole … | Christopher Nolan | Matthew McConaughey, Anne Hathaway, Jessica Ch… | 2014 | 169 | 8.6 | 1047747 | 187.99 | 74.0 |
| The Dark Knight | 55 | Action,Crime,Drama | When the menace known as the Joker wreaks havo… | Christopher Nolan | Christian Bale, Heath Ledger, Aaron Eckhart,Mi… | 2008 | 152 | 9.0 | 1791916 | 533.32 | 82.0 |
| Inception | 81 | Action,Adventure,Sci-Fi | A thief, who steals corporate secrets through … | Christopher Nolan | Leonardo DiCaprio, Joseph Gordon-Levitt, Ellen… | 2010 | 148 | 8.8 | 1583625 | 292.57 | 74.0 |
Мы можем сделать более сложные условия, используя логические операторы | для «или» и & для «и».
Давайте отфильтруем DataFrame, чтобы показать только фильмы Кристофера Нолана ИЛИ Ридли Скотта:
movies_df[(movies_df['director'] == 'Christopher Nolan') | (movies_df['director'] == 'Ridley Scott')].head()
| rank | genre | description | director | actors | year | runtime | rating | votes | revenue_millions | metascore | |
| Title | |||||||||||
| Prometheus | 2 | Adventure,Mystery,Sci-Fi | Following clues to the origin of mankind, a te… | Ridley Scott | Noomi Rapace, Logan Marshall-Green, Michael Fa… | 2012 | 124 | 7.0 | 485820 | 126.46 | 65.0 |
| Interstellar | 37 | Adventure,Drama,Sci-Fi | A team of explorers travel through a wormhole … | Christopher Nolan | Matthew McConaughey, Anne Hathaway, Jessica Ch… | 2014 | 169 | 8.6 | 1047747 | 187.99 | 74.0 |
| The Dark Knight | 55 | Action,Crime,Drama | When the menace known as the Joker wreaks havo… | Christopher Nolan | Christian Bale, Heath Ledger, Aaron Eckhart,Mi… | 2008 | 152 | 9.0 | 1791916 | 533.32 | 82.0 |
| The Prestige | 65 | Drama,Mystery,Sci-Fi | Two stage magicians engage in competitive one-… | Christopher Nolan | Christian Bale, Hugh Jackman, Scarlett Johanss… | 2006 | 130 | 8.5 | 913152 | 53.08 | 66.0 |
| Inception | 81 | Action,Adventure,Sci-Fi | A thief, who steals corporate secrets through … | Christopher Nolan | Leonardo DiCaprio, Joseph Gordon-Levitt, Ellen… | 2010 | 148 | 8.8 | 1583625 | 292.57 | 74.0 |
Нам нужно обязательно группировать части условия при помощи круглых скобок, чтобы Python знал, как оценивать условие в целом.
Используя метод isin(), мы могли бы сделать это более лаконично:
movies_df[movies_df['director'].isin(['Christopher Nolan', 'Ridley Scott'])].head()
Результат получим тот же.
Допустим, нам нужны все фильмы, которые были выпущены в период с 2005 по 2010 год, имеют рейтинг выше 8.0, но доходность которых меньше 25-го процентиля.
Вот как мы могли бы все это сделать:
movies_df[
((movies_df['year'] >= 2005) & (movies_df['year'] <= 2010))
& (movies_df['rating'] > 8.0)
& (movies_df['revenue_millions'] < movies_df['revenue_millions'].quantile(0.25))
]
| rank | genre | description | director | actors | year | runtime | rating | votes | revenue_millions | metascore | |
| Title | |||||||||||
| 3 Idiots | 431 | Comedy,Drama | Two friends are searching for their long lost … | Rajkumar Hirani | Aamir Khan, Madhavan, Mona Singh, Sharman Joshi | 2009 | 170 | 8.4 | 238789 | 6.52 | 67.0 |
| The Lives of Others | 477 | Drama,Thriller | In 1984 East Berlin, an agent of the secret po… | Florian Henckel von Donnersmarck | Ulrich Mühe, Martina Gedeck,Sebastian Koch, Ul… | 2006 | 137 | 8.5 | 278103 | 11.28 | 89.0 |
| Incendies | 714 | Drama,Mystery,War | Twins journey to the Middle East to discover t… | Denis Villeneuve | Lubna Azabal, Mélissa Désormeaux-Poulin, Maxim… | 2010 | 131 | 8.2 | 92863 | 6.86 | 80.0 |
| Taare Zameen Par | 992 | Drama,Family,Music | An eight-year-old boy is thought to be a lazy … | Aamir Khan | Darsheel Safary, Aamir Khan, Tanay Chheda, Sac… | 2007 | 165 | 8.5 | 102697 | 1.20 | 42.0 |
Если вы помните, когда мы использовали .describe(), 25-й процентиль по выручке (revenue) составлял примерно 17.4, и мы можем получить доступ к этому значению напрямую, используя метод quantile() с плавающим значением 0.25.
Итак, здесь у нас есть только четыре фильма, которые соответствуют этому критерию.
Применение функций
DataFrame или Series можно итерировать, как списки, но это очень медленно — особенно для больших наборов данных.
Эффективной альтернативой является применение функции к набору данных. Например, мы можем создать дополнительный столбец, где у каждого фильма будет оценка его рейтинга: «good» или «bad». Оценку «good» получит рейтинг 8.0 или выше.
Сначала мы создадим функцию, которая, получив рейтинг, определит, хороший он или плохой:
def rating_function(x):
if x >= 8.0:
return "good"
else:
return "bad"
Теперь мы хотим применить эту функцию ко всему столбцу рейтинга. Это делается при помощи метода apply():
movies_df["rating_category"] = movies_df["rating"].apply(rating_function) movies_df.head(2)
| rank | genre | description | director | actors | year | runtime | rating | votes | revenue_millions | metascore | rating_category | |
| Title | ||||||||||||
| Guardians of the Galaxy | 1 | Action,Adventure,Sci-Fi | A group of intergalactic criminals are forced … | James Gunn | Chris Pratt, Vin Diesel, Bradley Cooper, Zoe S… | 2014 | 121 | 8.1 | 757074 | 333.13 | 76.0 | good |
| Prometheus | 2 | Adventure,Mystery,Sci-Fi | Following clues to the origin of mankind, a te… | Ridley Scott | Noomi Rapace, Logan Marshall-Green, Michael Fa… | 2012 | 124 | 7.0 | 485820 | 126.46 | 65.0 | bad |
Метод .apply() пропускает каждое значение в столбце rating через rating_function и затем возвращает новый Series. Затем этот Series присваивается новому столбцу под названием rating_category.
Вы также можете использовать анонимные функции. Эта лямбда-функция дает тот же результат, что и функция rating_function:
movies_df["rating_category"] = movies_df["rating"].apply(lambda x: 'good' if x >= 8.0 else 'bad') movies_df.head(2)
В целом, использование apply() будет намного быстрее, чем итерация по строкам вручную, поскольку pandas использует векторизацию.
Хорошим примером использования функции apply() является обработка естественного языка (NLP). Вам нужно будет применять всевозможные функции очистки текста к строкам, чтобы подготовить их к машинному обучению.
Кратко о графиках
Еще одна замечательная особенность pandas — интеграция с Matplotlib. Благодаря ей вы получаете возможность строить графики непосредственно на основе DataFrames и Series. Для начала нам нужно импортировать Matplotlib (pip install matplotlib):
import matplotlib.pyplot as plt
plt.rcParams.update({'font.size': 20, 'figure.figsize': (10, 8)}) # set font and plot size
Теперь мы можем начинать. Мы не будем сильно углубляться в построение графиков, но информации будет достаточно для легкого изучения ваших данных.
Совет по построению графиков
Для категориальных переменных используйте столбчатые диаграммы* и ящики с усами.
Для непрерывных переменных используйте гистограммы, диаграммы рассеяния, линейные графики и ящики с усами.
Давайте построим график зависимости между рейтингами и доходностью. Все, что нам нужно сделать, это вызвать .plot() для movies_df с некоторой информацией о том, как построить график:
movies_df.plot(kind='scatter', x='rating', y='revenue_millions', title='Revenue (millions) vs Rating');
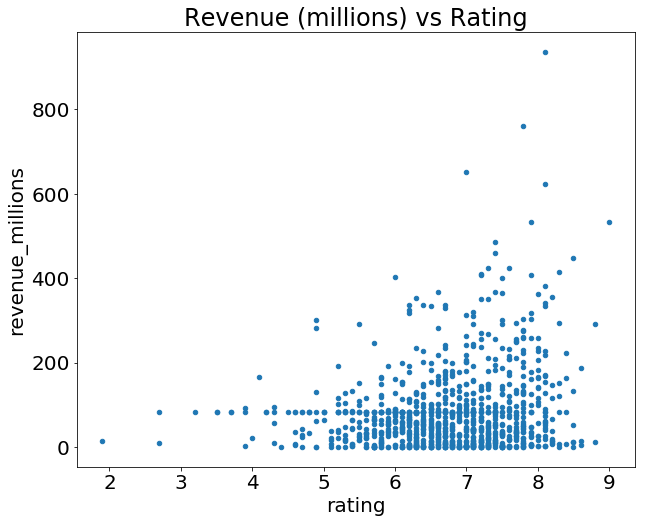
Что это за точка с запятой? Это не синтаксическая ошибка, а способ скрыть вывод <matplotlib.axes._subplots.AxesSubplot at 0x26613b5cc18> при построении графиков в Jupyter Notebook.
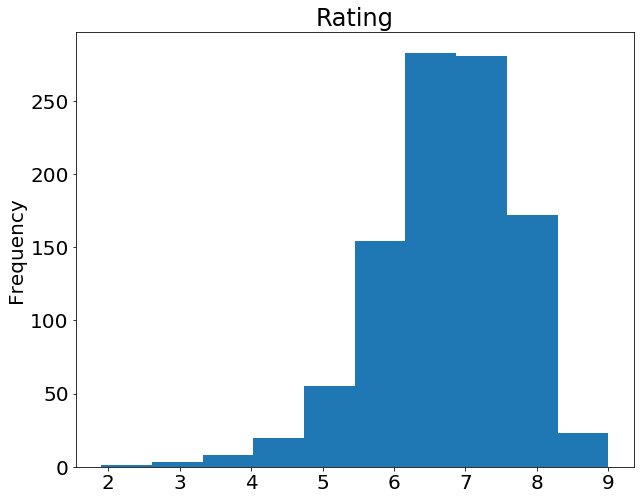
Если мы хотим построить простую гистограмму на основе одного столбца, мы можем вызвать plot для столбца:
movies_df['rating'].plot(kind='hist', title='Rating');
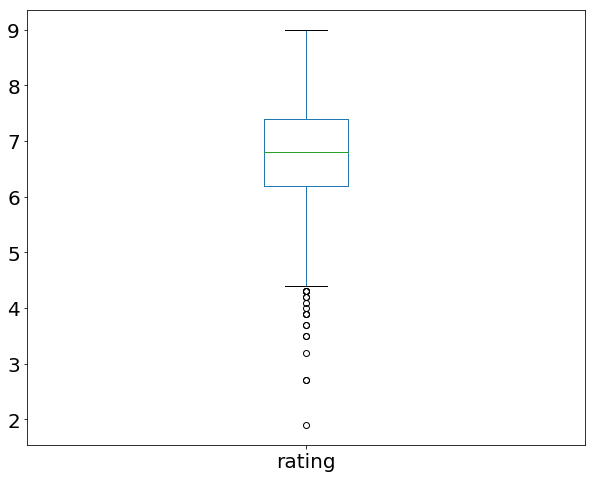
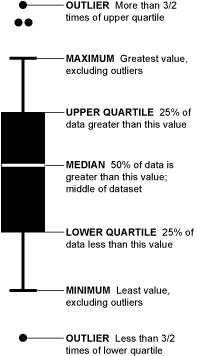
Помните пример использования .describe() в начале этого руководства? Так вот, там есть графическое представление межквартильного интервала, которое называется ящик с усами (или усиковая диаграмма). Давайте вспомним, что дает нам describe() применительно к столбцу рейтингов:
movies_df['rating'].describe()
count 1000.000000 mean 6.723200 std 0.945429 min 1.900000 25% 6.200000 50% 6.800000 75% 7.400000 max 9.000000 Name: rating, dtype: float64
Мы можем визуализировать эти данные с помощью усиковой диаграммы:
movies_df['rating'].plot(kind="box");
Объединив категориальные и непрерывные данные, можно создать усиковую диаграмму доходности с группировкой по оценке рейтинга:
movies_df.boxplot(column='revenue_millions', by='rating_category');
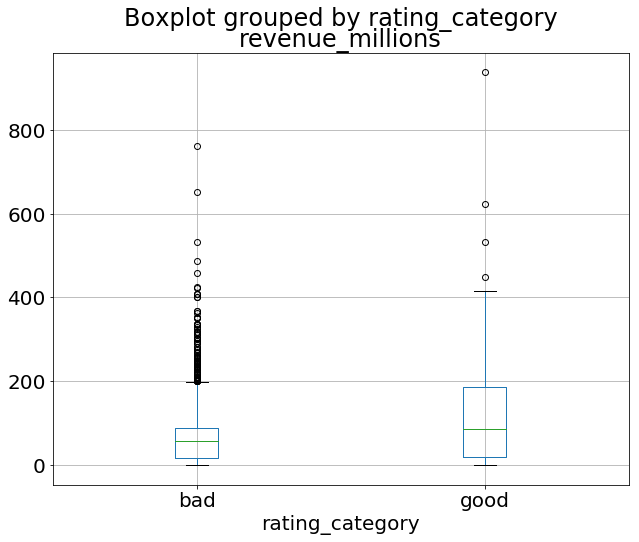
Такова общая идея построения графиков с помощью pandas. Существует слишком много графиков, в этой статье все не разберешь. Поэтому обязательно почитайте документацию по plot() для получения дополнительной информации.
Итоги
Исследование, очистка, преобразование и визуализация данных с помощью pandas в Python — это важный навык в науке о данных. Просто очистка и преобразование данных — это 80% работы датасайентиста. После нескольких проектов и некоторой практики вы будете хорошо владеть большей частью основ.
Чтобы продолжать совершенствоваться, почитайте подробные руководства, предлагаемые официальной документацией pandas, пройдите несколько Kaggle kernels и продолжайте работать над собственными проектами!
Перевод статьи George McIntire, Brendan Martin и Lauren Washington «Python Pandas Tutorial: A Complete Introduction for Beginners».
